


More on Web3 & Crypto

Julie Plavnik
3 years ago
How to Become a Crypto Broker [Complying and Making Money]
Three options exist. The third one is the quickest and most fruitful.

You've mastered crypto trading and want to become a broker.
So you may wonder: Where to begin?
If so, keep reading.
Today I'll compare three different approaches to becoming a cryptocurrency trader.
What are cryptocurrency brokers, and how do they vary from stockbrokers?
A stockbroker implements clients' market orders (retail or institutional ones).
Brokerage firms are regulated, insured, and subject to regulatory monitoring.
Stockbrokers are required between buyers and sellers. They can't trade without a broker. To trade, a trader must open a broker account and deposit money. When a trader shops, he tells his broker what orders to place.
Crypto brokerage is trade intermediation with cryptocurrency.
In crypto trading, however, brokers are optional.
Crypto exchanges offer direct transactions. Open an exchange account (no broker needed) and make a deposit.
Question:
Since crypto allows DIY trading, why use a broker?
Let's compare cryptocurrency exchanges vs. brokers.
Broker versus cryptocurrency exchange
Most existing crypto exchanges are basically brokers.
Examine their primary services:
connecting purchasers and suppliers
having custody of clients' money (with the exception of decentralized cryptocurrency exchanges),
clearance of transactions.
Brokerage is comparable, don't you think?
There are exceptions. I mean a few large crypto exchanges that follow the stock exchange paradigm. They outsource brokerage, custody, and clearing operations. Classic exchange setups are rare in today's bitcoin industry.
Back to our favorite “standard” crypto exchanges. All-in-one exchanges and brokers. And usually, they operate under a broker or a broker-dealer license, save for the exchanges registered somewhere in a free-trade offshore paradise. Those don’t bother with any licensing.
What’s the sense of having two brokers at a time?
Better liquidity and trading convenience.
The crypto business is compartmentalized.
We have CEXs, DEXs, hybrid exchanges, and semi-exchanges (those that aggregate liquidity but do not execute orders on their sides). All have unique regulations and act as sovereign states.
There are about 18k coins and hundreds of blockchain protocols, most of which are heterogeneous (i.e., different in design and not interoperable).
A trader must register many accounts on different exchanges, deposit funds, and manage them all concurrently to access global crypto liquidity.
It’s extremely inconvenient.
Crypto liquidity fragmentation is the largest obstacle and bottleneck blocking crypto from mass adoption.
Crypto brokers help clients solve this challenge by providing one-gate access to deep and diverse crypto liquidity from numerous exchanges and suppliers. Professionals and institutions need it.
Another killer feature of a brokerage may be allowing clients to trade crypto with fiat funds exclusively, without fiat/crypto conversion. It is essential for professional and institutional traders.
Who may work as a cryptocurrency broker?
Apparently, not anyone. Brokerage requires high-powered specialists because it involves other people's money.
Here's the essentials:
excellent knowledge, skills, and years of trading experience
high-quality, quick, and secure infrastructure
highly developed team
outstanding trading capital
High-ROI network: long-standing, trustworthy connections with customers, exchanges, liquidity providers, payment gates, and similar entities
outstanding marketing and commercial development skills.
What about a license for a cryptocurrency broker? Is it necessary?
Complex question.
If you plan to play in white-glove jurisdictions, you may need a license. For example, in the US, as a “money transmitter” or as a CASSP (crypto asset secondary services provider) in Australia.
Even in these jurisdictions, there are no clear, holistic crypto brokerage and licensing policies.
Your lawyer will help you decide if your crypto brokerage needs a license.
Getting a license isn't quick. Two years of patience are needed.
How can you turn into a cryptocurrency broker?
Finally, we got there! 🎉
Three actionable ways exist:
To kickstart a regulated stand-alone crypto broker
To get a crypto broker franchise, and
To become a liquidity network broker.
Let's examine each.
1. Opening a regulated cryptocurrency broker
It's difficult. Especially If you're targeting first-world users.
You must comply with many regulatory, technical, financial, HR, and reporting obligations to keep your organization running. Some are mentioned above.
The licensing process depends on the products you want to offer (spots or derivatives) and the geographic areas you plan to service. There are no general rules for that.
In an overgeneralized way, here are the boxes you will have to check:
capital availability (usually a large amount of capital c is required)
You will have to move some of your team members to the nation providing the license in order to establish an office presence there.
the core team with the necessary professional training (especially applies to CEO, Head of Trading, Assistant to Head of Trading, etc.)
insurance
infrastructure that is trustworthy and secure
adopted proper AML/KYC/financial monitoring policies, etc.
Assuming you passed, what's next?
I bet it won’t be mind-blowing for you that the license is just a part of the deal. It won't attract clients or revenue.
To bring in high-dollar clientele, you must be a killer marketer and seller. It's not easy to convince people to give you money.
You'll need to be a great business developer to form successful, long-term agreements with exchanges (ideally for no fees), liquidity providers, banks, payment gates, etc. Persuade clients.
It's a tough job, isn't it?

I expect a Quora-type question here:
Can I start an unlicensed crypto broker?
Well, there is always a workaround with crypto!
You can register your broker in a free-trade zone like Seychelles to avoid US and other markets with strong watchdogs.
This is neither wise nor sustainable.
First, such experiments are illegal.
Second, you'll have trouble attracting clients and strategic partners.
A license equals trust. That’s it.
Even a pseudo-license from Mauritius matters.
Here are this method's benefits and downsides.
Cons first.
As you navigate this difficult and expensive legal process, you run the risk of missing out on business prospects. It's quite simple to become excellent compliance yet unable to work. Because your competitors are already courting potential customers while you are focusing all of your effort on paperwork.
Only God knows how long it will take you to pass the break-even point when everything with the license has been completed.
It is a money-burning business, especially in the beginning when the majority of your expenses will go toward marketing, sales, and maintaining license requirements. Make sure you have the fortitude and resources necessary to face such a difficult challenge.
