




More on Technology

Mark Schaefer
3 years ago
20 Fun Uses for ChatGPT

Our RISE community is stoked on ChatGPT. ChatGPT has countless uses.
Early on. Companies are figuring out the legal and ethical implications of AI's content revolution. Using AI for everyday tasks is cool.
So I challenged RISE friends... Let's have fun and share non-obvious uses.
Onward!
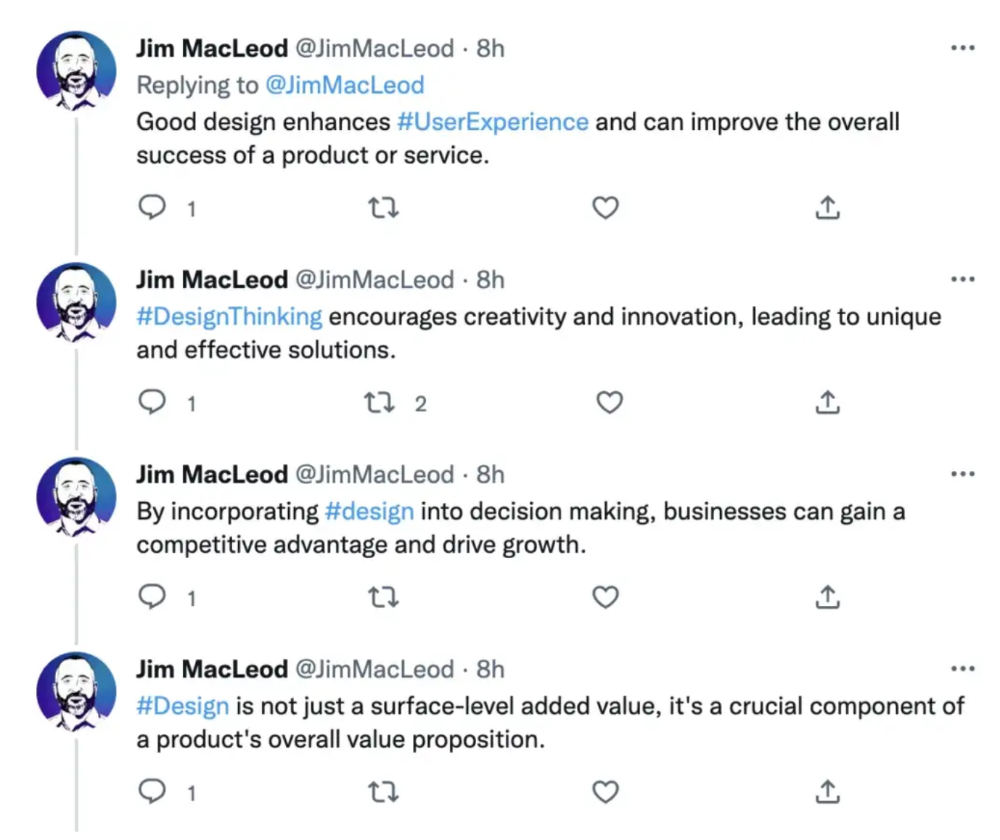
1. Tweet
Jim MacLeod requested a design-themed Twitter thread from ChatGPT.
2. Novelize
Giuseppe Fratoni writes novels.
"This is amazing!" Impotent. I asked about writing, mystery novels, and jazz.
"Develop a mystery novel plot in which a disillusioned homicide detective hunts a serial killer who targets jazz musicians who play Autumn Leaves."
"I have:
Detective James Thompson is a seasoned veteran of the Homicide department, but lately he’s been feeling burnt out and disillusioned. His latest case, the murder of a young jazz pianist who was found brutally killed in his home, only serves to deepen his sense of despair … (much more provided)
3. Question-and-answer sessions
Bliss recommends:
You have a guest speaker and want to ask audience questions.
Pre-generate questions with ChatGPT. "And here's a question from our AI?"
The conference is about Western water scarcity. Water management expert. My AI question was...
Which desalination-related questions should I ask an expert?
ChatGPT said...
How is desalination currently being used around the world, and in what types of locations is it most effective?
What are the potential advantages and disadvantages of using desalination to provide fresh water?
What are some of the key challenges and limitations of desalination technology, and how are they being addressed?
4. Game-making
Richard's a board game expert. He suggests using ChatGPT to plan games. Note: Some people have started getting help solving crossword puzzle clues.

