


Pixelmon NFTs are so bad, they are almost good!
Bored Apes prices continue to rise, HAPEBEAST launches, Invisible Friends hype continues to grow. Sadly, not all projects are as successful.
Of course, there are many factors to consider when buying an NFT. Is the project a scam? Will the reveal derail the project? Possibly, but when Pixelmon first teased its launch, it generated a lot of buzz.
With a primary sale mint price of 3 ETH ($8,100 USD), it started as an expensive project, with plenty of fans willing to invest in what was sold as a game. After it was revealed, it fell rapidly.
Why? It was overpromised and under delivered.
According to the project's creator[^1], the funds generated will be used to develop the artwork. "The Pixelmon reveal was wrong. This is what our Pixelmon look like in-game. "Despite the fud, I will not go anywhere," he wrote on Twitter. The goal remains. The funds will still be used to build our game. I will finish this project."
The project raised $70 million USD, but the NFTs buyers received were not the project's original teasers. Some call it "the worst NFT project ever," while others call it a complete scam.
But there's hope for some buyers. Kevin emerged from the ashes as the project was roasted over the fire.
A Minecraft character meets Salad Fingers - that's Kevin. He's a frog-like creature whose reveal was such a terrible NFT that it became part of history – and a meme.
If you're laughing at people paying $8K for a silly pixelated image, you might need to take it back. Precisely because of this, lucky holders who minted Kevin have been able to sell the now-memed NFT for over 8 ETH (around $24,000 USD), with some currently listed for 100 ETH.
Of course, Twitter has been awash in memes mocking those who invested in the project, because what else can you do when so many people lose money?
It's still unclear if the NFT project is a scam, but the team behind it was hired on Upwork. There's still hope for redemption, but Kevin's rise to fame appears to be the only positive outcome so far.
[^1] This is not the first time the creator (A 20-yo New Zealanders) has sought money via an online platform and had people claiming he under-delivered. He raised $74,000 on Kickstarter for a card game called Psycho Chicken. There are hundreds of comments on the Kickstarter project saying they haven't received the product and pleading for a refund or an update.
More on NFTs & Art

Boris Müller
3 years ago
Why Do Websites Have the Same Design?
My kids redesigned the internet because it lacks inventiveness.