Pros
It may eventually develop into a tool for making money. Because big guys who are professionals at trading require a white-glove regulated brokerage. You have every possibility if you work hard in the areas of sales, marketing, business development, and wealth. Simply put, everything must align.
Launching a regulated crypto broker is analogous to launching a crypto exchange. It's ROUGH. Sure you can take it?
2. Franchise for Crypto Broker (Crypto Sub-Brokerage)
A broker franchise is easier and faster than becoming a regulated crypto broker. Not a traditional brokerage.
A broker franchisee, often termed a sub-broker, joins with a broker (a franchisor) to bring them new clients. Sub-brokers market a broker's products and services to clients.
Sub-brokers are the middlemen between a broker and an investor.
Why is sub-brokering easier?
less demanding qualifications and legal complexity. All you need to do is keep a few certificates on hand (each time depends on the jurisdiction).
No significant investment is required
there is no demand that you be a trading member of an exchange, etc.
As a sub-broker, you can do identical duties without as many rights and certifications.
What about the crypto broker franchise?
Sub-brokers aren't common in crypto.
In most existing examples (PayBito, PCEX, etc.), franchises are offered by crypto exchanges, not brokers. Though we remember that crypto exchanges are, in fact, brokers, do we?
Similarly:
For a commission, a franchiser crypto broker receives new leads from a crypto sub-broker.
See above for why enrolling is easy.
Finding clients is difficult. Most crypto traders prefer to buy-sell on their own or through brokers over sub-broker franchises.
3. Broker of the Crypto Trading Network (or a Network Broker)
It's the greatest approach to execute crypto brokerage, based on effort/return.
Network broker isn't an established word. I wrote it for clarity.
Remember how we called crypto liquidity fragmentation the current crypto finance paradigm's main bottleneck?
Where there's a challenge, there's progress.
Several well-funded projects are aiming to fix crypto liquidity fragmentation. Instead of launching another crypto exchange with siloed trading, the greatest minds create trading networks that aggregate crypto liquidity from desynchronized sources and enable quick, safe, and affordable cross-blockchain transactions. Each project offers a distinct option for users.
Crypto liquidity implies:
One-account access to cryptocurrency liquidity pooled from network participants' exchanges and other liquidity sources
compiled price feeds
Cross-chain transactions that are quick and inexpensive, even for HFTs
link between participants of all kinds, and
interoperability among diverse blockchains
Fast, diversified, and cheap global crypto trading from one account.
How does a trading network help cryptocurrency brokers?
I’ll explain it, taking Yellow Network as an example.
Yellow provides decentralized Layer-3 peer-to-peer trading.
trade across chains globally with real-time settlement and
Between cryptocurrency exchanges, brokers, trading companies, and other sorts of network members, there is communication and the exchange of financial information.
Have you ever heard about ECN (electronic communication network)? If not, it's an automated system that automatically matches buy and sell orders. Yellow is a decentralized digital asset ECN.
Brokers can:
Start trading right now without having to meet stringent requirements; all you need to do is integrate with Yellow Protocol and successfully complete some KYC verification.
Access global aggregated crypto liquidity through a single point.
B2B (Broker to Broker) liquidity channels that provide peer liquidity from other brokers. Orders from the other broker will appear in the order book of a broker who is peering with another broker on the market. It will enable a broker to broaden his offer and raise the total amount of liquidity that is available to his clients.
Select a custodian or use non-custodial practices.
Comparing network crypto brokerage to other types:
A licensed stand-alone brokerage business is much more difficult and time-consuming to launch than network brokerage, and
Network brokerage, in contrast to crypto sub-brokerage, is scalable, independent, and offers limitless possibilities for revenue generation.
Yellow Network Whitepaper. has more details on how to start a brokerage business and what rewards you'll obtain.
Final thoughts
There are three ways to become a cryptocurrency broker, including the non-conventional liquidity network brokerage. The last option appears time/cost-effective.
Crypto brokerage isn't crowded yet. Act quickly to find your right place in this market.
Choose the way that works for you best and see you in crypto trading.
Discover Web3 & DeFi with Yellow Network!
Yellow, powered by Openware, is developing a cross-chain P2P liquidity aggregator to unite the crypto sector and provide global remittance services that aid people.
Join the Yellow Community and plunge into this decade's biggest product-oriented crypto project.
Observe Yellow Twitter
Enroll in Yellow Telegram
Visit Yellow Discord.
On Hacker Noon, look us up.
Yellow Network will expose development, technology, developer tools, crypto brokerage nodes software, and community liquidity mining.

Nabil Alouani
3 years ago
Why Cryptocurrency Is Not Dead Despite the FTX Scam
A fraud, free-market, antifragility tale

Crypto's only rival is public opinion.
In less than a week, mainstream media, bloggers, and TikTokers turned on FTX's founder.
While some were surprised, almost everyone with a keyboard and a Twitter account predicted the FTX collapse. These financial oracles should have warned the 1.2 million people Sam Bankman-Fried duped.
After happening, unexpected events seem obvious to our brains. It's a bug and a feature because it helps us cope with disasters and makes our reasoning suck.
Nobody predicted the FTX debacle. Bloomberg? Politicians. Non-famous. No cryptologists. Who?
When FTX imploded, taking billions of dollars with it, an outrage bomb went off, and the resulting shockwave threatens the crypto market's existence.
As someone who lost more than $78,000 in a crypto scam in 2020, I can only understand people’s reactions. When the dust settles and rationality returns, we'll realize this is a natural occurrence in every free market.
What specifically occurred with FTX? (Skip if you are aware.)
FTX is a cryptocurrency exchange where customers can trade with cash. It reached #3 in less than two years as the fastest-growing platform of its kind.
FTX's performance helped make SBF the crypto poster boy. Other reasons include his altruistic public image, his support for the Democrats, and his company Alameda Research.
Alameda Research made a fortune arbitraging Bitcoin.
Arbitrage trading uses small price differences between two markets to make money. Bitcoin costs $20k in Japan and $21k in the US. Alameda Research did that for months, making $1 million per day.