5. Matchmaking
Tanya Thompson thinks it helps dating. ChatGPT:
Here are some flirty first-message ideas for dating apps:
I noticed you from afar. I had to say hi and see if we clicked.
Your profile picture is gorgeous. I'm obsessed with your [Feature] and want to know you better.
I don't usually message first, but I had to. You're [Attractive Quality] and I can't wait to talk.”
Hello. Your profile intimidates me. I'm starstruck by your [Attractiveness]. (Many instances)
5. Solitude/anxiety
ChatGPT excels at one-on-one conversations.
PepperBrooks: "I'm sad and lonely."
ChatGPT: I’m sorry to hear that you’re feeling sad and lonely. It’s natural to feel down sometimes, but it’s important to remember that you’re not alone. There are many people who care about you and want to help you. It can be helpful to talk to someone about your feelings, whether it’s a close friend, family member, or mental health professional.
Sometimes, just expressing your thoughts and emotions to someone else can help to alleviate your sadness and loneliness. It’s also important to take care of yourself and do things that make you happy, such as spending time with loved ones, pursuing a hobby, or exercising. These things can help to improve your mood and make you feel more connected to others. Remember that you are strong and capable, and that you can get through this difficult time.
Daniel Nestle asked ChatGPT to generate journal prompts to help him deal with anxiety.
Write down the things that are causing you anxiety at the moment.
Describe a situation in which you felt anxious and how you coped with it.
Reflect on how your thoughts and beliefs contribute to your anxiety.
Write a letter to your anxiety, expressing your feelings and concerns
Imagine yourself in a calm and peaceful place, and describe it in detail.
(many more items followed)
6. Names
Continued Daniel:
Also, naming ideas.
Me: Name this drink. Japanese gin, unsweetened tonic, lime, Szechuan pepper, grapefruit.
ChatGPT: How about “Sakura Sunrise?” The name incorporates the Japanese gin and the citrus flavors of grapefruit and lime, and the word “sunrise” suggests a fresh and invigorating start to the day. Alternatively, you could go with something like “Peppered Grapefruit Gin Fizz” to emphasize the unique flavor combination of Szechuan pepper and grapefruit.
7. Translation on the go
Monks recommends: ChatGPT is a perfect mobile translation tool. Say you need help in Italy.
ME: Translate to Italian
Where is the nearest gas station?
ChatGPT: “La mia auto sta per esaurire il carburante, mi puoi dire dove si trova la stazione di servizio più vicina?”
8. Fitness
Monks added:
ME: In 3 months, I want to run 5km. Plan out how I can do this.
ChatGPT: Here's a 3-month plan to run 5km.
Start by walking for 15–20 minutes each day to build up your endurance and get your body used to regular exercise.
After a week of walking, begin incorporating short jogs into your routine. Start by jogging for 1–2 minutes at a time, with walking breaks in between. Gradually increase the length of your jogs and reduce the amount of time you spend walking.
Once you can jog for 10 minutes without stopping, start increasing the distance of your runs. Aim to run 1km without stopping and then gradually increase the distance over time.
In addition to your regular runs, incorporate strength training and stretching into your routine to improve your overall fitness and reduce the risk of injury.
(more details continued on)
9. Integrations and coding
10. Teacher lesson plans
Spencer Crandall saved time.
This morning, I wondered who has the hardest job. Teachers.
Many students, little time. ChatGPT could handle lesson planning. I tried it and got this.
Lesson Title: The History and Impact of Artificial Intelligence
Students will understand the history and development of AI and the potential positive and negative impacts on society.
AI timeline AI technologies and applications
Overview:
Introduce the topic of artificial intelligence, and explain that it refers to the development of computer systems and algorithms that can simulate human intelligence and behavior.
Show the timeline of significant events in the history of AI, and discuss the key milestones and developments in the field.
Show examples of AI technologies and applications, and explain how they are used in various industries and fields.
Discuss the potential positive and negative impacts of AI on society, including its potential to improve productivity, efficiency, and safety, as well as its potential to create new challenges and concerns, such as job displacement and ethical issues.
(many more details followed)
11. Find podcast guests.
Joeri Billast suggested:
Who should be on my Web3 podcast?
ChatGPT: Web3 marketing experts, influencers, and thought leaders make great podcast guests. These include Web3 marketers, content creators, business owners, entrepreneurs, and technologists. You could invite Web3 startups and organizations to your podcast.
Please give examples.
ChatGPT: Ideal Web3 marketing podcast guests include:
Tim Berner-Lee, inventor of the World Wide Web
Chris Dixon, general partner at Andreessen Horowitz
Vitalik Buterin, founder of Ethereum
Joe Lubin, founder of ConsenSys
Susan Fowler, author of Whistleblower
(many other suggestions)
12. Comments and reviews on social media
Lisa Monk thinks ChatGPT can help retail staff with social media.
She asked ChatGPT to "review this restaurant"
POSITIVE CUSTOMER REVIEW: I absolutely love this place. We eat out a lot however this place has topped it all. Perfect meals, amazing staff and the timing for it all was great! Special thanks to Sophie B (you rock) From your guests all the way from the Gold Coast, THANK YOU
ChatGPT REPLY: Thank you so much for your kind words and for taking the time to write a review. We are delighted to hear that you had such a great experience at our restaurant. We are thrilled that you enjoyed your meal and the service provided by Sophie. It’s always a pleasure to serve guests visiting from the Gold Coast and we are grateful for your support. We look forward to welcoming you back again soon. Thank you again for your positive review.
CUSTOMER REVIEW: Most average food, there is a nice view, But that’s about it
ChatGPT: Thank you for your review. We apologize if your dining experience was not up to your expectations. We strive to provide top-quality food and service to all of our customers, and we will take your feedback into consideration as we continue to improve. Thank you for letting us know about your experience.
13. Crime-fighting
Zack Seipert said, "I researched some famous unsolved murders, and ChatGPT laid out the crime, suspects, clues, and more." I bet experienced detectives could solve some of these cold cases.
14. Reduce bias
Joanne Taylor struggles to remove biases from her writing. She asked ChatGPT for ideas.
I asked ChatGPT to check a text for racial bias, and it did well.
15. Furnishings
I designed a small, unique table using ChatGPT and MidJourney. I edited ChatGPT's idea for clarity and brevity before entering it in MidJourney.
Results:

16. Serialize a novel
Scott Scowcoft led ChatCPT through iterations of a story text to create serialized novel frames. You can view this here.
17. Interview preparation
I was on a sales podcast. Although this is marketing-related, it's not my forte. I asked ChatGPT for help with a sales interview. Response:
Here are some interview questions about the future of sales and how to answer them.
How will technology affect sales in the future?
Technology will impact sales in the coming years. Automation and AI could be used to handle routine tasks, and data analysis and CRM could become more important. E-commerce and online sales channels are also reshaping the sales landscape.
How will the salesperson's role change?
Future sales roles may change in response to changing customer needs and expectations. Salespeople must be knowledgeable and consultative to help customers navigate complex products and services. Increasing importance of data analysis and CRM tools will require salespeople to understand and use technology effectively.
Future sales professionals will need what skills?
Future salespeople will need many skills. Sales professionals must have strong communication and interpersonal skills, as well as product and service knowledge and the ability to use data analysis and CRM tools effectively. Adapting to changing customer needs and staying current on industry trends will also be important for sales success.
18. Gift ideas
I need Christmas gift ideas for my wife. I asked:
Suggest a gift idea under $200 for a middle-aged woman who loves The Eagles.
A middle-aged woman who loves The Eagles might like a vinyl record of "Hotel California" or "The Long Run." Many music fans enjoy the unique sound and experience of vinyl records.
Pair the record with a high-quality record player for a complete gift. The vinyl record and record player should fit within your $200 budget for an Eagles fan.
19. Explaining complex concepts
I entered: Explain quantum physics to me as if I were 10 years old.
Quantum physics is a branch of science that studies how tiny particles, like atoms and subatomic particles, behave. These particles are so small that they don’t always follow the same rules as the things we can see and touch every day.
For example, sometimes they can be in two places at the same time, or they can be friends with each other even if they are far apart. This might sound strange, but it’s what scientists have learned from studying these tiny particles. Quantum physics helps us understand how the world works at a very small scale, and it can also help us make new technologies, like computers that are much faster than the ones we have today.
20. AP-style editing
Blogs, journals, and books follow AP Style. I asked ChatGPT to "edit using AP Style" and it did a great job.
And then... "Write a catchy headline for a blog post about 16 ChatGPT uses"
Here are some possible blog post titles for 20 creative ChatGPT uses:
“20 Fun and Creative Ways to Use ChatGPT: From Games to Quizzes and More”
“The Ultimate Guide to Using ChatGPT for Entertainment and Creativity”
“20 Reasons to Use ChatGPT: How it Can Enhance Your Gaming, Storytelling, and More”
20 Entertaining Uses for ChatGPT You Never Knew Were Possible”
“Unleash Your Imagination with ChatGPT: 16 Creative and Fun Ways to Use it”
In a previous post, I said ChatGPT will change marketing careers forever. I have never made a statement like that in my life. Even in the early days of the internet, people were cautious.
This technology was just released two weeks ago, and over a million people are already using it. This is the fastest technology adoption in history.
Today's post offers inventive and entertaining ideas, but it's just the beginning. ChatGPT writes code, music, and papers.

