


LCX is the latest CEX to have suffered a private key exploit.
The attack began around 10:30 PM +UTC on January 8th.
Peckshield spotted it first, then an official announcement came shortly after.
We’ve said it before; if established companies holding millions of dollars of users’ funds can’t manage their own hot wallet security, what purpose do they serve?
The Unique Selling Proposition (USP) of centralised finance grows smaller by the day.
The official incident report states that 7.94M USD were stolen in total, and that deposits and withdrawals to the platform have been paused.
LCX hot wallet: 0x4631018f63d5e31680fb53c11c9e1b11f1503e6f
Hacker’s wallet: 0x165402279f2c081c54b00f0e08812f3fd4560a05
Stolen funds:
- 162.68 ETH (502,671 USD)
- 3,437,783.23 USDC (3,437,783 USD)
- 761,236.94 EURe (864,840 USD)
- 101,249.71 SAND Token (485,995 USD)
- 1,847.65 LINK (48,557 USD)
- 17,251,192.30 LCX Token (2,466,558 USD)
- 669.00 QNT (115,609 USD)
- 4,819.74 ENJ (10,890 USD)
- 4.76 MKR (9,885 USD)
**~$1M worth of $LCX remains in the address, along with 611k EURe which has been frozen by Monerium.
The rest, a total of 1891 ETH (~$6M) was sent to Tornado Cash.**
Why can’t they keep private keys private?
Is it really that difficult for a traditional corporate structure to maintain good practice?
CeFi hacks leave us with little to say - we can only go on what the team chooses to tell us.
Next time, they can write this article themselves.
See below for a template.
More on Web3 & Crypto