Internet today is bland. Everything is generic: fonts, layouts, pages, and visual language. Microtypography is messy.
Web design today seems dictated by technical and ideological constraints rather than creativity and ideas. Text and graphics are in containers on every page. All design is assumed.
Ironically, web technologies can design a lot. We can execute most designs. We make shocking, evocative websites. Experimental typography, generating graphics, and interactive experiences are possible.
Even designer websites use containers in containers. Dribbble and Behance, the two most popular creative websites, are boring. Lead image.
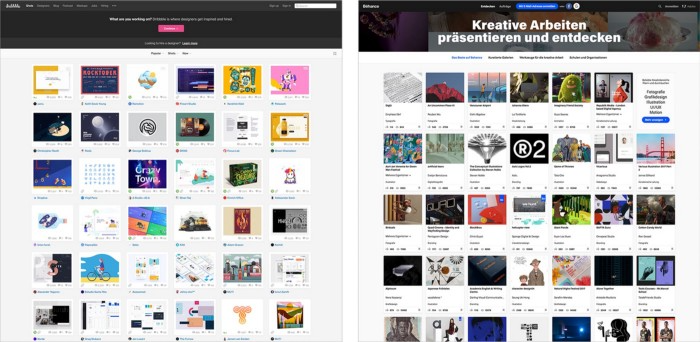
How did this happen?
Several reasons. WordPress and other blogging platforms use templates. These frameworks build web pages by combining graphics, headlines, body content, and videos. Not designs, templates. These rules combine related data types. These platforms don't let users customize pages beyond the template. You filled the template.
Templates are content-neutral. Thus, the issue.
Form should reflect and shape content, which is a design principle. Separating them produces content containers. Templates have no design value.
One of the fundamental principles of design is a deep and meaningful connection between form and content.
Web design lacks imagination for many reasons. Most are pragmatic and economic. Page design takes time. Large websites lack the resources to create a page from scratch due to the speed of internet news and the frequency of new items. HTML, JavaScript, and CSS continue to challenge web designers. Web design can't match desktop publishing's straightforward operations.
Designers may also be lazy. Mobile-first, generic, framework-driven development tends to ignore web page visual and contextual integrity.
How can we overcome this? How might expressive and avant-garde websites look today?
Rediscovering the past helps design the future.
'90s-era web design
At the University of the Arts Bremen's research and development group, I created my first website 23 years ago. Web design was trendy. Young web. Pages inspired me.
We struggled with HTML in the mid-1990s. Arial, Times, and Verdana were the only web-safe fonts. Anything exciting required table layouts, monospaced fonts, or GIFs. HTML was originally content-driven, thus we had to work against it to create a page.
Experimental typography was booming. Designers challenged the established quo from Jan Tschichold's Die Neue Typographie in the twenties to April Greiman's computer-driven layouts in the eighties. By the mid-1990s, an uncommon confluence of technological and cultural breakthroughs enabled radical graphic design. Irma Boom, David Carson, Paula Scher, Neville Brody, and others showed it.
Early web pages were dull compared to graphic design's aesthetic explosion. The Web Design Museum shows this.
Nobody knew how to conduct browser-based graphic design. Web page design was undefined. No standards. No CMS (nearly), CSS, JS, video, animation.
Now is as good a time as any to challenge the internet’s visual conformity.
In 2018, everything is browser-based. Massive layouts to micro-typography, animation, and video. How do we use these great possibilities? Containerized containers. JavaScript-contaminated mobile-first pages. Visually uniform templates. Web design 23 years later would disappoint my younger self.
Our imagination, not technology, restricts web design. We're too conformist to aesthetics, economics, and expectations.
Crisis generates opportunity. Challenge online visual conformity now. I'm too old and bourgeois to develop a radical, experimental, and cutting-edge website. I can ask my students.
I taught web design at the Potsdam Interface Design Programme in 2017. Each team has to redesign a website. Create expressive, inventive visual experiences on the browser. Create with contemporary web technologies. Avoid usability, readability, and flexibility concerns. Act. Ignore Erwartungskonformität.
The class outcome pleased me. This overview page shows all results. Four diverse projects address the challenge.
1. ZKM by Frederic Haase and Jonas Köpfer
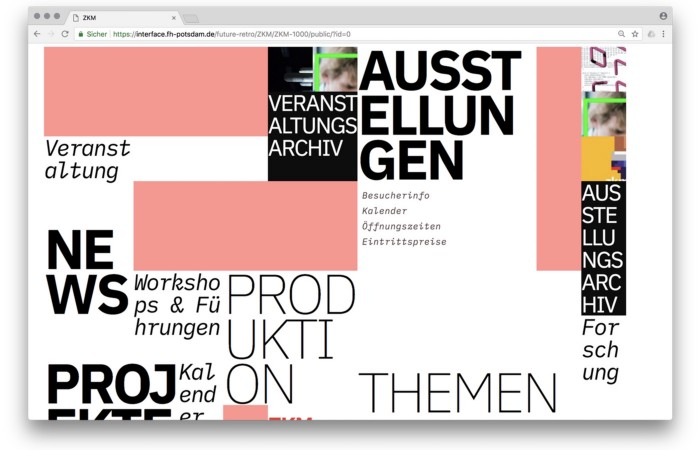
Frederic and Jonas began their experiments on the ZKM website. The ZKM is Germany's leading media art exhibition location, but its website remains conventional. It's useful but not avant-garde like the shows' art.
Frederic and Jonas designed the ZKM site's concept, aesthetic language, and technical configuration to reflect the museum's progressive approach. A generative design engine generates new layouts for each page load.
ZKM redesign.
2. Streem by Daria Thies, Bela Kurek, and Lucas Vogel

