



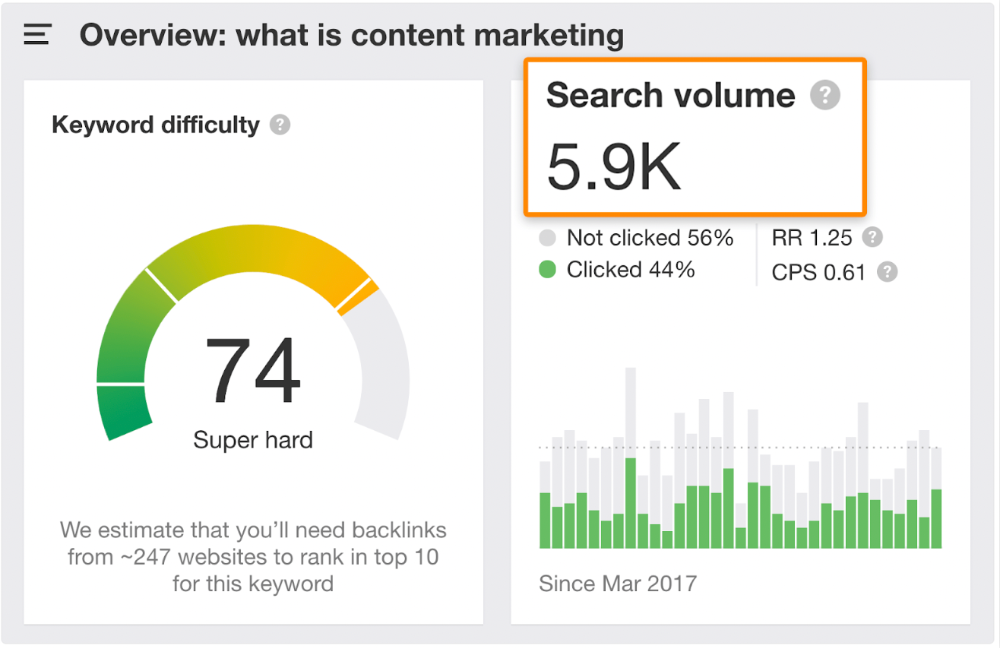
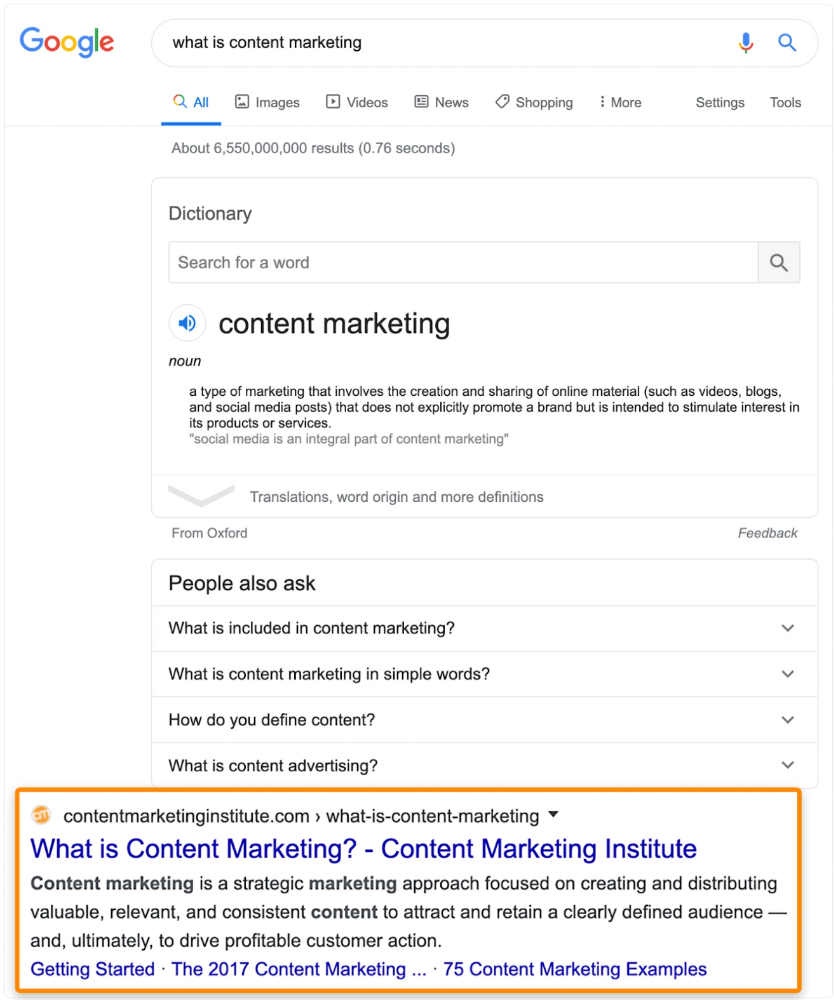
More on Technology