Will Lockett
3 years ago
The World Will Change With MIT's New Battery

It's cheaper, faster charging, longer lasting, safer, and better for the environment.
Batteries are the future. Next-gen and planet-saving technology, including solar power and EVs, require batteries. As these smart technologies become more popular, we find that our batteries can't keep up. Lithium-ion batteries are expensive, slow to charge, big, fast to decay, flammable, and not environmentally friendly. MIT just created a new battery that eliminates all of these problems. So, is this the battery of the future? Or is there a catch?
When I say entirely new, I mean it. This battery employs no currently available materials. Its electrodes are constructed of aluminium and pure sulfur instead of lithium-complicated ion's metals and graphite. Its electrolyte is formed of molten chloro-aluminate salts, not an organic solution with lithium salts like lithium-ion batteries.
How does this change in materials help?
Aluminum, sulfur, and chloro-aluminate salts are abundant, easy to acquire, and cheap. This battery might be six times cheaper than a lithium-ion battery and use less hazardous mining. The world and our wallets will benefit.
But don’t go thinking this means it lacks performance.
This battery charged in under a minute in tests. At 25 degrees Celsius, the battery will charge 25 times slower than at 110 degrees Celsius. This is because the salt, which has a very low melting point, is in an ideal state at 110 degrees and can carry a charge incredibly quickly. Unlike lithium-ion, this battery self-heats when charging and discharging, therefore no external heating is needed.
Anyone who's seen a lithium-ion battery burst might be surprised. Unlike lithium-ion batteries, none of the components in this new battery can catch fire. Thus, high-temperature charging and discharging speeds pose no concern.
These batteries are long-lasting. Lithium-ion batteries don't last long, as any iPhone owner can attest. During charging, metal forms a dendrite on the electrode. This metal spike will keep growing until it reaches the other end of the battery, short-circuiting it. This is why phone batteries only last a few years and why electric car range decreases over time. This new battery's molten salt slows deposition, extending its life. This helps the environment and our wallets.
These batteries are also energy dense. Some lithium-ion batteries have 270 Wh/kg energy density (volume and mass). Aluminum-sulfur batteries could have 1392 Wh/kg, according to calculations. They'd be 5x more energy dense. Tesla's Model 3 battery would weigh 96 kg instead of 480 kg if this battery were used. This would improve the car's efficiency and handling.
These calculations were for batteries without molten salt electrolyte. Because they don't reflect the exact battery chemistry, they aren't a surefire prediction.
This battery seems great. It will take years, maybe decades, before it reaches the market and makes a difference. Right?
Nope. The project's scientists founded Avanti to develop and market this technology.
So we'll soon be driving cheap, durable, eco-friendly, lightweight, and ultra-safe EVs? Nope.
This battery must be kept hot to keep the salt molten; otherwise, it won't work and will expand and contract, causing damage. This issue could be solved by packs that can rapidly pre-heat, but that project is far off.
Rapid and constant charge-discharge cycles make these batteries ideal for solar farms, homes, and EV charging stations. The battery is constantly being charged or discharged, allowing it to self-heat and maintain an ideal temperature.
These batteries aren't as sexy as those making EVs faster, more efficient, and cheaper. Grid batteries are crucial to our net-zero transition because they allow us to use more low-carbon energy. As we move away from fossil fuels, we'll need millions of these batteries, so the fact that they're cheap, safe, long-lasting, and environmentally friendly will be huge. Who knows, maybe EVs will use this technology one day. MIT has created another world-changing technology.

Clive Thompson
3 years ago
Small Pieces of Code That Revolutionized the World
Few sentences can have global significance.