Street art magazine Streem. It promotes new artists and societal topics. Streem includes artwork, painting, photography, design, writing, and journalism. Daria, Bela, and Lucas used these influences to develop a conceptual metropolis. They designed four neighborhoods to reflect magazine sections for their prototype. For a legible city, they use powerful illustrative styles and spatial typography.
Streem makeover.
3. Medium by Amelie Kirchmeyer and Fabian Schultz
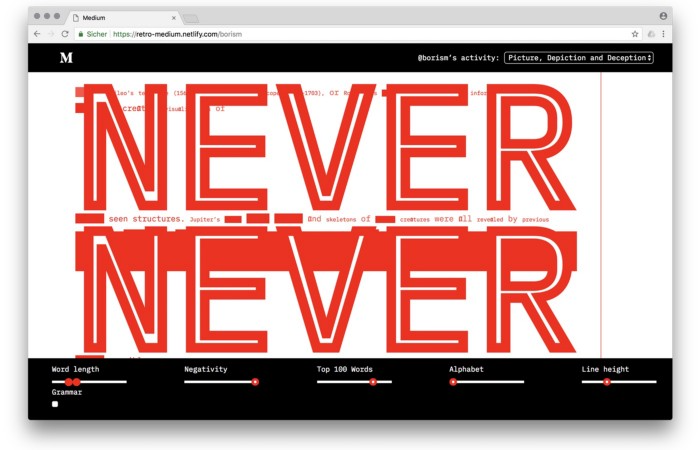
Amelie and Fabian structured. Instead of developing a form for a tale, they dissolved a web page into semantic, syntactical, and statistical aspects. HTML's flexibility was their goal. They broke Medium posts into experimental typographic space.
Medium revamp.
4. Hacker News by Fabian Dinklage and Florian Zia
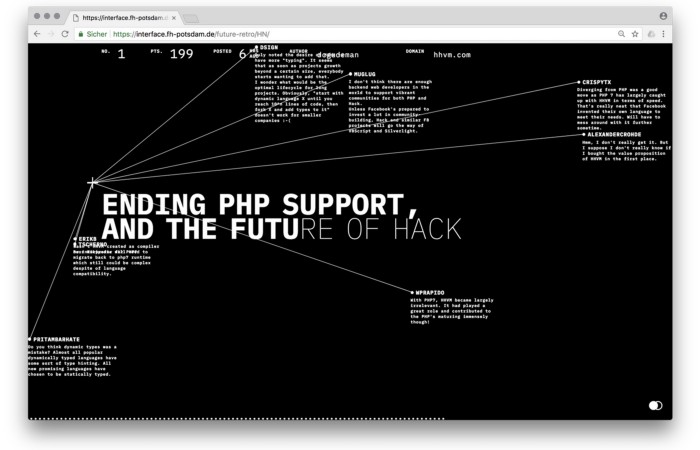
Florian and Fabian made Hacker News interactive. The social networking site aggregates computer science and IT news. Its voting and debate features are extensive despite its simple style. Fabian and Florian transformed the structure into a typographic timeline and network area. News and comments sequence and connect the visuals. To read Hacker News, they connected their design to the API. Hacker News makeover.
Communication is not legibility, said Carson. Apply this to web design today. Modern websites must be legible, usable, responsive, and accessible. They shouldn't limit its visual palette. Visual and human-centered design are not stereotypes.
I want radical, generative, evocative, insightful, adequate, content-specific, and intelligent site design. I want to rediscover web design experimentation. More surprises please. I hope the web will appear different in 23 years.
Update: this essay has sparked a lively discussion! I wrote a brief response to the debate's most common points: Creativity vs. Usability

shivsak
3 years ago
A visual exploration of the REAL use cases for NFTs in the Future