Later, as its capital grew, Alameda expanded its trading activities and began investing in other companies.
Let's now discuss FTX.
SBF's diabolic master plan began when he used FTX-created FTT coins to inflate his trading company's balance sheets. He used inflated Alameda numbers to secure bank loans.
SBF used money he printed himself as collateral to borrow billions for capital. Coindesk exposed him in a report.
One of FTX's early investors tweeted that he planned to sell his FTT coins over the next few months. This would be a minor event if the investor wasn't Binance CEO Changpeng Zhao (CZ).
The crypto space saw a red WARNING sign when CZ cut ties with FTX. Everyone with an FTX account and a brain withdrew money. Two events followed. FTT fell from $20 to $4 in less than 72 hours, and FTX couldn't meet withdrawal requests, spreading panic.
SBF reassured FTX users on Twitter. Good assets.
He lied.
SBF falsely claimed FTX had a liquidity crunch. At the time of his initial claims, FTX owed about $8 billion to its customers. Liquidity shortages are usually minor. To get cash, sell assets. In the case of FTX, the main asset was printed FTT coins.
Sam wouldn't get out of trouble even if he slashed the discount (from $20 to $4) and sold every FTT. He'd flood the crypto market with his homemade coins, causing the price to crash.
SBF was trapped. He approached Binance about a buyout, which seemed good until Binance looked at FTX's books.
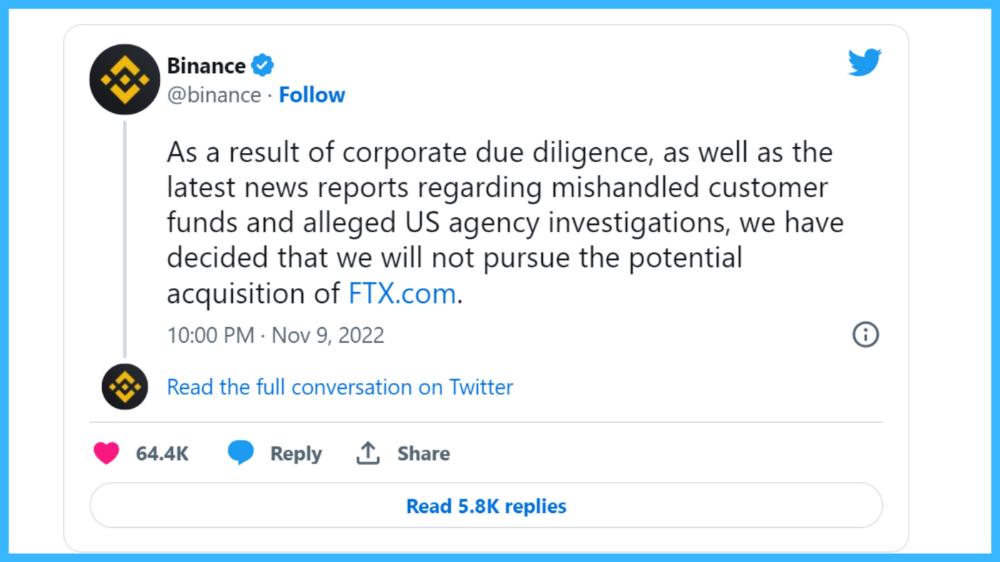
Binance's tweet ended SBF, and he had to apologize, resign as CEO, and file for bankruptcy.
Bloomberg estimated Sam's net worth to be zero by the end of that week. 0!
But that's not all. Twitter investigations exposed fraud at FTX and Alameda Research. SBF used customer funds to trade and invest in other companies.
Thanks to the Twitter indie reporters who made the mainstream press look amateurish. Some Twitter detectives didn't sleep for 30 hours to find answers. Others added to existing threads. Memes were hilarious.
One question kept repeating in my bald head as I watched the Blue Bird. Sam, WTF?
Then I understood.
SBF wanted that FTX becomes a bank.
Think about this. FTX seems healthy a few weeks ago. You buy 2 bitcoins using FTX. You'd expect the platform to take your dollars and debit your wallet, right?
No. They give I-Owe-Yous.
FTX records owing you 2 bitcoins in its internal ledger but doesn't credit your account. Given SBF's tricks, I'd bet on nothing.
What happens if they don't credit my account with 2 bitcoins? Your money goes into FTX's capital, where SBF and his friends invest in marketing, political endorsements, and buying other companies.
Over its two-year existence, FTX invested in 130 companies. Once they make a profit on their purchases, they'll pay you and keep the rest.
One detail makes their strategy dumb. If all FTX customers withdraw at once, everything collapses.
Financially savvy people think FTX's collapse resembles a bank run, and they're right. SBF designed FTX to operate like a bank.
You expect your bank to open a drawer with your name and put $1,000 in it when you deposit $1,000. They deposit $100 in your drawer and create an I-Owe-You for $900. What happens to $900?
Let's sum it up: It's boring and headache-inducing.
When you deposit money in a bank, they can keep 10% and lend the rest. Fractional Reserve Banking is a popular method. Fractional reserves operate within and across banks.
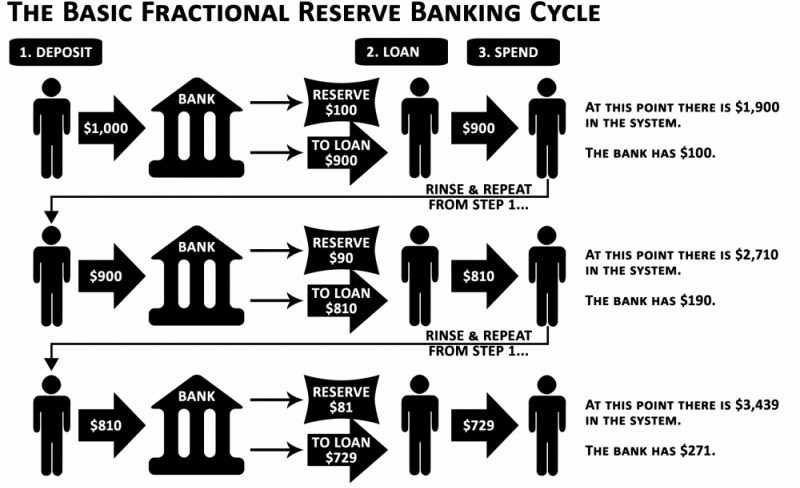
Fractional reserve banking generates $10,000 for every $1,000 deposited. People will pay off their debt plus interest.