Ossiana Tepfenhart
3 years ago
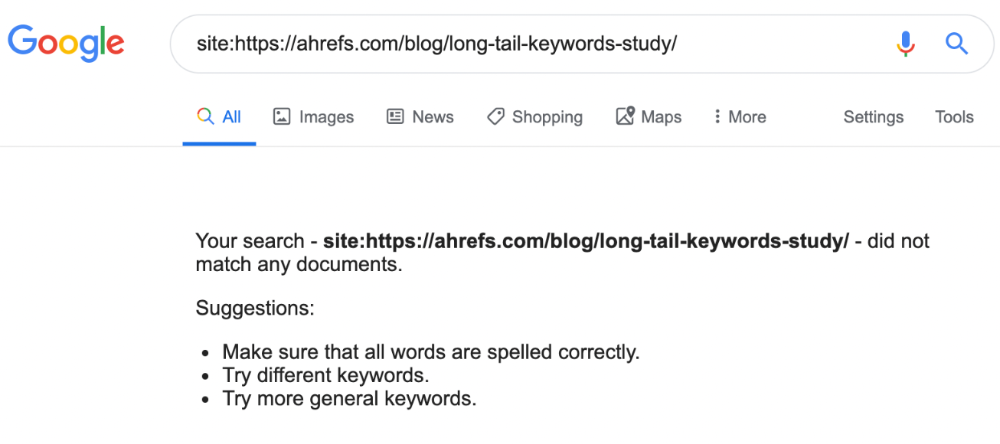
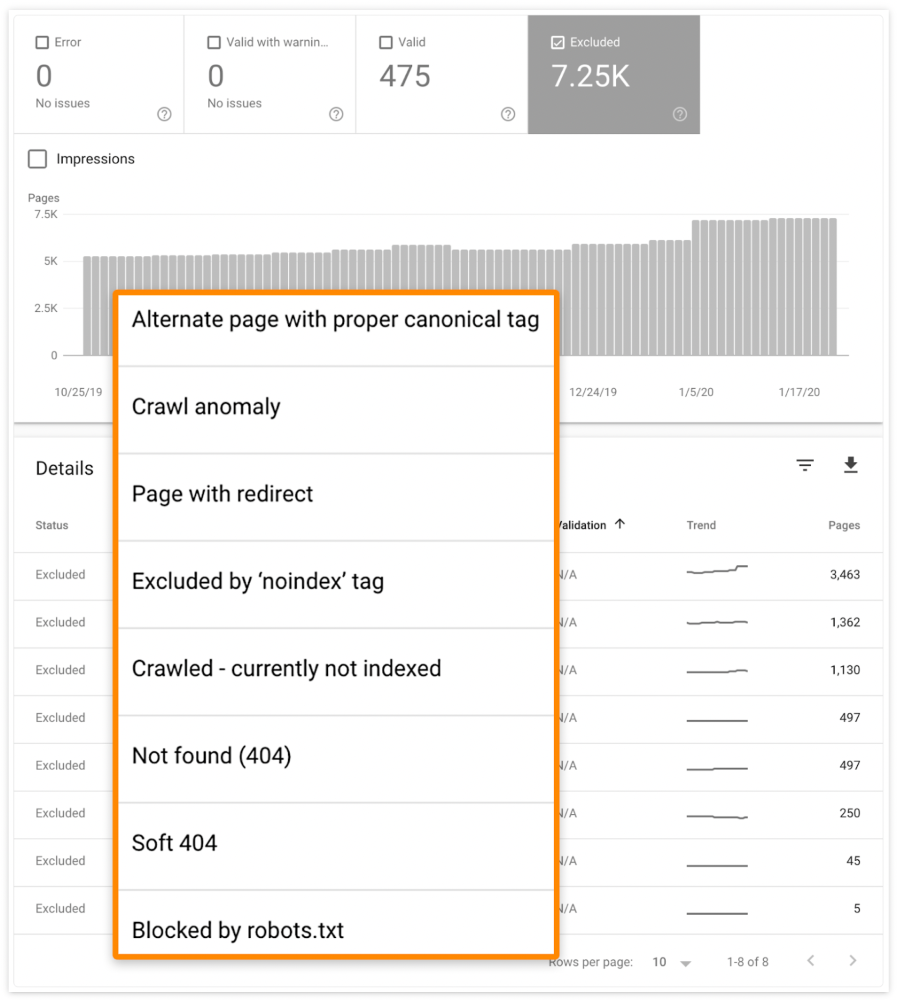
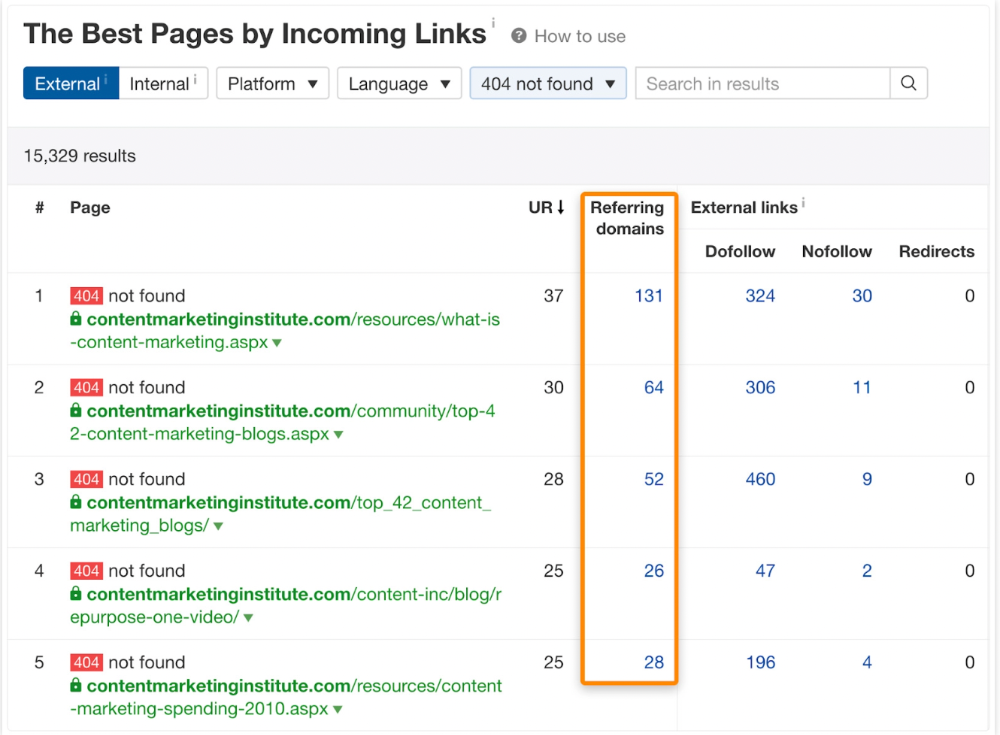
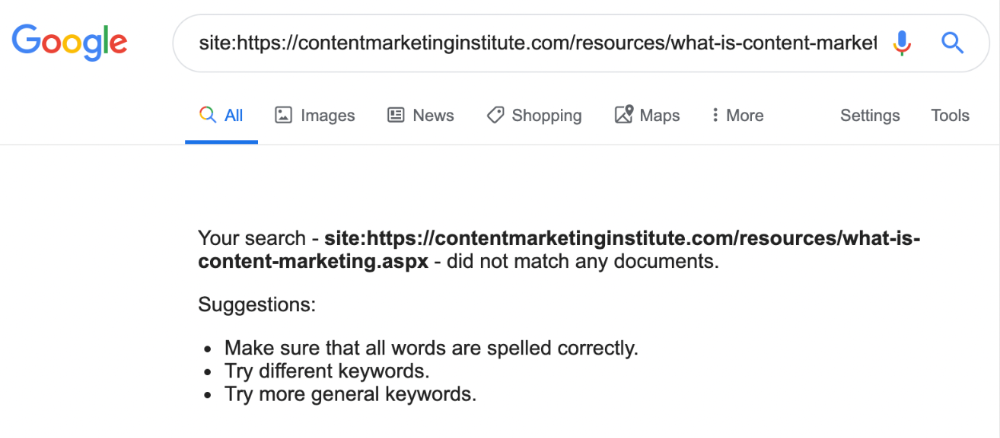
Has anyone noticed what an absolute shitshow LinkedIn is?
After viewing its insanity, I had to leave this platform.