Robert Kim
2 years ago
Crypto Legislation Might Progress Beyond Talk in 2022
Financial regulators have for years attempted to apply existing laws to the multitude of issues created by digital assets. In 2021, leading federal regulators and members of Congress have begun to call for legislation to address these issues. As a result, 2022 may be the year when federal legislation finally addresses digital asset issues that have been growing since the mining of the first Bitcoin block in 2009.
Digital Asset Regulation in the Absence of Legislation
So far, Congress has left the task of addressing issues created by digital assets to regulatory agencies. Although a Congressional Blockchain Caucus formed in 2016, House and Senate members introduced few bills addressing digital assets until 2018. As of October 2021, Congress has not amended federal laws on financial regulation, which were last significantly revised by the Dodd-Frank Act in 2010, to address digital asset issues.
In the absence of legislation, issues that do not fit well into existing statutes have created problems. An example is the legal status of digital assets, which can be considered to be either securities or commodities, and can even shift from one to the other over time. Years after the SEC’s 2017 report applying the definition of a security to digital tokens, the SEC and the CFTC have yet to clarify the distinction between securities and commodities for the thousands of digital assets in existence.
SEC Chair Gary Gensler has called for Congress to act, stating in August, “We need additional Congressional authorities to prevent transactions, products, and platforms from falling between regulatory cracks.” Gensler has reached out to Sen. Elizabeth Warren (D-Ma.), who has expressed her own concerns about the need for legislation.
Legislation on Digital Assets in 2021
While regulators and members of Congress talked about the need for legislation, and the debate over cryptocurrency tax reporting in the 2021 infrastructure bill generated headlines, House and Senate bills proposing specific solutions to various issues quietly started to emerge.
Digital Token Sales
Several House bills attempt to address securities law barriers to digital token sales—some of them by building on ideas proposed by regulators in past years.
Exclusion from the definition of a security. Congressional Blockchain Caucus members have been introducing bills to exclude digital tokens from the definition of a security since 2018, and they have revived those bills in 2021. They include the Token Taxonomy Act of 2021 (H.R. 1628), successor to identically named bills in 2018 and 2019, and the Securities Clarity Act (H.R. 4451), successor to a 2020 namesake.
Safe harbor. SEC Commissioner Hester Peirce proposed a regulatory safe harbor for token sales in 2020, and two 2021 bills have proposed statutory safe harbors. Rep. Patrick McHenry (R-N.C.), Republican leader of the House Financial Services Committee, introduced a Clarity for Digital Tokens Act of 2021 (H.R. 5496) that would amend the Securities Act to create a safe harbor providing a grace period of exemption from Securities Act registration requirements. The Digital Asset Market Structure and Investor Protection Act (H.R. 4741) from Rep. Don Beyer (D-Va.) would amend the Securities Exchange Act to define a new type of security—a “digital asset security”—and add issuers of digital asset securities to an existing provision for delayed registration of securities.
Stablecoins
Stablecoins—digital currencies linked to the value of the U.S. dollar or other fiat currencies—have not yet been the subject of regulatory action, although Treasury Secretary Janet Yellen and Federal Reserve Chair Jerome Powell have each underscored the need to create a regulatory framework for them. The Beyer bill proposes to create a regulatory regime for stablecoins by amending Title 31 of the U.S. Code. Treasury Department approval would be required for any “digital asset fiat-based stablecoin” to be issued or used, under an application process to be established by Treasury in consultation with the Federal Reserve, the SEC, and the CFTC.
Serious consideration for any of these proposals in the current session of Congress may be unlikely. A spate of autumn bills on crypto ransom payments (S. 2666, S. 2923, S. 2926, H.R. 5501) shows that Congress is more inclined to pay attention first to issues that are more spectacular and less arcane. Moreover, the arcaneness of digital asset regulatory issues is likely only to increase further, now that major industry players such as Coinbase and Andreessen Horowitz are starting to roll out their own regulatory proposals.
Digital Dollar vs. Digital Yuan
Impetus to pass legislation on another type of digital asset, a central bank digital currency (CBDC), may come from a different source: rivalry with China.
China established itself as a world leader in developing a CBDC with a pilot project launched in 2020, and in 2021, the People’s Bank of China announced that its CBDC will be used at the Beijing Winter Olympics in February 2022. Republican Senators responded by calling for the U.S. Olympic Committee to forbid use of China’s CBDC by U.S. athletes in Beijing and introducing a bill (S. 2543) to require a study of its national security implications.
The Beijing Olympics could motivate a legislative mandate to accelerate implementation of a U.S. digital dollar, which the Federal Reserve has been in the process of considering in 2021. Antecedents to such legislation already exist. A House bill sponsored by 46 Republicans (H.R. 4792) has a provision that would require the Treasury Department to assess China’s CBDC project and report on the status of Federal Reserve work on a CBDC, and the Beyer bill includes a provision amending the Federal Reserve Act to authorize issuing a digital dollar.
Both parties are likely to support creating a digital dollar. The Covid-19 pandemic made a digital dollar for delivery of relief payments a popular idea in 2020, and House Democrats introduced bills with provisions for creating one in 2020 and 2021. Bipartisan support for a bill on a digital dollar, based on concerns both foreign and domestic in nature, could result.
International rivalry and bipartisan support may make the digital dollar a gateway issue for digital asset legislation in 2022. Legislative work on a digital dollar may open the door for considering further digital asset issues—including the regulatory issues that have been emerging for years—in 2022 and beyond.