As long as banks work together and the economy grows, their model works well.
SBF tried to replicate the system but forgot two details. First, traditional banks need verifiable collateral like real estate, jewelry, art, stocks, and bonds, not digital coupons. Traditional banks developed a liquidity buffer. The Federal Reserve (or Central Bank) injects massive cash into troubled banks.
Massive cash injections come from taxpayers. You and I pay for bankers' mistakes and annual bonuses. Yes, you may think banking is rigged. It's rigged, but it's the best financial game in 150 years. We accept its flaws, including bailouts for too-big-to-fail companies.
Anyway.
SBF wanted Binance's bailout. Binance said no, which was good for the crypto market.
Free markets are resilient.
Nassim Nicholas Taleb coined the term antifragility.
“Some things benefit from shocks; they thrive and grow when exposed to volatility, randomness, disorder, and stressors and love adventure, risk, and uncertainty. Yet, in spite of the ubiquity of the phenomenon, there is no word for the exact opposite of fragile. Let us call it antifragile. Antifragility is beyond resilience or robustness. The resilient resists shocks and stays the same; the antifragile gets better.”
The easiest way to understand how antifragile systems behave is to compare them with other types of systems.
Glass is like a fragile system. It snaps when shocked.
Similar to rubber, a resilient system. After a stressful episode, it bounces back.
A system that is antifragile is similar to a muscle. As it is torn in the gym, it gets stronger.
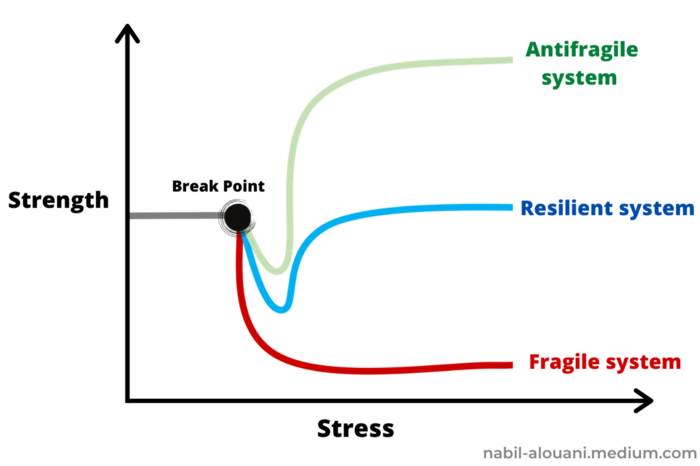
Time-changed things are antifragile. Culture, tech innovation, restaurants, revolutions, book sales, cuisine, economic success, and even muscle shape. These systems benefit from shocks and randomness in different ways, but they all pay a price for antifragility.
Same goes for the free market and financial institutions. Taleb's book uses restaurants as an example and ends with a reference to the 2008 crash.
“Restaurants are fragile. They compete with each other. But the collective of local restaurants is antifragile for that very reason. Had restaurants been individually robust, hence immortal, the overall business would be either stagnant or weak and would deliver nothing better than cafeteria food — and I mean Soviet-style cafeteria food. Further, it [the overall business] would be marred with systemic shortages, with once in a while a complete crisis and government bailout.”
Imagine the same thing with banks.
Independent banks would compete to offer the best services. If one of these banks fails, it will disappear. Customers and investors will suffer, but the market will recover from the dead banks' mistakes.
This idea underpins a free market. Bitcoin and other cryptocurrencies say this when criticizing traditional banking.
The traditional banking system's components never die. When a bank fails, the Federal Reserve steps in with a big taxpayer-funded check. This hinders bank evolution. If you don't let banking cells die and be replaced, your financial system won't be antifragile.
The interdependence of banks (centralization) means that one bank's mistake can sink the entire fleet, which brings us to SBF's ultimate travesty with FTX.
FTX has left the cryptocurrency gene pool.
FTX should be decentralized and independent. The super-star scammer invested in more than 130 crypto companies and linked them, creating a fragile banking-like structure. FTX seemed to say, "We exist because centralized banks are bad." But we'll be good, unlike the centralized banking system.
FTX saved several companies, including BlockFi and Voyager Digital.
FTX wanted to be a crypto bank conglomerate and Federal Reserve. SBF wanted to monopolize crypto markets. FTX wanted to be in bed with as many powerful people as possible, so SBF seduced politicians and celebrities.
Worst? People who saw SBF's plan flaws praised him. Experts, newspapers, and crypto fans praised FTX. When billions pour in, it's hard to realize FTX was acting against its nature.
Then, they act shocked when they realize FTX's fall triggered a domino effect. Some say the damage could wipe out the crypto market, but that's wrong.
Cell death is different from body death.
FTX is out of the game despite its size. Unfit, it fell victim to market natural selection.
Next?
The challengers keep coming. The crypto economy will improve with each failure.
Free markets are antifragile because their fragile parts compete, fostering evolution. With constructive feedback, evolution benefits customers and investors.
FTX shows that customers don't like being scammed, so the crypto market's health depends on them. Charlatans and con artists are eliminated quickly or slowly.
Crypto isn't immune to collapse. Cryptocurrencies can go extinct like biological species. Antifragility isn't immortality. A few more decades of evolution may be enough for humans to figure out how to best handle money, whether it's bitcoin, traditional banking, gold, or something else.
Keep your BS detector on. Start by being skeptical of this article's finance-related claims. Even if you think you understand finance, join the conversation.