I joined LinkedIn recently. That's how I aim to increase my readership and gain recognition. LinkedIn's premise appealed to me: a Facebook-like platform for professional networking.
I don't use Facebook since it's full of propaganda. It seems like a professional, apolitical space, right?
I expected people to:
be more formal and respectful than on Facebook.
Talk about the inclusiveness of the workplace. Studies consistently demonstrate that inclusive, progressive workplaces outperform those that adhere to established practices.
Talk about business in their industry. Yep. I wanted to read articles with advice on how to write better and reach a wider audience.
Oh, sh*t. I hadn't anticipated that.

After posting and reading about inclusivity and pro-choice, I was startled by how many professionals acted unprofessionally. I've seen:
Men have approached me in the DMs in a really aggressive manner. Yikes. huge yikes Not at all professional.
I've heard pro-choice women referred to as infant killers by many people. If I were the CEO of a company and I witnessed one of my employees acting that poorly, I would immediately fire them.
Many posts are anti-LGBTQIA+, as I've noticed. a lot, like, a lot. Some are subtly stating that the world doesn't need to know, while others are openly making fun of transgender persons like myself.
Several medical professionals were posting explicitly racist comments. Even if you are as white as a sheet like me, you should be alarmed by this. Who's to guarantee a patient who is black won't unintentionally die?
I won't even get into how many men in STEM I observed pushing for the exclusion of women from their fields. I shouldn't be surprised considering the majority of those men I've encountered have a passionate dislike for women, but goddamn, dude.
Many people appear entirely too at ease displaying their bigotry on their professional profiles.

As a white female, I'm always shocked by people's open hostility. Professional environments are very important.
I don't know if this is still true (people seem too politicized to care), but if I heard many of these statements in person, I'd suppose they feel ashamed. Really.
Are you not ashamed of being so mean? Are you so weak that competing with others terrifies you? Isn't this embarrassing?
LinkedIn isn't great at censoring offensive comments. These people aren't getting warnings. So they were safe while others were unsafe.
The CEO in me would want to know if I had placed a bigot on my staff.

I always wondered if people's employers knew about their online behavior. If they know how horrible they appear, they don't care.
As a manager, I was picky about hiring. Obviously. In most industries, it costs $1,000 or more to hire a full-time employee, so be sure it pays off.
Companies that embrace diversity and tolerance (and are intolerant of intolerance) are more profitable, likely to recruit top personnel, and successful.
People avoid businesses that alienate them. That's why I don't eat at Chic-Fil-A and why folks avoid MyPillow. Being inclusive is good business.
CEOs are harmed by online bigots. Image is an issue. If you're a business owner, you can fire staff who don't help you.
On the one hand, I'm delighted it makes it simpler to identify those with whom not to do business.

Don’t get me wrong. I'm glad I know who to avoid when hiring, getting references, or searching for a job. When people are bad, it saves me time.
What's up with professionalism?
Really. I need to know. I've crossed the boundary between acceptable and unacceptable behavior, but never on a professional platform. I got in trouble for not wearing bras even though it's not part of my gender expression.
If I behaved like that at my last two office jobs, my supervisors would have fired me immediately. Some of the behavior I've seen is so outrageous, I can't believe these people have employment. Some are even leaders.
Like…how? Is hatred now normalized?
Please pay attention whether you're seeking for a job or even simply a side gig.

Do not add to the tragedy that LinkedIn comments can be, or at least don't make uninformed comments. Even if you weren't banned, the site may still bite you.
Recruiters can and do look at your activity. Your writing goes on your résumé. The wrong comment might lose you a job.
Recruiters and CEOs might reject candidates whose principles contradict with their corporate culture. Bigotry will get you banned from many companies, especially if others report you.
If you want a high-paying job, avoid being a LinkedIn asshole. People care even if you think no one does. Before speaking, ponder. Is this how you want to be perceived?
Better advice:
If your politics might turn off an employer, stop posting about them online and ask yourself why you hold such objectionable ideas.

The Mystique
3 years ago
Four Shocking Dark Web Incidents that Should Make You Avoid It
Dark Web activity? Is it as horrible as they say?

We peruse our phones for hours. Internet has improved our worldview.
However, the world's harshest realities remain buried on the internet and unattainable by everyone.
Browsers cannot access the Dark Web. Browse it with high-security authentication and exclusive access. There are compelling reasons to avoid the dark web at all costs.
1. The Dark Web and I

Darius wrote My Dark Web Story on reddit two years ago. The user claimed to have shared his dark web experience. DaRealEddyYT wanted to surf the dark web after hearing several stories.
He curiously downloaded Tor Browser, which provides anonymity and security.
In the Dark Room, bound
As Darius logged in, a text popped up: “Want a surprise? Click on this link.”
The link opened to a room with a chair. Only one light source illuminated the room. The chair held a female tied.
As the screen read "Let the game begin," a man entered the room and was paid in bitcoins to torment the girl.
The man dragged and tortured the woman.
A danger to safety
Leaving so soon, Darius, disgusted Darius tried to leave the stream. The anonymous user then sent Darius his personal information, including his address, which frightened him because he didn't know Tor was insecure.
After deleting the app, his phone camera was compromised.
He also stated that he left his residence and returned to find it unlocked and a letter saying, Thought we wouldn't find you? Reddit never updated the story.
The story may have been a fake, but a much scarier true story about the dark side of the internet exists.
2. The Silk Road Market

The dark web is restricted for a reason. The dark web has everything illicit imaginable. It's awful central.
The dark web has everything, from organ sales to drug trafficking to money laundering to human trafficking. Illegal drugs, pirated software, credit card, bank, and personal information can be found in seconds.
The dark web has reserved websites like Google. The Silk Road Website, which operated from 2011 to 2013, was a leading digital black market.
The FBI grew obsessed with site founder and processor Ross William Ulbricht.
The site became a criminal organization as money laundering and black enterprises increased. Bitcoin was utilized for credit card payment.
The FBI was close to arresting the site's administrator. Ross was detained after the agency closed Silk Road in 2013.
Two years later, in 2015, he was convicted and sentenced to two consecutive life terms and forty years. He appealed in 2016 but was denied, thus he is currently serving time.
The hefty sentence was for more than running a black marketing site. He was also convicted of murder-for-hire, earning about $730,000 in a short time.
3. Person-buying auctions

Bidding on individuals is another weird internet activity. After a Milan photo shoot, 20-year-old British model Chloe Ayling was kidnapped.
An ad agency in Milan made a bogus offer to shoot with the mother of a two-year-old boy. Four men gave her anesthetic and put her in a duffel bag when she arrived.
She was held captive for several days, and her images and $300,000 price were posted on the dark web. Black Death Trafficking Group kidnapped her to sell her for sex.
She was told two black death foot warriors abducted her. The captors released her when they found she was a mother because mothers were less desirable to sex slave buyers.
In July 2018, Lukasz Pawel Herba was arrested and sentenced to 16 years and nine months in prison. Being a young mother saved Chloe from creepy bidding.
However, it exceeds expectations of how many more would be in such danger daily without their knowledge.
4. Organ sales