Ethan Zuckerman invented the pop-up commercial in 1997.
He was working for Tripod.com, an online service that let people make little web pages for free. Tripod offered advertising to make money. Advertisers didn't enjoy seeing their advertising next to filthy content, like a user's anal sex website.
Zuckerman's boss wanted a solution. Wasn't there a way to move the ads away from user-generated content?
When you visited a Tripod page, a pop-up ad page appeared. So, the ad isn't officially tied to any user page. It'd float onscreen.
Here’s the thing, though: Zuckerman’s bit of Javascript, that created the popup ad? It was incredibly short — a single line of code:
window.open('http://tripod.com/navbar.html'
"width=200, height=400, toolbar=no, scrollbars=no, resizable=no, target=_top");Javascript tells the browser to open a 200-by-400-pixel window on top of any other open web pages, without a scrollbar or toolbar.
Simple yet harmful! Soon, commercial websites mimicked Zuckerman's concept, infesting the Internet with pop-up advertising. In the early 2000s, a coder for a download site told me that most of their revenue came from porn pop-up ads.
Pop-up advertising are everywhere. You despise them. Hopefully, your browser blocks them.
Zuckerman wrote a single line of code that made the world worse.

I read Zuckerman's story in How 26 Lines of Code Changed the World. Torie Bosch compiled a humorous anthology of short writings about code that tipped the world.
Most of these samples are quite short. Pop-cultural preconceptions about coding say that important code is vast and expansive. Hollywood depicts programmers as blurs spouting out Niagaras of code. Google's success was formerly attributed to its 2 billion lines of code.
It's usually not true. Google's original breakthrough, the piece of code that propelled Google above its search-engine counterparts, was its PageRank algorithm, which determined a web page's value based on how many other pages connected to it and the quality of those connecting pages. People have written their own Python versions; it's only a few dozen lines.
Google's operations, like any large tech company's, comprise thousands of procedures. So their code base grows. The most impactful code can be brief.
The examples are fascinating and wide-ranging, so read the whole book (or give it to nerds as a present). Charlton McIlwain wrote a chapter on the police beat algorithm developed in the late 1960s to anticipate crime hotspots so law enforcement could dispatch more officers there. It created a racial feedback loop. Since poor Black neighborhoods were already overpoliced compared to white ones, the algorithm directed more policing there, resulting in more arrests, which convinced it to send more police; rinse and repeat.
Kelly Chudler's You Are Not Expected To Understand This depicts the police-beat algorithm.

Even shorter code changed the world: the tracking pixel.
Lily Hay Newman's chapter on monitoring pixels says you probably interact with this code every day. It's a snippet of HTML that embeds a single tiny pixel in an email. Getting an email with a tracking code spies on me. As follows: My browser requests the single-pixel image as soon as I open the mail. My email sender checks to see if Clives browser has requested that pixel. My email sender can tell when I open it.
Adding a tracking pixel to an email is easy:
<img src="URL LINKING TO THE PIXEL ONLINE" width="0" height="0">An older example: Ellen R. Stofan and Nick Partridge wrote a chapter on Apollo 11's lunar module bailout code. This bailout code operated on the lunar module's tiny on-board computer and was designed to prioritize: If the computer grew overloaded, it would discard all but the most vital work.
When the lunar module approached the moon, the computer became overloaded. The bailout code shut down anything non-essential to landing the module. It shut down certain lunar module display systems, scaring the astronauts. Module landed safely.
22-line code
POODOO INHINT
CA Q
TS ALMCADR
TC BANKCALL
CADR VAC5STOR # STORE ERASABLES FOR DEBUGGING PURPOSES.
INDEX ALMCADR
CAF 0
ABORT2 TC BORTENT
OCT77770 OCT 77770 # DONT MOVE
CA V37FLBIT # IS AVERAGE G ON
MASK FLAGWRD7
CCS A
TC WHIMPER -1 # YES. DONT DO POODOO. DO BAILOUT.
TC DOWNFLAG
ADRES STATEFLG
TC DOWNFLAG
ADRES REINTFLG
TC DOWNFLAG
ADRES NODOFLAG
TC BANKCALL
CADR MR.KLEAN
TC WHIMPERThis fun book is worth reading.
I'm a contributor to the New York Times Magazine, Wired, and Mother Jones. I've also written Coders: The Making of a New Tribe and the Remaking of the World and Smarter Than You Think: How Technology is Changing Our Minds. Twitter and Instagram: @pomeranian99; Mastodon: @clive@saturation.social.
You might also like