We build a better future through dialogue. So listen, ask, and share. When you think you can't find common ground with the opposing view, remember:
Sam Bankman-Fried lied.

CyberPunkMetalHead
3 years ago
It's all about the ego with Terra 2.0.
UST depegs and LUNA crashes 99.999% in a fraction of the time it takes the Moon to orbit the Earth.
Fat Man, a Terra whistle-blower, promises to expose Do Kwon's dirty secrets and shady deals.

The Terra community has voted to relaunch Terra LUNA on a new blockchain. The Terra 2.0 Pheonix-1 blockchain went live on May 28, 2022, and people were airdropped the new LUNA, now called LUNA, while the old LUNA became LUNA Classic.
Does LUNA deserve another chance? To answer this, or at least start a conversation about the Terra 2.0 chain's advantages and limitations, we must assess its fundamentals, ideology, and long-term vision.
Whatever the result, our analysis must be thorough and ruthless. A failure of this magnitude cannot happen again, so we must magnify every potential breaking point by 10.
Will UST and LUNA holders be compensated in full?
The obvious. First, and arguably most important, is to restore previous UST and LUNA holders' bags.
Terra 2.0 has 1,000,000,000,000 tokens to distribute.
25% of a community pool
Holders of pre-attack LUNA: 35%
10% of aUST holders prior to attack
Holders of LUNA after an attack: 10%
UST holders as of the attack: 20%
Every LUNA and UST holder has been compensated according to the above proposal.
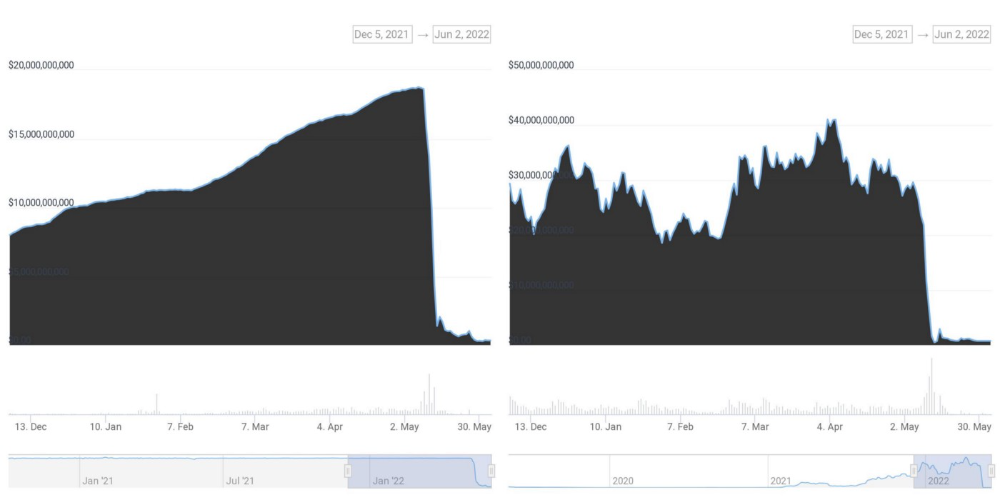
According to self-reported data, the new chain has 210.000.000 tokens and a $1.3bn marketcap. LUNC and UST alone lost $40bn. The new token must fill this gap. Since launch:
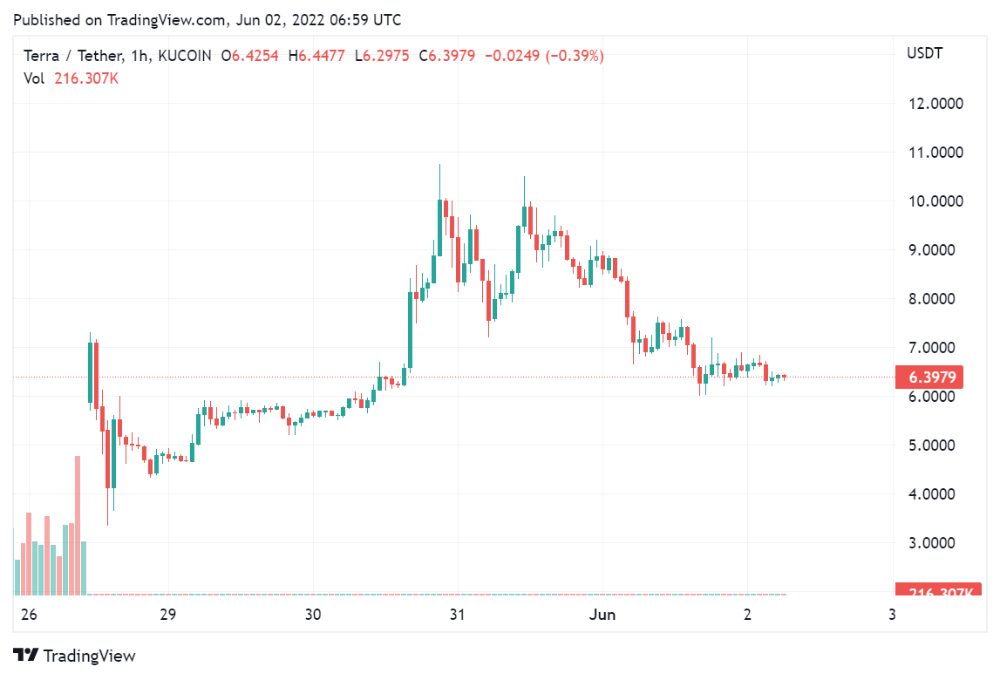
LUNA holders collectively own $1b worth of LUNA if we subtract the 25% community pool airdrop from the current market cap and assume airdropped LUNA was never sold.
At the current supply, the chain must grow 40 times to compensate holders. At the current supply, LUNA must reach $240.
LUNA needs a full-on Bull Market to make LUNC and UST holders whole.
Who knows if you'll be whole? From the time you bought to the amount and price, there are too many variables to determine if Terra can cover individual losses.
The above distribution doesn't consider individual cases. Terra didn't solve individual cases. It would have been huge.