Many are unaware of dark web organ sales. Patients who cannot acquire organs often turn to dark web brokers.
Brokers handle all transactions between donors and customers.
Bitcoins are used for dark web transactions, and the Tor server permits personal data on the web.
The WHO reports approximately 10,000 unlawful organ transplants annually. The black web sells kidneys, hearts, even eyes.
To protect our lives and privacy, we should manage our curiosity and never look up dangerous stuff.
While it's fascinating and appealing to know what's going on in the world we don't know about, it's best to prioritize our well-being because one never knows how bad it might get.
Sources

VIP Graphics
3 years ago
Leaked pitch deck for Metas' new influencer-focused live-streaming service
As part of Meta's endeavor to establish an interactive live-streaming platform, the company is testing with influencers.
The NPE (new product experimentation team) has been testing Super since late 2020.

Bloomberg defined Super as a Cameo-inspired FaceTime-like gadget in 2020. The tool has evolved into a Twitch-like live streaming application.
Less than 100 creators have utilized Super: Creators can request access on Meta's website. Super isn't an Instagram, Facebook, or Meta extension.
“It’s a standalone project,” the spokesperson said about Super. “Right now, it’s web only. They have been testing it very quietly for about two years. The end goal [of NPE projects] is ultimately creating the next standalone project that could be part of the Meta family of products.” The spokesperson said the outreach this week was part of a drive to get more creators to test Super.
A 2021 pitch deck from Super reveals the inner workings of Meta.
The deck gathered feedback on possible sponsorship models, with mockups of brand deals & features. Meta reportedly paid creators $200 to $3,000 to test Super for 30 minutes.
Meta's pitch deck for Super live streaming was leaked.
What were the slides in the pitch deck for Metas Super?
Embed not supported: see full deck & article here →
View examples of Meta's pitch deck for Super:
Product Slides, first
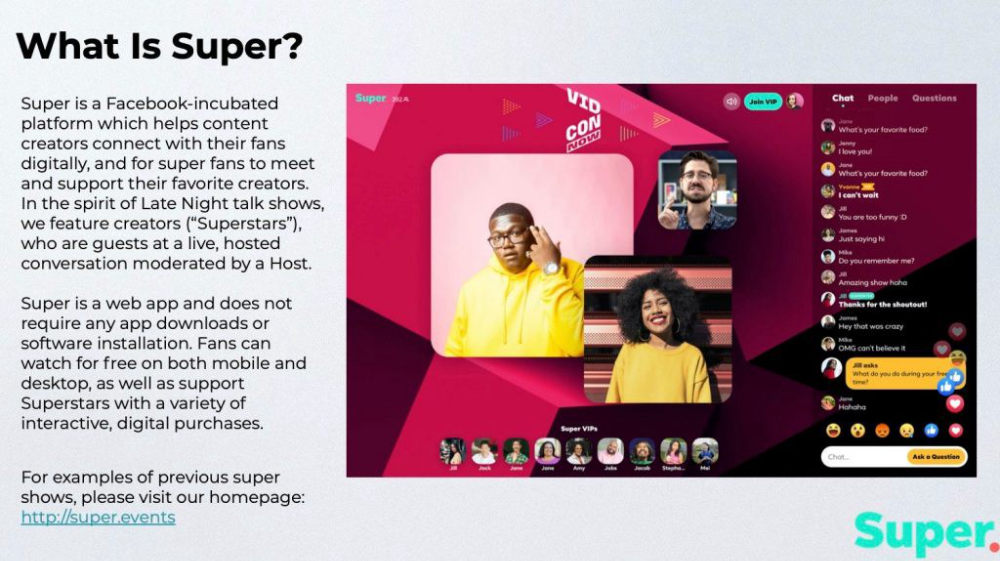
The pitch deck begins with Super's mission:
Super is a Facebook-incubated platform which helps content creators connect with their fans digitally, and for super fans to meet and support their favorite creators. In the spirit of Late Night talk shows, we feature creators (“Superstars”), who are guests at a live, hosted conversation moderated by a Host.
This slide (and most of the deck) is text-heavy, with few icons, bullets, and illustrations to break up the content. Super's online app status (which requires no download or installation) might be used as a callout (rather than paragraph-form).

Meta's Super platform focuses on brand sponsorships and native placements, as shown in the slide above.
One of our theses is the idea that creators should benefit monetarily from their Super experiences, and we believe that offering a menu of different monetization strategies will enable the right experience for each creator. Our current focus is exploring sponsorship opportunities for creators, to better understand what types of sponsor placements will facilitate the best experience for all Super customers (viewers, creators, and advertisers).
Colorful mockups help bring Metas vision for Super to life.
2. Slide Features
Super's pitch deck focuses on the platform's features. The deck covers pre-show, pre-roll, and post-event for a Sponsored Experience.
Pre-show: active 30 minutes before the show's start
Pre-roll: Play a 15-minute commercial for the sponsor before the event (auto-plays once)
Meet and Greet: This event can have a branding, such as Meet & Greet presented by [Snickers]
Super Selfies: Makers and followers get a digital souvenir to post on social media.
Post-Event: Possibility to draw viewers' attention to sponsored content/links during the after-show
Almost every screen displays the Sponsor logo, link, and/or branded background. Viewers can watch sponsor video while waiting for the event to start.
Slide 3: Business Model
Meta's presentation for Super is incomplete without numbers. Super's first slide outlines the creator, sponsor, and Super's obligations. Super does not charge creators any fees or commissions on sponsorship earnings.

How to make a great pitch deck
We hope you can use the Super pitch deck to improve your business. Bestpitchdeck.com/super-meta is a bookmarkable link.
You can also use one of our expert-designed templates to generate a pitch deck.
Our team has helped close $100M+ in agreements and funding for premier companies and VC firms. Use our presentation templates, one-pagers, or financial models to launch your pitch.
Every pitch must be audience-specific. Our team has prepared pitch decks for various sectors and fundraising phases.

Pitch Deck Software VIP.graphics produced a popular SaaS & Software Pitch Deck based on decks that closed millions in transactions & investments for orgs of all sizes, from high-growth startups to Fortune 100 enterprises. This easy-to-customize PowerPoint template includes ready-made features and key slides for your software firm.

Accelerator Pitch Deck The Accelerator Pitch Deck template is for early-stage founders seeking funding from pitch contests, accelerators, incubators, angels, or VC companies. Winning a pitch contest or getting into a top accelerator demands a strategic investor pitch.