Juxtathinka
2 years ago
Why Is Blockchain So Popular?
What is Bitcoin?
The blockchain is a shared, immutable ledger that helps businesses record transactions and track assets. The blockchain can track tangible assets like cars, houses, and land. Tangible assets like intellectual property can also be tracked on the blockchain.
Imagine a blockchain as a distributed database split among computer nodes. A blockchain stores data in blocks. When a block is full, it is closed and linked to the next. As a result, all subsequent information is compiled into a new block that will be added to the chain once it is filled.
The blockchain is designed so that adding a transaction requires consensus. That means a majority of network nodes must approve a transaction. No single authority can control transactions on the blockchain. The network nodes use cryptographic keys and passwords to validate each other's transactions.
Blockchain History
The blockchain was not as popular in 1991 when Stuart Haber and W. Scott Stornetta worked on it. The blocks were designed to prevent tampering with document timestamps. Stuart Haber and W. Scott Stornetta improved their work in 1992 by using Merkle trees to increase efficiency and collect more documents on a single block.
In 2004, he developed Reusable Proof of Work. This system allows users to verify token transfers in real time. Satoshi Nakamoto invented distributed blockchains in 2008. He improved the blockchain design so that new blocks could be added to the chain without being signed by trusted parties.
Satoshi Nakomoto mined the first Bitcoin block in 2009, earning 50 Bitcoins. Then, in 2013, Vitalik Buterin stated that Bitcoin needed a scripting language for building decentralized applications. He then created Ethereum, a new blockchain-based platform for decentralized apps. Since the Ethereum launch in 2015, different blockchain platforms have been launched: from Hyperledger by Linux Foundation, EOS.IO by block.one, IOTA, NEO and Monero dash blockchain. The block chain industry is still growing, and so are the businesses built on them.
Blockchain Components
The Blockchain is made up of many parts:
1. Node: The node is split into two parts: full and partial. The full node has the authority to validate, accept, or reject any transaction. Partial nodes or lightweight nodes only keep the transaction's hash value. It doesn't keep a full copy of the blockchain, so it has limited storage and processing power.
2. Ledger: A public database of information. A ledger can be public, decentralized, or distributed. Anyone on the blockchain can access the public ledger and add data to it. It allows each node to participate in every transaction. The distributed ledger copies the database to all nodes. A group of nodes can verify transactions or add data blocks to the blockchain.
3. Wallet: A blockchain wallet allows users to send, receive, store, and exchange digital assets, as well as monitor and manage their value. Wallets come in two flavors: hardware and software. Online or offline wallets exist. Online or hot wallets are used when online. Without an internet connection, offline wallets like paper and hardware wallets can store private keys and sign transactions. Wallets generally secure transactions with a private key and wallet address.
4. Nonce: A nonce is a short term for a "number used once''. It describes a unique random number. Nonces are frequently generated to modify cryptographic results. A nonce is a number that changes over time and is used to prevent value reuse. To prevent document reproduction, it can be a timestamp. A cryptographic hash function can also use it to vary input. Nonces can be used for authentication, hashing, or even electronic signatures.
5. Hash: A hash is a mathematical function that converts inputs of arbitrary length to outputs of fixed length. That is, regardless of file size, the hash will remain unique. A hash cannot generate input from hashed output, but it can identify a file. Hashes can be used to verify message integrity and authenticate data. Cryptographic hash functions add security to standard hash functions, making it difficult to decipher message contents or track senders.
Blockchain: Pros and Cons
The blockchain provides a trustworthy, secure, and trackable platform for business transactions quickly and affordably. The blockchain reduces paperwork, documentation errors, and the need for third parties to verify transactions.
Blockchain security relies on a system of unaltered transaction records with end-to-end encryption, reducing fraud and unauthorized activity. The blockchain also helps verify the authenticity of items like farm food, medicines, and even employee certification. The ability to control data gives users a level of privacy that no other platform can match.
In the case of Bitcoin, the blockchain can only handle seven transactions per second. Unlike Hyperledger and Visa, which can handle ten thousand transactions per second. Also, each participant node must verify and approve transactions, slowing down exchanges and limiting scalability.
The blockchain requires a lot of energy to run. In addition, the blockchain is not a hugely distributable system and it is destructible. The security of the block chain can be compromised by hackers; it is not completely foolproof. Also, since blockchain entries are immutable, data cannot be removed. The blockchain's high energy consumption and limited scalability reduce its efficiency.
Why Is Blockchain So Popular?
The blockchain is a technology giant. In 2018, 90% of US and European banks began exploring blockchain's potential. In 2021, 24% of companies are expected to invest $5 million to $10 million in blockchain. By the end of 2024, it is expected that corporations will spend $20 billion annually on blockchain technical services.
Blockchain is used in cryptocurrency, medical records storage, identity verification, election voting, security, agriculture, business, and many other fields. The blockchain offers a more secure, decentralized, and less corrupt system of making global payments, which cryptocurrency enthusiasts love. Users who want to save time and energy prefer it because it is faster and less bureaucratic than banking and healthcare systems.
Most organizations have jumped on the blockchain bandwagon, and for good reason: the blockchain industry has never had more potential. The launch of IBM's Blockchain Wire, Paystack, Aza Finance and Bloom are visible proof of the wonders that the blockchain has done. The blockchain's cryptocurrency segment may not be as popular in the future as the blockchain's other segments, as evidenced by the various industries where it is used. The blockchain is here to stay, and it will be discussed for a long time, not just in tech, but in many industries.
Read original post here