In this essay, I studied REAL NFT use examples and their potential uses.
Knowledge of the Hype Cycle
Gartner's Hype Cycle.
It proposes 5 phases for disruptive technology.
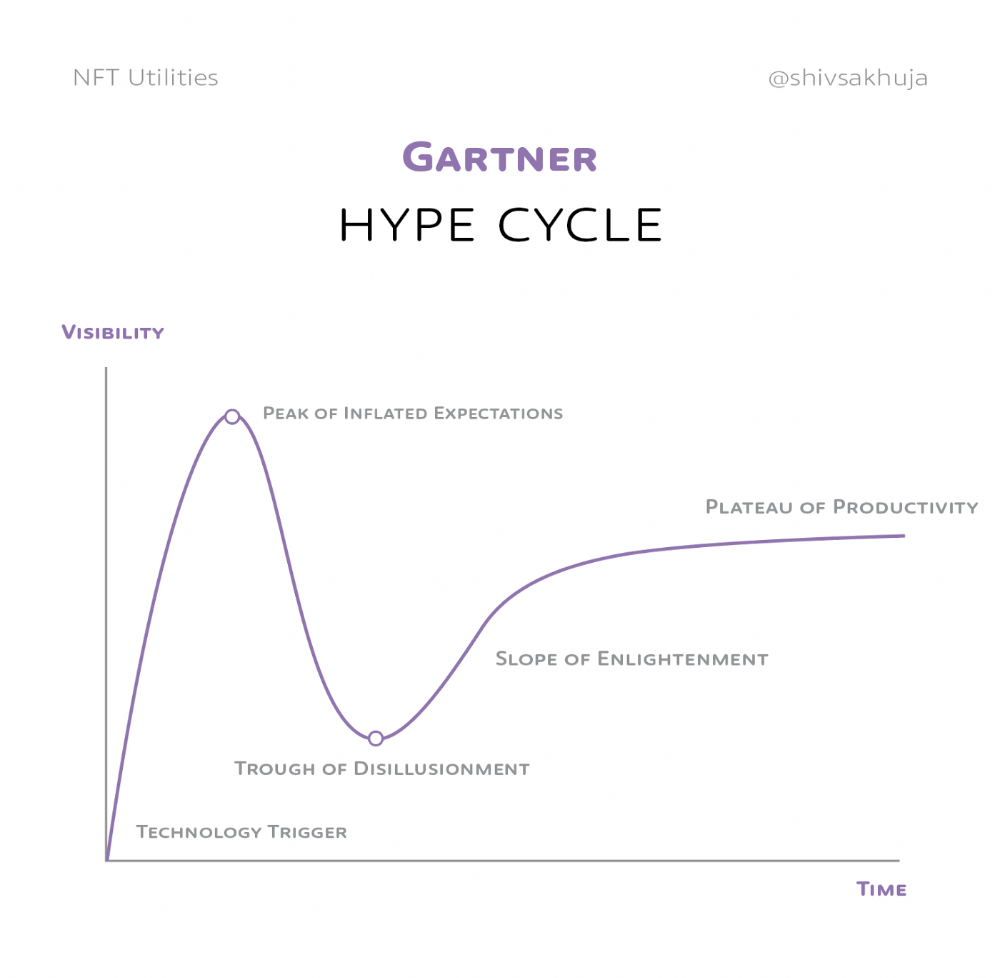
1. Technology Trigger: the emergence of potentially disruptive technology.
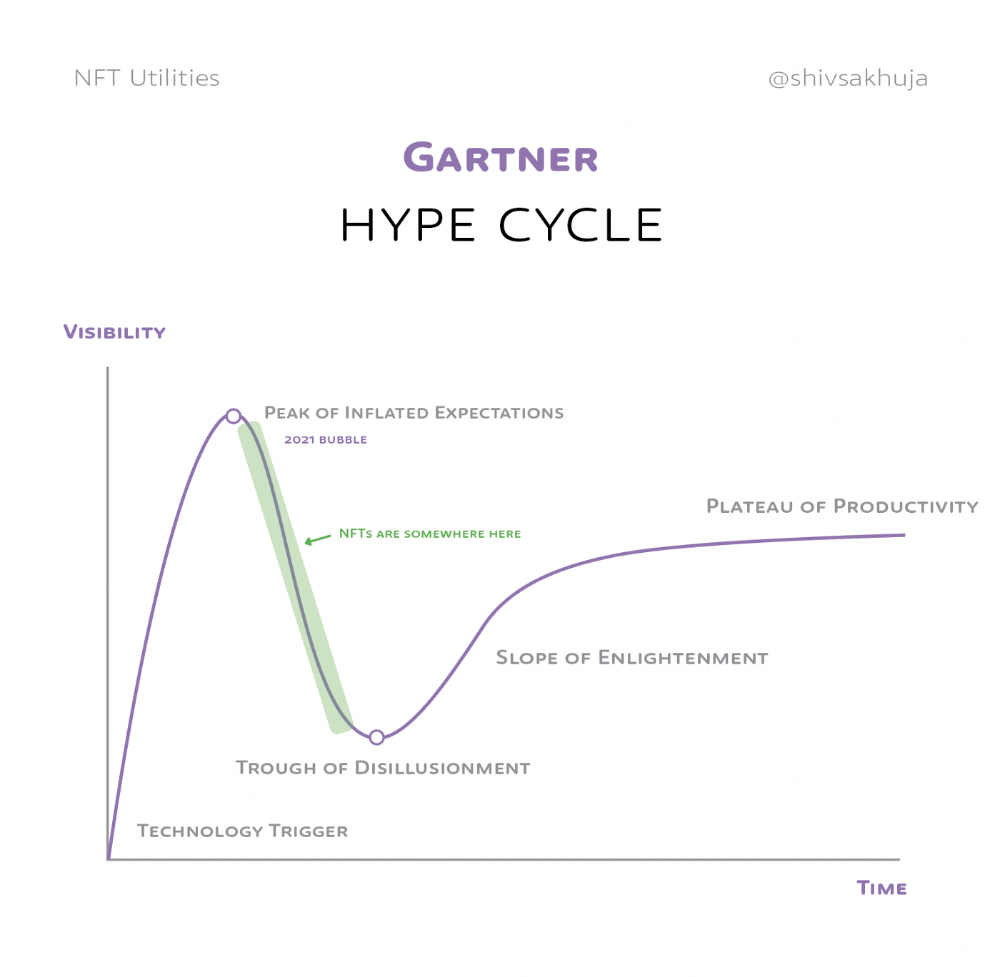
2. Peak of Inflated Expectations: Early publicity creates hype. (Ex: 2021 Bubble)
3. Trough of Disillusionment: Early projects fail to deliver on promises and the public loses interest. I suspect NFTs are somewhere around this trough of disillusionment now.
4. Enlightenment slope: The tech shows successful use cases.
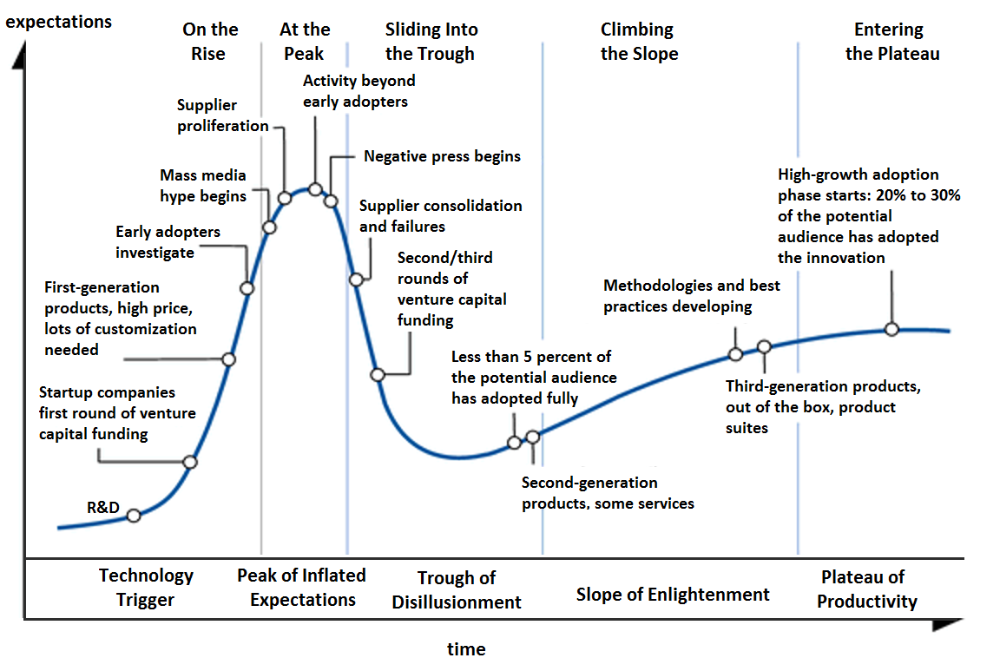
5. Plateau of Productivity: Mainstream adoption has arrived and broader market applications have proven themselves. Here’s a more detailed visual of the Gartner Hype Cycle from Wikipedia.
In the speculative NFT bubble of 2021, @beeple sold Everydays: the First 5000 Days for $69 MILLION in 2021's NFT bubble.
@nbatopshot sold millions in video collectibles.
This is when expectations peaked.
Let's examine NFTs' real-world applications.
Watch this video if you're unfamiliar with NFTs.
Online Art
Most people think NFTs are rich people buying worthless JPEGs and MP4s.
Digital artwork and collectibles are revolutionary for creators and enthusiasts.
NFT Profile Pictures
You might also have seen NFT profile pictures on Twitter.
My profile picture is an NFT I coined with @skogards factoria app, which helps me avoid bogus accounts.