Pitch Deck Template Series Startup and founder pitch deck template: Workable, smart slides. This pitch deck template is for companies, entrepreneurs, and founders raising seed or Series A finance.

M&A Pitch Deck Perfect Pitch Deck is a template for later-stage enterprises engaging more sophisticated conversations like M&A, late-stage investment (Series C+), or partnerships & funding. Our team prepared this presentation to help creators confidently pitch to investment banks, PE firms, and hedge funds (and vice versa).
Browse our growing variety of industry-specific pitch decks.
You might also like

Ethan Siegel
3 years ago
How you view the year will change after using this one-page calendar.

No other calendar is simpler, smaller, and reusable year after year. It works and is used here.
Most of us discard and replace our calendars annually. Each month, we move our calendar ahead another page, thus if we need to know which day of the week corresponds to a given day/month combination, we have to calculate it or flip forward/backward to the corresponding month. Questions like:
What day does this year's American Thanksgiving fall on?
Which months contain a Friday the thirteenth?
When is July 4th? What day of the week?
Alternatively, what day of the week is Christmas?
They're hard to figure out until you switch to the right month or look up all the months.
However, mathematically, the answers to these questions or any question that requires matching the day of the week with the day/month combination in a year are predictable, basic, and easy to work out. If you use this one-page calendar instead of a 12-month calendar, it lasts the whole year and is easy to alter for future years. Let me explain.
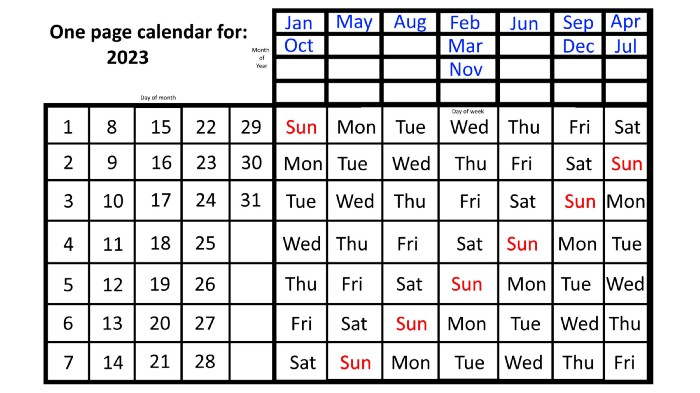
The 2023 one-page calendar is above. The days of the month are on the lower left, which works for all months if you know that:
There are 31 days in January, March, May, July, August, October, and December.
All of the months of April, June, September, and November have 30 days.
And depending on the year, February has either 28 days (in non-leap years) or 29 days (in leap years).
If you know this, this calendar makes it easy to match the day/month of the year to the weekday.
Here are some instances. American Thanksgiving is always on the fourth Thursday of November. You'll always know the month and day of the week, but the date—the day in November—changes each year.
On any other calendar, you'd have to flip to November to see when the fourth Thursday is. This one-page calendar only requires:
pick the month of November in the top-right corner to begin.
drag your finger down until Thursday appears,
then turn left and follow the monthly calendar until you reach the fourth Thursday.
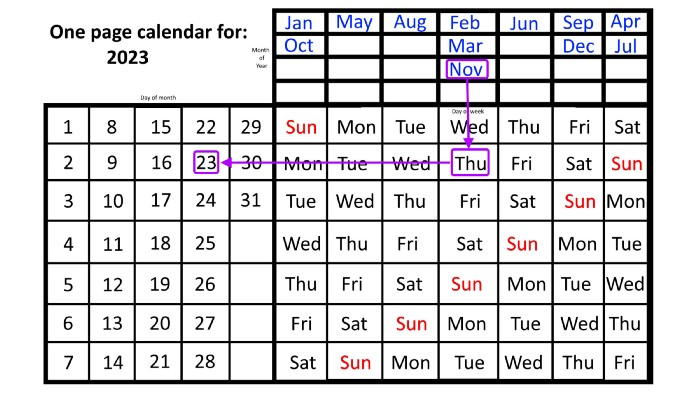
It's obvious: 2023 is the 23rd American Thanksgiving. For every month and day-of-the-week combination, start at the month, drag your finger down to the desired day, and then move to the left to see which dates match.
What if you knew the day of the week and the date of the month, but not the month(s)?
A different method using the same one-page calendar gives the answer. Which months have Friday the 13th this year? Just:
begin on the 13th of the month, the day you know you desire,
then swipe right with your finger till Friday appears.
and then work your way up until you can determine which months the specific Friday the 13th falls under.
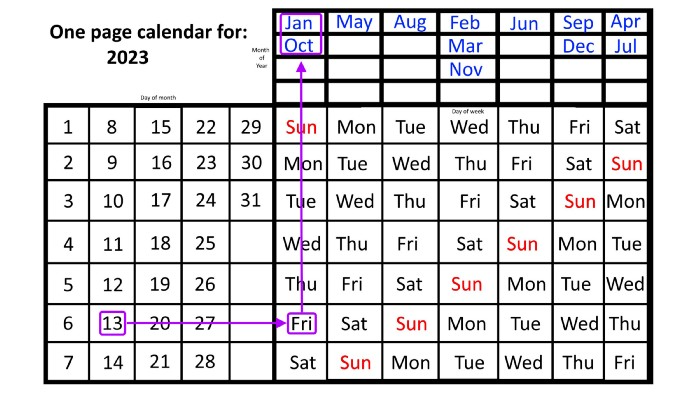
One Friday the 13th occurred in January 2023, and another will occur in October.
The most typical reason to consult a calendar is when you know the month/day combination but not the day of the week.
Compared to single-month calendars, the one-page calendar excels here. Take July 4th, for instance. Find the weekday here:
beginning on the left on the fourth of the month, as you are aware,
also begin with July, the month of the year you are most familiar with, at the upper right,
you should move your two fingers in the opposite directions till they meet: on a Tuesday in 2023.
That's how you find your selected day/month combination's weekday.
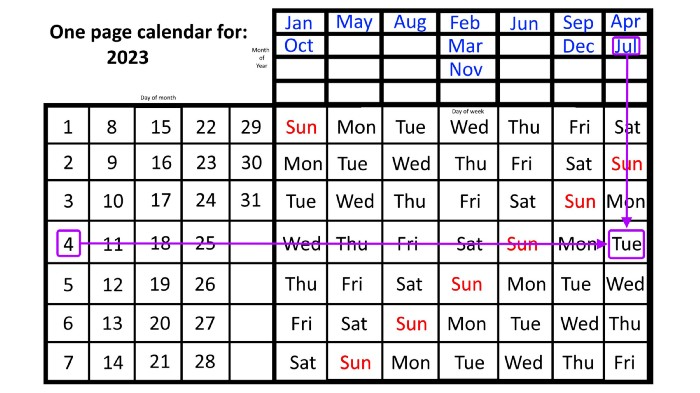
Another example: Christmas. Christmas Day is always December 25th, however unless your conventional calendar is open to December of your particular year, a question like "what day of the week is Christmas?" difficult to answer.
Unlike the one-page calendar!
Remember the left-hand day of the month. Top-right, you see the month. Put two fingers, one from each hand, on the date (25th) and the month (December). Slide the day hand to the right and the month hand downwards until they touch.