Recep İnanç
3 years ago
Effective Technical Book Reading Techniques

Technical books aren't like novels. We need a new approach to technical texts. I've spent years looking for a decent reading method. I tried numerous ways before finding one that worked. This post explains how I read technical books efficiently.
What Do I Mean When I Say Effective?
Effectiveness depends on the book. Effective implies I know where to find answers after reading a reference book. Effective implies I learned the book's knowledge after reading it.
I use reference books as tools in my toolkit. I won't carry all my tools; I'll merely need them. Non-reference books teach me techniques. I never have to make an effort to use them since I always have them.
Reference books I like:
Design Patterns: Elements of Reusable Object-Oriented Software
Refactoring: Improving the Design of Existing Code
You can also check My Top Takeaways from Refactoring here.
Non-reference books I like:
The Approach
Technical books might be overwhelming to read in one sitting. Especially when you have no idea what is coming next as you read. When you don't know how deep the rabbit hole goes, you feel lost as you read. This is my years-long method for overcoming this difficulty.
Whether you follow the step-by-step guide or not, remember these:
Understand the terminology. Make sure you get the meaning of any terms you come across more than once. The likelihood that a term will be significant increases as you encounter it more frequently.
Know when to stop. I've always believed that in order to truly comprehend something, I must delve as deeply as possible into it. That, however, is not usually very effective. There are moments when you have to draw the line and start putting theory into practice (if applicable).
Look over your notes. When reading technical books or documents, taking notes is a crucial habit to develop. Additionally, you must regularly examine your notes if you want to get the most out of them. This will assist you in internalizing the lessons you acquired from the book. And you'll see that the urge to review reduces with time.
Let's talk about how I read a technical book step by step.
0. Read the Foreword/Preface
These sections are crucial in technical books. They answer Who should read it, What each chapter discusses, and sometimes How to Read? This is helpful before reading the book. Who could know the ideal way to read the book better than the author, right?
1. Scanning
I scan the chapter. Fast scanning is needed.
I review the headings.
I scan the pictures quickly.
I assess the chapter's length to determine whether I might divide it into more manageable sections.
2. Skimming
Skimming is faster than reading but slower than scanning.
I focus more on the captions and subtitles for the photographs.
I read each paragraph's opening and closing sentences.
I examined the code samples.
I attempt to grasp each section's basic points without getting bogged down in the specifics.
Throughout the entire reading period, I make an effort to make mental notes of what may require additional attention and what may not. Because I don't want to spend time taking physical notes, kindly notice that I am using the term "mental" here. It is much simpler to recall. You may think that this is more significant than typing or writing “Pay attention to X.”
I move on quickly. This is something I considered crucial because, when trying to skim, it is simple to start reading the entire thing.
3. Complete reading
Previous steps pay off.
I finished reading the chapter.
I concentrate on the passages that I mentally underlined when skimming.
I put the book away and make my own notes. It is typically more difficult than it seems for me. But it's important to speak in your own words. You must choose the right words to adequately summarize what you have read. How do those words make you feel? Additionally, you must be able to summarize your notes while you are taking them. Sometimes as I'm writing my notes, I realize I have no words to convey what I'm thinking or, even worse, I start to doubt what I'm writing down. This is a good indication that I haven't internalized that idea thoroughly enough.
I jot my inquiries down. Normally, I read on while compiling my questions in the hopes that I will learn the answers as I read. I'll explore those issues more if I wasn't able to find the answers to my inquiries while reading the book.
Bonus!
Best part: If you take lovely notes like I do, you can publish them as a blog post with a few tweaks.
Conclusion
This is my learning journey. I wanted to show you. This post may help someone with a similar learning style. You can alter the principles above for any technical material.