Elnaz Sarraf
2 years ago
Why Bitcoin's Crash Could Be Good for Investors

The crypto market crashed in June 2022. Bitcoin and other cryptocurrencies hit their lowest prices in over a year, causing market panic. Some believe this crash will benefit future investors.
Before I discuss how this crash might help investors, let's examine why it happened. Inflation in the U.S. reached a 30-year high in 2022 after Russia invaded Ukraine. In response, the U.S. Federal Reserve raised interest rates by 0.5%, the most in almost 20 years. This hurts cryptocurrencies like Bitcoin. Higher interest rates make people less likely to invest in volatile assets like crypto, so many investors sold quickly.
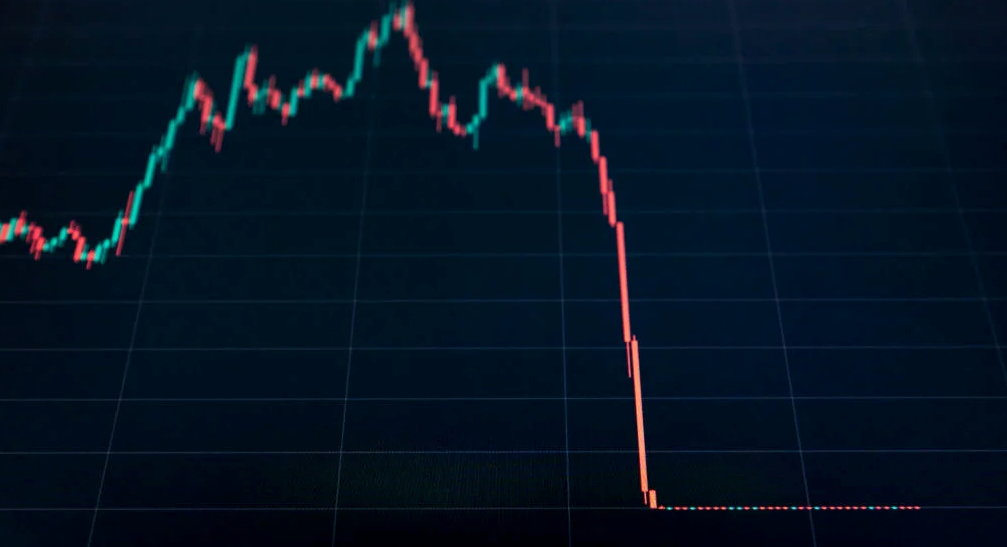
The crypto market collapsed. Bitcoin, Ethereum, and Binance dropped 40%. Other cryptos crashed so hard they were delisted from almost every exchange. Bitcoin peaked in April 2022 at $41,000, but after the May interest rate hike, it crashed to $28,000. Bitcoin investors were worried. Even in bad times, this crash is unprecedented.
Bitcoin wasn't "doomed." Before the crash, LUNA was one of the top 5 cryptos by market cap. LUNA was trading around $80 at the start of May 2022, but after the rate hike?
Less than 1 cent. LUNA lost 99.99% of its value in days and was removed from every crypto exchange. Bitcoin's "crash" isn't as devastating when compared to LUNA.
Many people said Bitcoin is "due" for a LUNA-like crash and that the only reason it hasn't crashed is because it's bigger. Still false. If so, Bitcoin should be worth zero by now. We didn't. Instead, Bitcoin reached 28,000, then 29k, 30k, and 31k before falling to 18k. That's not the world's greatest recovery, but it shows Bitcoin's safety.
Bitcoin isn't falling constantly. It fell because of the initial shock of interest rates, but not further. Now, Bitcoin's value is more likely to rise than fall. Bitcoin's low price also attracts investors. They know what prices Bitcoin can reach with enough hype, and they want to capitalize on low prices before it's too late.