Profile pictures are a good beginning point because they're unique and clearly yours.
NFTs are a way to represent proof-of-ownership. It’s easier to prove ownership of digital assets than physical assets, which is why artwork and pfps are the first use cases.
They can do much more.
NFTs can represent anything with a unique owner and digital ownership certificate. Domains and usernames.
Usernames & Domains
@unstoppableweb, @ensdomains, @rarible sell NFT domains.

NFT domains are transferable, which is a benefit.
Godaddy and other web2 providers have difficult-to-transfer domains. Domains are often leased instead of purchased.
Tickets
NFTs can also represent concert tickets and event passes.
There's a limited number, and entry requires proof.
NFTs can eliminate the problem of forgery and make it easy to verify authenticity and ownership.

NFT tickets can be traded on the secondary market, which allows for:
marketplaces that are uniform and offer the seller and buyer security (currently, tickets are traded on inefficient markets like FB & craigslist)
unbiased pricing
Payment of royalties to the creator

4. Historical ticket ownership data implies performers can airdrop future passes, discounts, etc.
5. NFT passes can be a fandom badge.
The $30B+ online tickets business is increasing fast.
NFT-based ticketing projects:
Gaming Assets
NFTs also help in-game assets.
Imagine someone spending five years collecting a rare in-game blade, then outgrowing or quitting the game. Gamers value that collectible.

The gaming industry is expected to make $200 BILLION in revenue this year, a significant portion of which comes from in-game purchases.
Royalties on secondary market trading of gaming assets encourage gaming businesses to develop NFT-based ecosystems.
Digital assets are the start. On-chain NFTs can represent real-world assets effectively.
Real estate has a unique owner and requires ownership confirmation.
Real Estate
Tokenizing property has many benefits.
1. Can be fractionalized to increase access, liquidity
2. Can be collateralized to increase capital efficiency and access to loans backed by an on-chain asset
3. Allows investors to diversify or make bets on specific neighborhoods, towns or cities +++

I've written about this thought exercise before.
I made an animated video explaining this.
We've just explored NFTs for transferable assets. But what about non-transferrable NFTs?
SBTs are Soul-Bound Tokens. Vitalik Buterin (Ethereum co-founder) blogged about this.
NFTs are basically verifiable digital certificates.
Diplomas & Degrees
That fits Degrees & Diplomas. These shouldn't be marketable, thus they can be non-transferable SBTs.

Anyone can verify the legitimacy of on-chain credentials, degrees, abilities, and achievements.
The same goes for other awards.
For example, LinkedIn could give you a verified checkmark for your degree or skills.

Authenticity Protection
NFTs can also safeguard against counterfeiting.
Counterfeiting is the largest criminal enterprise in the world, estimated to be $2 TRILLION a year and growing.
Anti-counterfeit tech is valuable.
This is one of @ORIGYNTech's projects.