What does LUNA offer in terms of value?
UST's marketcap peaked at $18bn, while LUNC's was $41bn. LUNC and UST drove the Terra chain's value.
After it was confirmed (again) that algorithmic stablecoins are bad, Terra 2.0 will no longer support them.
Algorithmic stablecoins contributed greatly to Terra's growth and value proposition. Terra 2.0 has no product without algorithmic stablecoins.
Terra 2.0 has an identity crisis because it has no actual product. It's like Volkswagen faking carbon emission results and then stopping car production.
A project that has already lost the trust of its users and nearly all of its value cannot survive without a clear and in-demand use case.
Do Kwon, how about him?
Oh, the Twitter-caller-poor? Who challenges crypto billionaires to break his LUNA chain? Who dissolved Terra Labs South Korea before depeg? Arrogant guy?
That's not a good image for LUNA, especially when making amends. I think he should step down and let a nicer person be Terra 2.0's frontman.
The verdict
Terra has a terrific community with an arrogant, unlikeable leader. The new LUNA chain must grow 40 times before it can start making up its losses, and even then, not everyone's losses will be covered.
I won't invest in Terra 2.0 or other algorithmic stablecoins in the near future. I won't be near any Do Kwon-related project within 100 miles. My opinion.
Can Terra 2.0 be saved? Comment below.
You might also like

Suzie Glassman
3 years ago
How I Stay Fit Despite Eating Fast Food and Drinking Alcohol
Here's me. Perfectionism is unnecessary.

This post isn't for people who gag at the prospect of eating french fries. I've been ridiculed for stating you can lose weight eating carbs and six-pack abs aren't good.
My family eats frozen processed meals and quick food most weeks (sometimes more). Clean eaters may think I'm unqualified to give fitness advice. I get it.
Hear me out, though. I’m a 44-year-old raising two busy kids with a weekly-traveling husband. Tutoring, dance, and guitar classes fill weeknights. I'm also juggling my job and freelancing.
I'm as worried and tired as my clients. I wish I ate only kale smoothies and salads. I can’t. Despite my mistakes, I'm fit. I won't promise you something just because it worked for me. But here’s a look at how I manage.
What I largely get right about eating
I have a flexible diet and track my daily intake. I count protein, fat, and carbs. Only on vacation or exceptional occasions do I not track.
My protein goal is 1 g per lb. I consume a lot of chicken breasts, eggs, turkey, and lean ground beef. I also occasionally drink protein shakes.
I eat 220–240 grams of carbs daily. My carb count depends on training volume and goals. I'm trying to lose weight slowly. If I want to lose weight faster, I cut carbs to 150-180.
My carbs include white rice, Daves Killer Bread, fruit, pasta, and veggies. I don't eat enough vegetables, so I take Athletic Greens. Also, V8.
Fat grams over 50 help me control my hormones. Recently, I've reached 70-80 grams. Cooking with olive oil. I eat daily dark chocolate. Eggs, butter, milk, and cheese contribute to the rest.
Those frozen meals? What can I say? Stouffer’s lasagna is sometimes needed. I order the healthiest fast food I can find (although I can never bring myself to order the salad). That's a chicken sandwich or a kid's hamburger. I rarely order fries. I eat slowly and savor each bite to feel full.
Potato chips and sugary cereals are in the pantry, but I'm not tempted. My kids eat them because I'd rather teach them moderation than total avoidance. If I eat them, I only eat one portion.
If you're not hungry and eating enough protein and fat, you won't want to eat everything in sight.
I drink once or twice a week. As a result, I rarely overdo it.
Food tracking is tedious and frustrating for many. Taking breaks and using estimates when eating out help. Not perfect, but realistic.
I practice a prolonged fast to enhance metabolic adaptability
Metabolic flexibility is the ability to switch between fuel sources (fat and carbs) based on activity intensity and time since eating. At rest or during low to moderate exertion, your body burns fat. Your body burns carbs after eating and during intense exercise.
Our metabolic flexibility can be hampered by lack of exercise, overeating, and stress. Our bodies become lousy fat burners, making weight loss difficult.
Once a week, I skip dinner (usually around 24 hours). Long-term fasting teaches my body to burn fat. It provides me one low-calorie day a week (I break the fast with a normal-sized dinner).
Fasting day helps me maintain my weight on weekends, when I typically overeat and drink.
Try an extended fast slowly. Delay breakfast by two hours. Next week, add two hours, etc. It takes practice to go that long without biting off your arm. I also suggest consulting your doctor.
I stay active.
I've always been active. As a child, I danced many nights a week, was on the high school dance team, and ran marathons in my 20s.
Often, I feel driven by an internal engine. Working from home makes it easy to exercise. If that’s not you, I get it. Everyone can benefit from raising their baseline.
After taking the kids to school, I walk two miles around the neighborhood. When I need to think, I switch off podcasts. First thing in the morning, I go for a walk.
I lift weights Monday, Wednesday, and Friday. 45 minutes is typical. I run 45-90 minutes on Tuesday and Thursday. I'm slow but reliable. On Saturdays and Sundays, I walk and add a short spin class if I'm not too tired.
I almost never forgo sleep.
I rarely stay up past 10 p.m., much to my night-owl husband's dismay. My 7-8-hour nights help me recover from workouts and handle stress. Without it, I'm grumpy.
I suppose sleep duration matters more than bedtime. Some people just can't fall asleep early. Internal clock and genetics determine sleep and wake hours.
Prioritize sleep.
Last thoughts
Fitness and diet advice is often useless. Some of the advice is inaccurate, dangerous, or difficult to follow if you have a life. I want to throw a shoe at my screen when I see headlines promising to speed up my metabolism or help me lose fat.
I studied exercise physiology for years. No shortcuts exist. No medications or cleanses reset metabolism. I play the hand I'm dealt. I realize that just because something works for me, it won't for you.
If I wanted 15% body fat and ripped abs, I'd have to be stricter. I occasionally think I’d like to get there. But then I remember I’m happy with my life. I like fast food and beer. Pizza and margaritas are favorites (not every day).