Bitcoin's crash was bad, but in a way it wasn't. To understand, consider 2021. In March 2021, Bitcoin surpassed $60k for the first time. Elon Musk's announcement in May that he would no longer support Bitcoin caused a massive crash in the crypto market. In May 2017, Bitcoin's price hit $29,000. Elon Musk's statement isn't worth more than the Fed raising rates. Many expected this big announcement to kill Bitcoin.

Not so. Bitcoin crashed from $58k to $31k in 2021. Bitcoin fell from $41k to $28k in 2022. This crash is smaller. Bitcoin's price held up despite tensions and stress, proving investors still believe in it. What happened after the initial crash in the past?
Bitcoin fell until mid-July. This is also something we’re not seeing today. After a week, Bitcoin began to improve daily. Bitcoin's price rose after mid-July. Bitcoin's price fluctuated throughout the rest of 2021, but it topped $67k in November. Despite no major changes, the peak occurred after the crash. Elon Musk seemed uninterested in crypto and wasn't likely to change his mind soon. What triggered this peak? Nothing, really. What really happened is that people got over the initial statement. They forgot.
Internet users have goldfish-like attention spans. People quickly forgot the crash's cause and were back investing in crypto months later. Despite the market's setbacks, more crypto investors emerged by the end of 2017. Who gained from these peaks? Bitcoin investors who bought low. Bitcoin not only recovered but also doubled its ROI. It was like a movie, and it shows us what to expect from Bitcoin in the coming months.
The current Bitcoin crash isn't as bad as the last one. LUNA is causing market panic. LUNA and Bitcoin are different cryptocurrencies. LUNA crashed because Terra wasn’t able to keep its peg with the USD. Bitcoin is unanchored. It's one of the most decentralized investments available. LUNA's distrust affected crypto prices, including Bitcoin, but it won't last forever.
This is why Bitcoin will likely rebound in the coming months. In 2022, people will get over the rise in interest rates and the crash of LUNA, just as they did with Elon Musk's crypto stance in 2021. When the world moves on to the next big controversy, Bitcoin's price will soar.
Bitcoin may recover for another reason. Like controversy, interest rates fluctuate. The Russian invasion caused this inflation. World markets will stabilize, prices will fall, and interest rates will drop.
Next, lower interest rates could boost Bitcoin's price. Eventually, it will happen. The U.S. economy can't sustain such high interest rates. Investors will put every last dollar into Bitcoin if interest rates fall again.
Bitcoin has proven to be a stable investment. This boosts its investment reputation. Even if Ethereum dethrones Bitcoin as crypto king one day (or any other crypto, for that matter). Bitcoin may stay on top of the crypto ladder for a while. We'll have to wait a few months to see if any of this is true.
This post is a summary. Read the full article here.
You might also like