Luke Plunkett
3 years ago
Gran Turismo 7 Update Eases Up On The Grind After Fan Outrage
Polyphony Digital has changed the game after apologizing in March.
To make amends for some disastrous downtime, Gran Turismo 7 director Kazunori Yamauchi announced a credits handout and promised to “dramatically change GT7's car economy to help make amends” last month. The first of these has arrived.
The game's 1.11 update includes the following concessions to players frustrated by the economy and its subsequent grind:
-
The last half of the World Circuits events have increased in-game credit rewards.
-
Modified Arcade and Custom Race rewards
-
Clearing all circuit layouts with Gold or Bronze now rewards In-game Credits. Exiting the Sector selection screen with the Exit button will award Credits if an event has already been cleared.
-
Increased Credits Rewards in Lobby and Daily Races
-
Increased the free in-game Credits cap from 20,000,000 to 100,000,000.
Additionally, “The Human Comedy” missions are one-hour endurance races that award “up to 1,200,000” credits per event.
This isn't everything Yamauchi promised last month; he said it would take several patches and updates to fully implement the changes. Here's a list of everything he said would happen, some of which have already happened (like the World Cup rewards and credit cap):
- Increase rewards in the latter half of the World Circuits by roughly 100%.
- Added high rewards for all Gold/Bronze results clearing the Circuit Experience.
- Online Races rewards increase.
- Add 8 new 1-hour Endurance Race events to Missions. So expect higher rewards.
- Increase the non-paid credit limit in player wallets from 20M to 100M.
- Expand the number of Used and Legend cars available at any time.
- With time, we will increase the payout value of limited time rewards.
- New World Circuit events.
- Missions now include 24-hour endurance races.
- Online Time Trials added, with rewards based on the player's time difference from the leader.
- Make cars sellable.
The full list of updates and changes can be found here.
Read the original post.

The Verge
3 years ago
Bored Ape Yacht Club creator raises $450 million at a $4 billion valuation.
Yuga Labs, owner of three of the biggest NFT brands on the market, announced today a $450 million funding round. The money will be used to create a media empire based on NFTs, starting with games and a metaverse project.
The team's Otherside metaverse project is an MMORPG meant to connect the larger NFT universe. They want to create “an interoperable world” that is “gamified” and “completely decentralized,” says Wylie Aronow, aka Gordon Goner, co-founder of Bored Ape Yacht Club. “We think the real Ready Player One experience will be player run.”
Just a few weeks ago, Yuga Labs announced the acquisition of CryptoPunks and Meebits from Larva Labs. The deal brought together three of the most valuable NFT collections, giving Yuga Labs more IP to work with when developing games and metaverses. Last week, ApeCoin was launched as a cryptocurrency that will be governed independently and used in Yuga Labs properties.
Otherside will be developed by “a few different game studios,” says Yuga Labs CEO Nicole Muniz. The company plans to create development tools that allow NFTs from other projects to work inside their world. “We're welcoming everyone into a walled garden.”
However, Yuga Labs believes that other companies are approaching metaverse projects incorrectly, allowing the startup to stand out. People won't bond spending time in a virtual space with nothing going on, says Yuga Labs co-founder Greg Solano, aka Gargamel. Instead, he says, people bond when forced to work together.
In order to avoid getting smacked, Solano advises making friends. “We don't think a Zoom chat and walking around saying ‘hi' creates a deep social experience.” Yuga Labs refused to provide a release date for Otherside. Later this year, a play-to-win game is planned.
The funding round was led by Andreessen Horowitz, a major investor in the Web3 space. It previously backed OpenSea and Coinbase. Animoca Brands, Coinbase, and MoonPay are among those who have invested. Andreessen Horowitz general partner Chris Lyons will join Yuga Labs' board. The Financial Times broke the story last month.
"META IS A DOMINANT DIGITAL EXPERIENCE PROVIDER IN A DYSTOPIAN FUTURE."
This emerging [Web3] ecosystem is important to me, as it is to companies like Meta,” Chris Dixon, head of Andreessen Horowitz's crypto arm, tells The Verge. “In a dystopian future, Meta is the dominant digital experience provider, and it controls all the money and power.” (Andreessen Horowitz co-founder Marc Andreessen sits on Meta's board and invested early in Facebook.)
Yuga Labs has been profitable so far. According to a leaked pitch deck, the company made $137 million last year, primarily from its NFT brands, with a 95% profit margin. (Yuga Labs declined to comment on deck figures.)
But the company has built little so far. According to OpenSea data, it has only released one game for a limited time. That means Yuga Labs gets hundreds of millions of dollars to build a gaming company from scratch, based on a hugely lucrative art project.
Investors fund Yuga Labs based on its success. That's what they did, says Dixon, “they created a culture phenomenon”. But ultimately, the company is betting on the same thing that so many others are: that a metaverse project will be the next big thing. Now they must construct it.