You can get it mostly right and live a healthy life.

Josef Cruz
3 years ago
My friend worked in a startup scam that preys on slothful individuals.
He explained everything.

A drinking buddy confessed. Alexander. He says he works at a startup based on a scam, which appears too clever to be a lie.
Alexander (assuming he developed the story) or the startup's creator must have been a genius.
This is the story of an Internet scam that targets older individuals and generates tens of millions of dollars annually.
The business sells authentic things at 10% of their market value. This firm cannot be lucrative, but the entrepreneur has a plan: monthly subscriptions to a worthless service.
The firm can then charge the customer's credit card to settle the gap. The buyer must subscribe without knowing it. What's their strategy?
How does the con operate?
Imagine a website with a split homepage. On one page, the site offers an attractive goods at a ridiculous price (from 1 euro to 10% of the product's market worth).
Same product, but with a stupid monthly subscription. Business is unsustainable. They buy overpriced products and resell them too cheaply, hoping customers will subscribe to a useless service.
No customer will want this service. So they create another illegal homepage that hides the monthly subscription offer. After an endless scroll, a box says Yes, I want to subscribe to a service that costs x dollars per month.
Unchecking the checkbox bugs. When a customer buys a product on this page, he's enrolled in a monthly subscription. Not everyone should see it because it's illegal. So what does the startup do?
A page that varies based on the sort of website visitor, a possible consumer or someone who might be watching the startup's business
Startup technicians make sure the legal page is displayed when the site is accessed normally. Typing the web address in the browser, using Google, etc. The page crashes when buying a goods, preventing the purchase.
This avoids the startup from selling a product at a loss because the buyer won't subscribe to the worthless service and charge their credit card each month.
The illegal page only appears if a customer clicks on a Google ad, indicating interest in the offer.
Alexander says that a banker, police officer, or anyone else who visits the site (maybe for control) will only see a valid and buggy site as purchases won't be possible.
The latter will go to the site in the regular method (by typing the address in the browser, using Google, etc.) and not via an online ad.
Those who visit from ads are likely already lured by the site's price. They'll be sent to an illegal page that requires a subscription.
Laziness is humanity's secret weapon. The ordinary person ignores tiny monthly credit card charges. The subscription lasts around a year before the customer sees an unexpected deduction.
After-sales service (ASS) is useful in this situation.
After-sales assistance begins when a customer notices slight changes on his credit card, usually a year later.
The customer will search Google for the direct debit reference. How he'll complain to after-sales service.
It's crucial that ASS appears in the top 4/5 Google search results. This site must be clear, and offer chat, phone, etc., he argues.
The pigeon must be comforted after waking up. The customer learns via after-sales service that he subscribed to a service while buying the product, which justifies the debits on his card.
The customer will then clarify that he didn't intend to make the direct debits. The after-sales care professional will pretend to listen to the customer's arguments and complaints, then offer to unsubscribe him for free because his predicament has affected him.
In 99% of cases, the consumer is satisfied since the after-sales support unsubscribed him for free, and he forgets the debited amounts.
The remaining 1% is split between 0.99% who are delighted to be reimbursed and 0.01%. We'll pay until they're done. The customer should be delighted, not object or complain, and keep us beneath the radar (their situation is resolved, the rest, they don’t care).
It works, so we expand our thinking.
Startup has considered industrialization. Since this fraud is working, try another. Automate! So they used a site generator (only for product modifications), underpaid phone operators for after-sales service, and interns for fresh product ideas.
The company employed a data scientist. This has allowed the startup to recognize that specific customer profiles can be re-registered in the database and that it will take X months before they realize they're subscribing to a worthless service. Customers are re-subscribed to another service, then unsubscribed before realizing it.
Alexander took months to realize the deception and leave. Lawyers and others apparently threatened him and former colleagues who tried to talk about it.
The startup would have earned prizes and competed in contests. He adds they can provide evidence to any consumer group, media, police/gendarmerie, or relevant body. When I submitted my information to the FBI, I was told, "We know, we can't do much.", he says.

DANIEL CLERY
3 years ago
Can space-based solar power solve Earth's energy problems?
Better technology and lower launch costs revive science-fiction tech.
Airbus engineers showed off sustainable energy's future in Munich last month. They captured sunlight with solar panels, turned it into microwaves, and beamed it into an airplane hangar, where it lighted a city model. The test delivered 2 kW across 36 meters, but it posed a serious question: Should we send enormous satellites to capture solar energy in space? In orbit, free of clouds and nighttime, they could create power 24/7 and send it to Earth.
Airbus engineer Jean-Dominique Coste calls it an engineering problem. “But it’s never been done at [large] scale.”
Proponents of space solar power say the demand for green energy, cheaper space access, and improved technology might change that. Once someone invests commercially, it will grow. Former NASA researcher John Mankins says it might be a trillion-dollar industry.
Myriad uncertainties remain, including whether beaming gigawatts of power to Earth can be done efficiently and without burning birds or people. Concept papers are being replaced with ground and space testing. The European Space Agency (ESA), which supported the Munich demo, will propose ground tests to member nations next month. The U.K. government offered £6 million to evaluate innovations this year. Chinese, Japanese, South Korean, and U.S. agencies are working. NASA policy analyst Nikolai Joseph, author of an upcoming assessment, thinks the conversation's tone has altered. What formerly appeared unattainable may now be a matter of "bringing it all together"
NASA studied space solar power during the mid-1970s fuel crunch. A projected space demonstration trip using 1970s technology would have cost $1 trillion. According to Mankins, the idea is taboo in the agency.
Space and solar power technology have evolved. Photovoltaic (PV) solar cell efficiency has increased 25% over the past decade, Jones claims. Telecoms use microwave transmitters and receivers. Robots designed to repair and refuel spacecraft might create solar panels.
Falling launch costs have boosted the idea. A solar power satellite large enough to replace a nuclear or coal plant would require hundreds of launches. ESA scientist Sanjay Vijendran: "It would require a massive construction complex in orbit."