Alex Mathers
1 year ago
400 articles later, nobody bothered to read them.
Writing for readers:
14 years of daily writing.
I post practically everything on social media. I authored hundreds of articles, thousands of tweets, and numerous volumes to almost no one.
Tens of thousands of readers regularly praise me.
I despised writing. I'm stuck now.
I've learned what readers like and what doesn't.
Here are some essential guidelines for writing with impact:
Readers won't understand your work if you can't.
Though obvious, this slipped me up. Share your truths.
Stories engage human brains.
Showing the journey of a person from worm to butterfly inspires the human spirit.
Overthinking hinders powerful writing.
The best ideas come from inner understanding in between thoughts.
Avoid writing to find it. Write.
Writing a masterpiece isn't motivating.
Write for five minutes to simplify. Step-by-step, entertaining, easy steps.
Good writing requires a willingness to make mistakes.
So write loads of garbage that you can edit into a good piece.
Courageous writing.
A courageous story will move readers. Personal experience is best.
Go where few dare.
Templates, outlines, and boundaries help.
Limitations enhance writing.
Excellent writing is straightforward and readable, removing all the unnecessary fat.
Use five words instead of nine.
Use ordinary words instead of uncommon ones.
Readers desire relatability.
Too much perfection will turn it off.
Write to solve an issue if you can't think of anything to write.
Instead, read to inspire. Best authors read.
Every tweet, thread, and novel must have a central idea.
What's its point?
This can make writing confusing.
️ Don't direct your reader.
Readers quit reading. Demonstrate, describe, and relate.
Even if no one responds, have fun. If you hate writing it, the reader will too.

James White
1 year ago
Ray Dalio suggests reading these three books in 2022.
An inspiring reading list

I'm no billionaire or hedge-fund manager. My bank account doesn't have millions. Ray Dalio's love of reading motivates me to think differently.
Here are some books recommended by Ray Dalio. Each influenced me. Hope they'll help you.
Sapiens by Yuval Noah Harari
Page Count: 512
Rating on Goodreads: 4.39
My favorite nonfiction book.
Sapiens explores human evolution. It explains how Homo Sapiens developed from hunter-gatherers to a dominant species. Amazing!
Sapiens will teach you about human history. Yuval Noah Harari has a follow-up book on human evolution.

My favorite book quotes are:
The tendency for luxuries to turn into necessities and give rise to new obligations is one of history's few unbreakable laws.
Happiness is not dependent on material wealth, physical health, or even community. Instead, it depends on how closely subjective expectations and objective circumstances align.
The romantic comparison between today's industry, which obliterates the environment, and our forefathers, who coexisted well with nature, is unfounded. Homo sapiens held the record among all organisms for eradicating the most plant and animal species even before the Industrial Revolution. The unfortunate distinction of being the most lethal species in the history of life belongs to us.
The Power Of Habit by Charles Duhigg
Page Count: 375
Rating on Goodreads: 4.13
Great book: The Power Of Habit. It illustrates why habits are everything. The book explains how healthier habits can improve your life, career, and society.
The Power of Habit rocks. It's a great book on productivity. Its suggestions helped me build healthier behaviors (and drop bad ones).
Read ASAP!

My favorite book quotes are:
Change may not occur quickly or without difficulty. However, almost any behavior may be changed with enough time and effort.
People who exercise begin to eat better and produce more at work. They are less smokers and are more patient with friends and family. They claim to feel less anxious and use their credit cards less frequently. A fundamental habit that sparks broad change is exercise.
Habits are strong but also delicate. They may develop independently of our awareness or may be purposefully created. They frequently happen without our consent, but they can be altered by changing their constituent pieces. They have a much greater influence on how we live than we realize; in fact, they are so powerful that they cause our brains to adhere to them above all else, including common sense.
Tribe Of Mentors by Tim Ferriss
Page Count: 561
Rating on Goodreads: 4.06
Unusual book structure. It's worth reading if you want to learn from successful people.
The book is Q&A-style. Tim questions everyone. Each chapter features a different person's life-changing advice. In the book, Pressfield, Willink, Grylls, and Ravikant are interviewed.
Amazing!

My favorite book quotes are:
According to one's courage, life can either get smaller or bigger.
Don't engage in actions that you are aware are immoral. The reputation you have with yourself is all that constitutes self-esteem. Always be aware.
People mistakenly believe that focusing means accepting the task at hand. However, that is in no way what it represents. It entails rejecting the numerous other worthwhile suggestions that exist. You must choose wisely. Actually, I'm just as proud of the things we haven't accomplished as I am of what I have. Saying no to 1,000 things is what innovation is.