They meet on Monday—December 25, 2023.
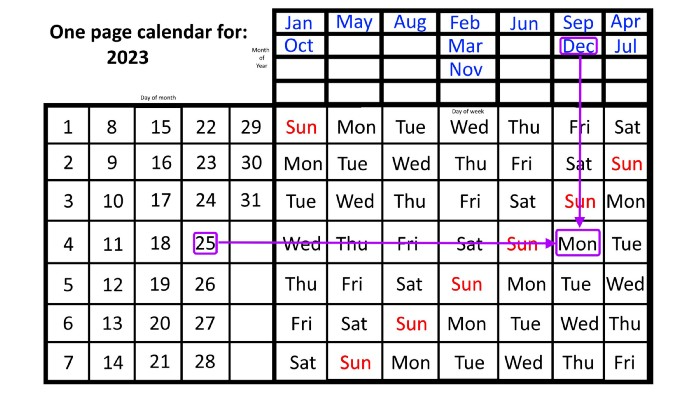
For 2023, that's fine, but what happens in 2024? Even worse, what if we want to know the day-of-the-week/day/month combo many years from now?
I think the one-page calendar shines here.
Except for the blue months in the upper-right corner of the one-page calendar, everything is the same year after year. The months also change in a consistent fashion.
Each non-leap year has 365 days—one more than a full 52 weeks (which is 364). Since January 1, 2023 began on a Sunday and 2023 has 365 days, we immediately know that December 31, 2023 will conclude on a Sunday (which you can confirm using the one-page calendar) and that January 1, 2024 will begin on a Monday. Then, reorder the months for 2024, taking in mind that February will have 29 days in a leap year.
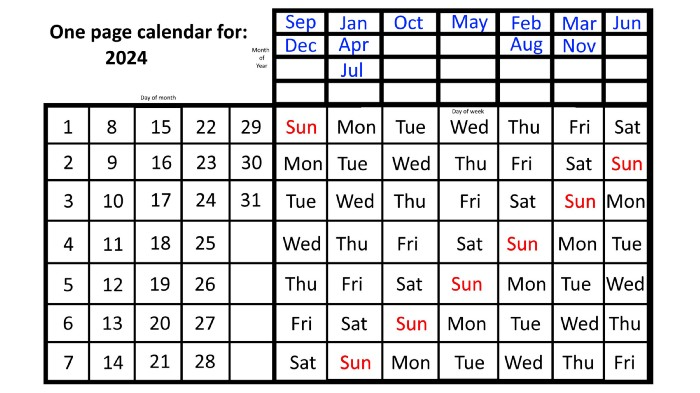
Please note the differences between 2023 and 2024 month placement. In 2023:
October and January began on the same day of the week.
On the following Monday of the week, May began.
August started on the next day,
then the next weekday marked the start of February, March, and November, respectively.
Unlike June, which starts the following weekday,
While September and December start on the following day of the week,
Lastly, April and July start one extra day later.
Since 2024 is a leap year, February has 29 days, disrupting the rhythm. Month placements change to:
The first day of the week in January, April, and July is the same.
October will begin the following day.
Possibly starting the next weekday,
February and August start on the next weekday,
beginning on the following day of the week between March and November,
beginning the following weekday in June,
and commencing one more day of the week after that, September and December.
Due to the 366-day leap year, 2025 will start two days later than 2024 on January 1st.
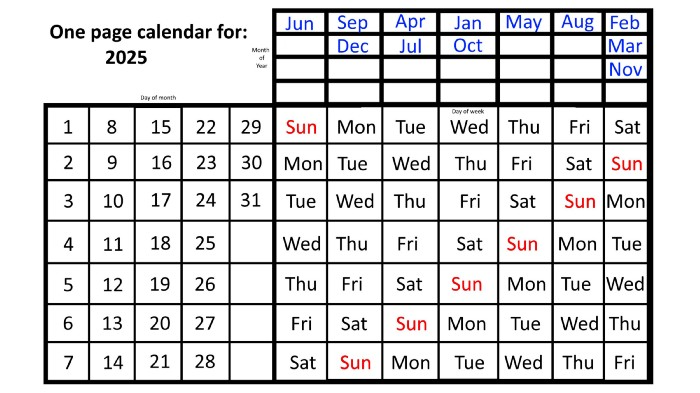
Now, looking at the 2025 calendar, you can see that the 2023 pattern of which months start on which days is repeated! The sole variation is a shift of three days-of-the-week ahead because 2023 had one more day (365) than 52 full weeks (364), and 2024 had two more days (366). Again,
On Wednesday this time, January and October begin on the same day of the week.
Although May begins on Thursday,
August begins this Friday.
March, November, and February all begin on a Saturday.
Beginning on a Sunday in June
Beginning on Monday are September and December,
and on Tuesday, April and July begin.
In 2026 and 2027, the year will commence on a Thursday and a Friday, respectively.
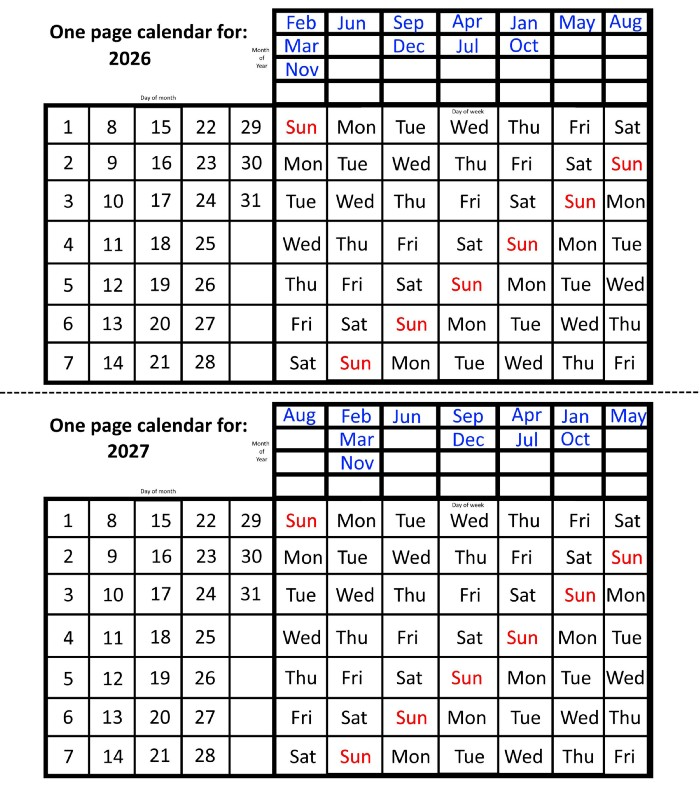
We must return to our leap year monthly arrangement in 2028. Yes, January 1, 2028 begins on a Saturday, but February, which begins on a Tuesday three days before January, will have 29 days. Thus:
Start dates for January, April, and July are all Saturdays.
Given that October began on Sunday,
Although May starts on a Monday,
beginning on a Tuesday in February and August,
Beginning on a Wednesday in March and November,
Beginning on Thursday, June
and Friday marks the start of September and December.
This is great because there are only 14 calendar configurations: one for each of the seven non-leap years where January 1st begins on each of the seven days of the week, and one for each of the seven leap years where it begins on each day of the week.
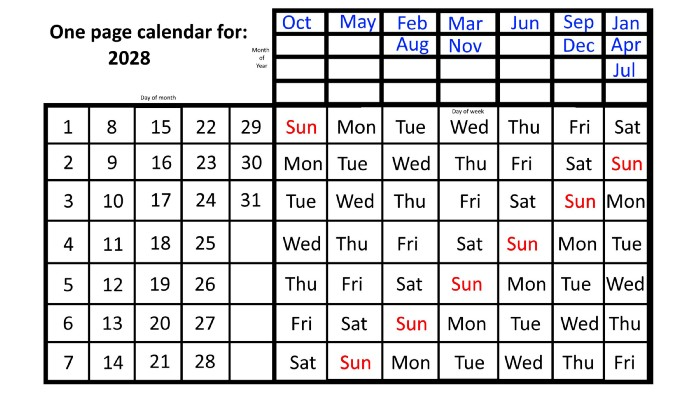
The 2023 calendar will function in 2034, 2045, 2051, 2062, 2073, 2079, 2090, 2102, 2113, and 2119. Except when passing over a non-leap year that ends in 00, like 2100, the repeat time always extends to 12 years or shortens to an extra 6 years.
The pattern is repeated in 2025's calendar in 2031, 2042, 2053, 2059, 2070, 2081, 2087, 2098, 2110, and 2121.
The extra 6-year repeat at the end of the century on the calendar for 2026 will occur in the years 2037, 2043, 2054, 2065, 2071, 2082, 2093, 2099, 2105, and 2122.
The 2027s calendar repeats in 2038, 2049, 2055, 2066, 2077, 2083, 2094, 2100, 2106, and 2117, almost exactly matching the 2026s pattern.
For leap years, the recurrence pattern is every 28 years when not passing a non-leap year ending in 00, or 12 or 40 years when we do. 2024's calendar repeats in 2052, 2080, 2120, 2148, 2176, and 2216; 2028's in 2056, 2084, 2124, 2152, 2180, and 2220.
Knowing January 1st and whether it's a leap year lets you construct a one-page calendar for any year. Try it—you might find it easier than any other alternative!