SpaceX has made the idea more plausible. A SpaceX Falcon 9 rocket costs $2600 per kilogram, less than 5% of what the Space Shuttle did, and the company promised $10 per kilogram for its giant Starship, slated to launch this year. Jones: "It changes the equation." "Economics rules"
Mass production reduces space hardware costs. Satellites are one-offs made with pricey space-rated parts. Mars rover Perseverance cost $2 million per kilogram. SpaceX's Starlink satellites cost less than $1000 per kilogram. This strategy may work for massive space buildings consisting of many identical low-cost components, Mankins has long contended. Low-cost launches and "hypermodularity" make space solar power economical, he claims.
Better engineering can improve economics. Coste says Airbus's Munich trial was 5% efficient, comparing solar input to electricity production. When the Sun shines, ground-based solar arrays perform better. Studies show space solar might compete with existing energy sources on price if it reaches 20% efficiency.
Lighter parts reduce costs. "Sandwich panels" with PV cells on one side, electronics in the middle, and a microwave transmitter on the other could help. Thousands of them build a solar satellite without heavy wiring to move power. In 2020, a team from the U.S. Naval Research Laboratory (NRL) flew on the Air Force's X-37B space plane.
NRL project head Paul Jaffe said the satellite is still providing data. The panel converts solar power into microwaves at 8% efficiency, but not to Earth. The Air Force expects to test a beaming sandwich panel next year. MIT will launch its prototype panel with SpaceX in December.
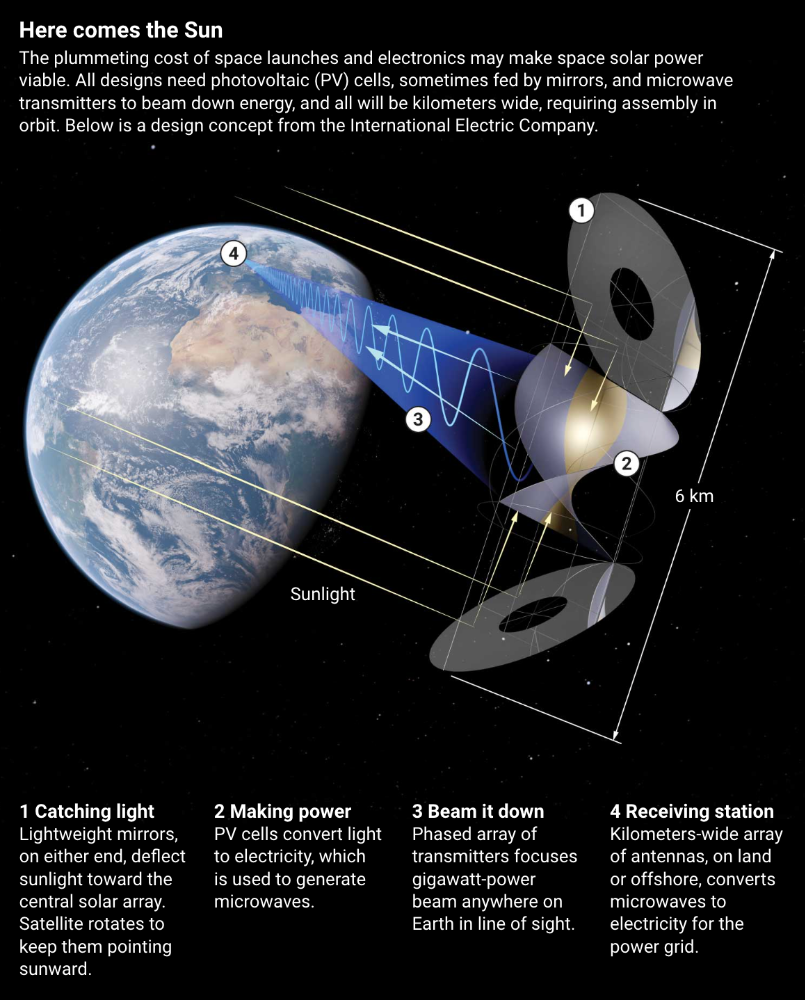
As a satellite orbits, the PV side of sandwich panels sometimes faces away from the Sun since the microwave side must always face Earth. To maintain 24-hour power, a satellite needs mirrors to keep that side illuminated and focus light on the PV. In a 2012 NASA study by Mankins, a bowl-shaped device with thousands of thin-film mirrors focuses light onto the PV array.
International Electric Company's Ian Cash has a new strategy. His proposed satellite uses enormous, fixed mirrors to redirect light onto a PV and microwave array while the structure spins (see graphic, above). 1 billion minuscule perpendicular antennas act as a "phased array" to electronically guide the beam toward Earth, regardless of the satellite's orientation. This design, argues Cash, is "the most competitive economically"
If a space-based power plant ever flies, its power must be delivered securely and efficiently. Jaffe's team at NRL just beamed 1.6 kW over 1 km, and teams in Japan, China, and South Korea have comparable attempts. Transmitters and receivers lose half their input power. Vijendran says space solar beaming needs 75% efficiency, "preferably 90%."
Beaming gigawatts through the atmosphere demands testing. Most designs aim to produce a beam kilometers wide so every ship, plane, human, or bird that strays into it only receives a tiny—hopefully harmless—portion of the 2-gigawatt transmission. Receiving antennas are cheap to build but require a lot of land, adds Jones. You could grow crops under them or place them offshore.
Europe's public agencies currently prioritize space solar power. Jones: "There's a devotion you don't see in the U.S." ESA commissioned two solar cost/benefit studies last year. Vijendran claims it might match ground-based renewables' cost. Even at a higher price, equivalent to nuclear, its 24/7 availability would make it competitive.
ESA will urge member states in November to fund a technical assessment. If the news is good, the agency will plan for 2025. With €15 billion to €20 billion, ESA may launch a megawatt-scale demonstration facility by 2030 and a gigawatt-scale facility by 2040. "Moonshot"