Identity
Identity theft/verification is another real-world problem NFTs can handle.
In the US, 15 million+ citizens face identity theft every year, suffering damages of over $50 billion a year.
This isn't surprising considering all you need for US identity theft is a 9-digit number handed around in emails, documents, on the phone, etc.
Identity NFTs can fix this.
NFTs are one-of-a-kind and unforgeable.
NFTs offer a universal standard.
NFTs are simple to verify.
SBTs, or non-transferrable NFTs, are tied to a particular wallet.
In the event of wallet loss or theft, NFTs may be revoked.

This could be one of the biggest use cases for NFTs.
Imagine a global identity standard that is standardized across countries, cannot be forged or stolen, is digital, easy to verify, and protects your private details.

Since your identity is more than your government ID, you may have many NFTs.
@0xPolygon and @civickey are developing on-chain identity.

Memberships
NFTs can authenticate digital and physical memberships.

Voting
NFT IDs can verify votes.
If you remember 2020, you'll know why this is an issue.
Online voting's ease can boost turnout.

Informational property
NFTs can protect IP.

This can earn creators royalties.
NFTs have 2 important properties:
Verifiability IP ownership is unambiguously stated and publicly verified.
Platforms that enable authors to receive royalties on their IP can enter the market thanks to standardization.
Content Rights

Monetization without copyrighting = more opportunities for everyone.
This works well with the music.

Spotify and Apple Music pay creators very little.
Crowdfunding
Creators can crowdfund with NFTs.
NFTs can represent future royalties for investors.
This is particularly useful for fields where people who are not in the top 1% can’t make money. (Example: Professional sports players)

Mirror.xyz allows blog-based crowdfunding.
Financial NFTs
This introduces Financial NFTs (fNFTs). Unique financial contracts abound.
Examples:
a person's collection of assets (unique portfolio)
A loan contract that has been partially repaid with a lender
temporal tokens (ex: veCRV)

Legal Agreements
Not just financial contracts.
NFT can represent any legal contract or document.

Messages & Emails
What about other agreements? Verbal agreements through emails and messages are likewise unique, but they're easily lost and fabricated.