Adam Frank
3 years ago
Humanity is not even a Type 1 civilization. What might a Type 3 be capable of?

The Kardashev scale grades civilizations from Type 1 to Type 3 based on energy harvesting.
How do technologically proficient civilizations emerge across timescales measuring in the tens of thousands or even millions of years? This is a question that worries me as a researcher in the search for “technosignatures” from other civilizations on other worlds. Since it is already established that longer-lived civilizations are the ones we are most likely to detect, knowing something about their prospective evolutionary trajectories could be translated into improved search tactics. But even more than knowing what to seek for, what I really want to know is what happens to a society after so long time. What are they capable of? What do they become?
This was the question Russian SETI pioneer Nikolai Kardashev asked himself back in 1964. His answer was the now-famous “Kardashev Scale.” Kardashev was the first, although not the last, scientist to try and define the processes (or stages) of the evolution of civilizations. Today, I want to launch a series on this question. It is crucial to technosignature studies (of which our NASA team is hard at work), and it is also important for comprehending what might lay ahead for mankind if we manage to get through the bottlenecks we have now.
The Kardashev scale
Kardashev’s question can be expressed another way. What milestones in a civilization’s advancement up the ladder of technical complexity will be universal? The main notion here is that all (or at least most) civilizations will pass through some kind of definable stages as they progress, and some of these steps might be mirrored in how we could identify them. But, while Kardashev’s major focus was identifying signals from exo-civilizations, his scale gave us a clear way to think about their evolution.
The classification scheme Kardashev employed was not based on social systems of ethics because they are something that we can probably never predict about alien cultures. Instead, it was built on energy, which is something near and dear to the heart of everybody trained in physics. Energy use might offer the basis for universal stages of civilisation progression because you cannot do the work of establishing a civilization without consuming energy. So, Kardashev looked at what energy sources were accessible to civilizations as they evolved technologically and used those to build his scale.
From Kardashev’s perspective, there are three primary levels or “types” of advancement in terms of harvesting energy through which a civilization should progress.
Type 1: Civilizations that can capture all the energy resources of their native planet constitute the first stage. This would imply capturing all the light energy that falls on a world from its host star. This makes it reasonable, given solar energy will be the largest source available on most planets where life could form. For example, Earth absorbs hundreds of atomic bombs’ worth of energy from the Sun every second. That is a rather formidable energy source, and a Type 1 race would have all this power at their disposal for civilization construction.
Type 2: These civilizations can extract the whole energy resources of their home star. Nobel Prize-winning scientist Freeman Dyson famously anticipated Kardashev’s thinking on this when he imagined an advanced civilization erecting a large sphere around its star. This “Dyson Sphere” would be a machine the size of the complete solar system for gathering stellar photons and their energy.
Type 3: These super-civilizations could use all the energy produced by all the stars in their home galaxy. A normal galaxy has a few hundred billion stars, so that is a whole lot of energy. One way this may be done is if the civilization covered every star in their galaxy with Dyson spheres, but there could also be more inventive approaches.
Implications of the Kardashev scale
Climbing from Type 1 upward, we travel from the imaginable to the god-like. For example, it is not hard to envisage utilizing lots of big satellites in space to gather solar energy and then beaming that energy down to Earth via microwaves. That would get us to a Type 1 civilization. But creating a Dyson sphere would require chewing up whole planets. How long until we obtain that level of power? How would we have to change to get there? And once we get to Type 3 civilizations, we are virtually thinking about gods with the potential to engineer the entire cosmos.
For me, this is part of the point of the Kardashev scale. Its application for thinking about identifying technosignatures is crucial, but even more strong is its capacity to help us shape our imaginations. The mind might become blank staring across hundreds or thousands of millennia, and so we need tools and guides to focus our attention. That may be the only way to see what life might become — what we might become — once it arises to start out beyond the boundaries of space and time and potential.
This is a summary. Read the full article here.