Saskia Ketz
1 year ago
I hate marketing for my business, but here's how I push myself to keep going
Start now.

When it comes to building my business, I’m passionate about a lot of things. I love creating user experiences that simplify branding essentials. I love creating new typefaces and color combinations to inspire logo designers. I love fixing problems to improve my product.
Business marketing isn't my thing.
This is shared by many. Many solopreneurs, like me, struggle to advertise their business and drive themselves to work on it.
Without a lot of promotion, no company will succeed. Marketing is 80% of developing a firm, and when you're starting out, it's even more. Some believe that you shouldn't build anything until you've begun marketing your idea and found enough buyers.
Marketing your business without marketing experience is difficult. There are various outlets and techniques to learn. Instead of figuring out where to start, it's easier to return to your area of expertise, whether that's writing, designing product features, or improving your site's back end. Right?
First, realize that your role as a founder is to market your firm. Being a founder focused on product, I rarely work on it.
Secondly, use these basic methods that have helped me dedicate adequate time and focus to marketing. They're all simple to apply, and they've increased my business's visibility and success.
1. Establish buckets for every task.
You've probably heard to schedule tasks you don't like. As simple as it sounds, blocking a substantial piece of my workday for marketing duties like LinkedIn or Twitter outreach, AppSumo customer support, or SEO has forced me to spend time on them.
Giving me lots of room to focus on product development has helped even more. Sure, this means scheduling time to work on product enhancements after my four-hour marketing sprint.
It also involves making space to store product inspiration and ideas throughout the day so I don't get distracted. This is like the advice to keep a notebook beside your bed to write down your insomniac ideas. I keep fonts, color palettes, and product ideas in folders on my desktop. Knowing these concepts won't be lost lets me focus on marketing in the moment. When I have limited time to work on something, I don't have to conduct the research I've been collecting, so I can get more done faster.
2. Look for various accountability systems
Accountability is essential for self-discipline. To keep focused on my marketing tasks, I've needed various streams of accountability, big and little.
Accountability groups are great for bigger things. SaaS Camp, a sales outreach coaching program, is mine. We discuss marketing duties and results every week. This motivates me to do enough each week to be proud of my accomplishments. Yet hearing what works (or doesn't) for others gives me benchmarks for my own marketing outcomes and plenty of fresh techniques to attempt.
… say, I want to DM 50 people on Twitter about my product — I get that many Q-tips and place them in one pen holder on my desk.
The best accountability group can't watch you 24/7. I use a friend's simple method that shouldn't work (but it does). When I have a lot of marketing chores, like DMing 50 Twitter users about my product, That many Q-tips go in my desk pen holder. After each task, I relocate one Q-tip to an empty pen holder. When you have a lot of minor jobs to perform, it helps to see your progress. You might use toothpicks, M&Ms, or anything else you have a lot of.

3. Continue to monitor your feedback loops
Knowing which marketing methods work best requires monitoring results. As an entrepreneur with little go-to-market expertise, every tactic I pursue is an experiment. I need to know how each trial is doing to maximize my time.
I placed Google and Facebook advertisements on hold since they took too much time and money to obtain Return. LinkedIn outreach has been invaluable to me. I feel that talking to potential consumers one-on-one is the fastest method to grasp their problem areas, figure out my messaging, and find product market fit.
Data proximity offers another benefit. Seeing positive results makes it simpler to maintain doing a work you don't like. Why every fitness program tracks progress.
Marketing's goal is to increase customers and revenues, therefore I've found it helpful to track those metrics and celebrate monthly advances. I provide these updates for extra accountability.
Finding faster feedback loops is also motivating. Marketing brings more clients and feedback, in my opinion. Product-focused founders love that feedback. Positive reviews make me proud that my product is benefitting others, while negative ones provide me with suggestions for product changes that can improve my business.
The best advice I can give a lone creator who's afraid of marketing is to just start. Start early to learn by doing and reduce marketing stress. Start early to develop habits and successes that will keep you going. The sooner you start, the sooner you'll have enough consumers to return to your favorite work.