Jennifer Tieu
4 years ago
Why I Love Azuki
Azuki Banner (www.azuki.com)
Disclaimer: This is my personal viewpoint. I'm not on the Azuki team. Please keep in mind that I am merely a fan, community member, and holder. Please do your own research and pardon my grammar. Thanks!
Azuki has changed my view of NFTs.
When I first entered the NFT world, I had no idea what to expect. I liked the idea. So I invested in some projects, fought for whitelists, and discovered some cool NFTs projects (shout-out to CATC). I lost more money than I earned at one point, but I hadn't invested excessively (only put in what you can afford to lose). Despite my losses, I kept looking. I almost waited for the “ah-ha” moment. A NFT project that changed my perspective on NFTs. What makes an NFT project more than a work of art?
Answer: Azuki.
The Art
The Azuki art drew me in as an anime fan. It looked like something out of an anime, and I'd never seen it before in NFT.
The project was still new. The first two animated teasers were released with little fanfare, but I was impressed with their quality. You can find them on Instagram or in their earlier Tweets.
The teasers hinted that this project could be big and that the team could deliver. It was amazing to see Shao cut the Azuki posters with her katana. Especially at the end when she sheaths her sword and the music cues. Then the live action video of the young boy arranging the Azuki posters seemed movie-like. I felt like I was entering the Azuki story, brand, and dope theme.
The team did not disappoint with the Azuki NFTs. The level of detail in the art is stunning. There were Azukis of all genders, skin and hair types, and more. These 10,000 Azukis have so much representation that almost anyone can find something that resonates. Rather than me rambling on, I suggest you visit the Azuki gallery
The Team
If the art is meant to draw you in and be the project's face, the team makes it more. The NFT would be a JPEG without a good team leader. Not that community isn't important, but no community would rally around a bad team.
Because I've been rugged before, I'm very focused on the team when considering a project. While many project teams are anonymous, I try to find ones that are doxxed (public) or at least appear to be established. Unlike Azuki, where most of the Azuki team is anonymous, Steamboy is public. He is (or was) Overwatch's character art director and co-creator of Azuki. I felt reassured and could trust the project after seeing someone from a major game series on the team.
Then I tried to learn as much as I could about the team. Following everyone on Twitter, reading their tweets, and listening to recorded AMAs. I was impressed by the team's professionalism and dedication to their vision for Azuki, led by ZZZAGABOND.
I believe the phrase “actions speak louder than words” applies to Azuki. I can think of a few examples of what the Azuki team has done, but my favorite is ERC721A.
With ERC721A, Azuki has created a new algorithm that allows minting multiple NFTs for essentially the same cost as minting one NFT.
I was ecstatic when the dev team announced it. This fascinates me as a self-taught developer. Azuki released a product that saves people money, improves the NFT space, and is open source. It showed their love for Azuki and the NFT community.
The Community
Community, community, community. It's almost a chant in the NFT space now. A community, like a team, can make or break a project. We are the project's consumers, shareholders, core, and lifeblood. The team builds the house, and we fill it. We stay for the community.
When I first entered the Azuki Discord, I was surprised by the calm atmosphere. There was no news about the project. No release date, no whitelisting requirements. No grinding or spamming either. People just wanted to hangout, get to know each other, and talk. It was nice. So the team could pick genuine people for their mintlist (aka whitelist).
But nothing fundamental has changed since the release. It has remained an authentic, fun, and helpful community. I'm constantly logging into Discord to chat with others or follow conversations. I see the community's openness to newcomers. Everyone respects each other (barring a few bad apples) and the variety of people passing through is fascinating. This human connection and interaction is what I enjoy about this place. Being a part of a group that supports a cause.
Finally, I want to thank the amazing Azuki mod team and the kissaten channel for their contributions.
The Brand
So, what sets Azuki apart from other projects? They are shaping a brand or identity. The Azuki website, I believe, best captures their vision. (This is me gushing over the site.)
If you go to the website, turn on the dope playlist in the bottom left. The playlist features a mix of Asian and non-Asian hip-hop and rap artists, with some lo-fi thrown in. The songs on the playlist change, but I think you get the vibe Azuki embodies just by turning on the music.
The Garden is our next stop where we are introduced to Azuki.
A brand.
We're creating a new brand together.
A metaverse brand. By the people.
A collection of 10,000 avatars that grant Garden membership. It starts with exclusive streetwear collabs, NFT drops, live events, and more. Azuki allows for a new media genre that the world has yet to discover. Let's build together an Azuki, your metaverse identity.
The Garden is a magical internet corner where art, community, and culture collide. The boundaries between the physical and digital worlds are blurring.
Try a Red Bean.
The text begins with Azuki's intention in the space. It's a community-made metaverse brand. Then it goes into more detail about Azuki's plans. Initiation of a story or journey. "Would you like to take the red bean and jump down the rabbit hole with us?" I love the Matrix red pill or blue pill play they used. (Azuki in Japanese means red bean.)
Morpheus, the rebel leader, offers Neo the choice of a red or blue pill in The Matrix. “You take the blue pill... After the story, you go back to bed and believe whatever you want. Your red pill... Let me show you how deep the rabbit hole goes.” Aware that the red pill will free him from the enslaving control of the machine-generated dream world and allow him to escape into the real world, he takes it. However, living the “truth of reality” is harsher and more difficult.
It's intriguing and draws you in. Taking the red bean causes what? Where am I going? I think they did well in piqueing a newcomer's interest.
Not convinced by the Garden? Read the Manifesto. It reinforces Azuki's role.
Here comes a new wave…
And surfing here is different.
Breaking down barriers.
Building open communities.
Creating magic internet money with our friends.
To those who don’t get it, we tell them: gm.
They’ll come around eventually.
Here’s to the ones with the courage to jump down a peculiar rabbit hole.
One that pulls you away from a world that’s created by many and owned by few…
To a world that’s created by more and owned by all.
From The Garden come the human beans that sprout into your family.
We rise together.
We build together.
We grow together.
Ready to take the red bean?
Not to mention the Mindmap, it sets Azuki apart from other projects and overused Roadmaps. I like how the team recognizes that the NFT space is not linear. So many of us are still trying to figure it out. It is Azuki's vision to adapt to changing environments while maintaining their values. I admire their commitment to long-term growth.
Conclusion
To be honest, I have no idea what the future holds. Azuki is still new and could fail. But I'm a long-term Azuki fan. I don't care about quick gains. The future looks bright for Azuki. I believe in the team's output. I love being an Azuki.
Thank you! IKUZO!
Full post here