Health Records
Medical records or prescriptions are another types of documentation that has to be verified but isn't.
Medical NFT examples:
Immunization records
Covid test outcomes
Prescriptions
health issues that may affect one's identity
Observations made via health sensors
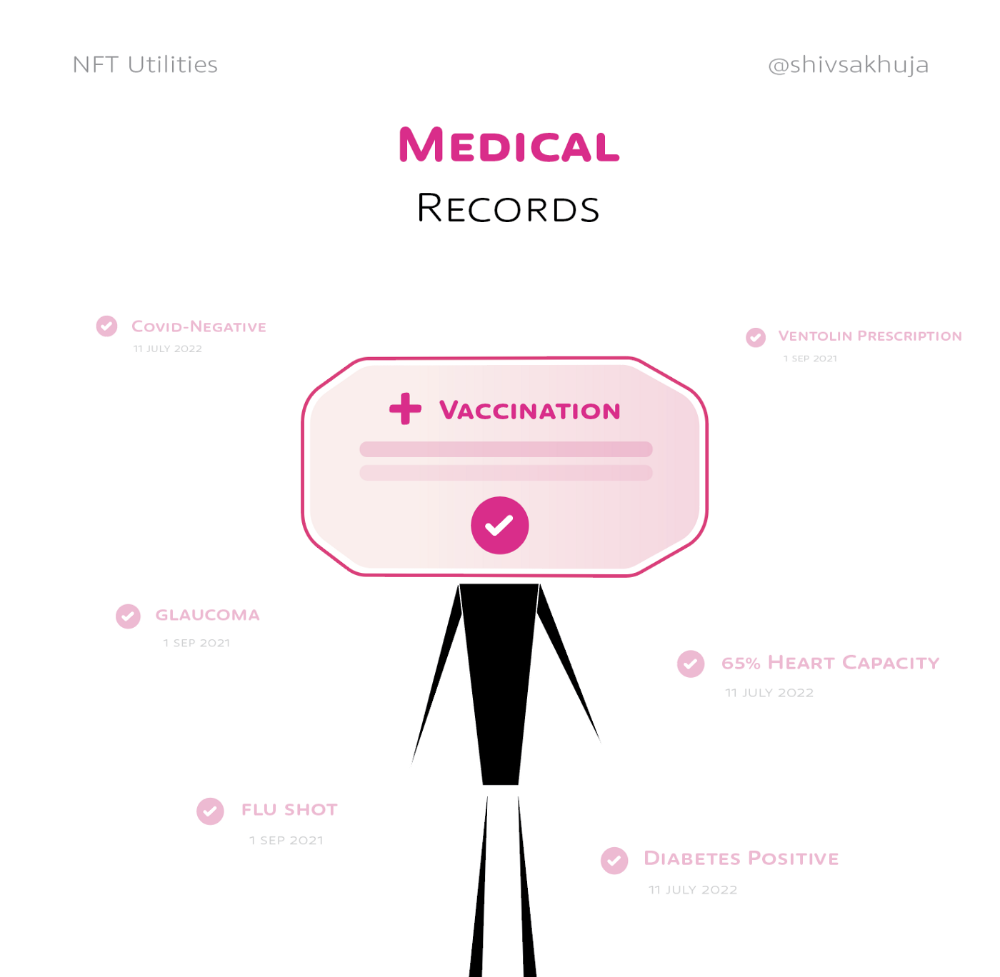
Existing systems of proof by paper / PDF have photoshop-risk.
I tried to include most use scenarios, but this is just the beginning.
NFTs have many innovative uses.
For example: @ShaanVP minted an NFT called “5 Minutes of Fame” 👇
Here are 2 Twitter threads about NFTs:
This piece of gold by @chriscantino
2. This conversation between @punk6529 and @RaoulGMI on @RealVision“The World According to @punk6529”
If you're wondering why NFTs are better than web2 databases for these use scenarios, see this Twitter thread I wrote:
If you liked this, please share it.

Jayden Levitt
3 years ago
How to Explain NFTs to Your Grandmother, in Simple Terms

In simple terms, you probably don’t.
But try. Grandma didn't grow up with Facebook, but she eventually joined.
Perhaps the fear of being isolated outweighed the discomfort of learning the technology.
Grandmas are Facebook likers, sharers, and commenters.
There’s no stopping her.
Not even NFTs. Web3 is currently very complex.
It's difficult to explain what NFTs are, how they work, and why we might use them.
Three explanations.
1. Everything will be ours to own, both physically and digitally.
Why own something you can't touch? What's the point?
Blockchain technology proves digital ownership.
Untouchables need ownership proof. What?
Digital assets reduce friction, save time, and are better for the environment than physical goods.
Many valuable things are intangible. Feeling like your favorite brands. You'll pay obscene prices for clothing that costs pennies.
Secondly, NFTs Are Contracts. Agreements Have Value.
Blockchain technology will replace all contracts and intermediaries.
Every insurance contract, deed, marriage certificate, work contract, plane ticket, concert ticket, or sports event is likely an NFT.
We all have public wallets, like Grandma's Facebook page.
3. Your NFT Purchases Will Be Visible To Everyone.
Everyone can see your public wallet. What you buy says more about you than what you post online.
NFTs issued double as marketing collateral when seen on social media.
While I doubt Grandma knows who Snoop Dog is, imagine him or another famous person holding your NFT in his public wallet and the attention that could bring to you, your company, or brand.
This Technical Section Is For You
The NFT is a contract; its founders can add value through access, events, tuition, and possibly royalties.
Imagine Elon Musk releasing an NFT to his network. Or yearly business consultations for three years.
Christ-alive.
It's worth millions.
These determine their value.
No unsuspecting schmuck willing to buy your hot potato at zero. That's the trend, though.
Overpriced NFTs for low-effort projects created a bubble that has burst.
During a market bubble, you can make money by buying overvalued assets and selling them later for a profit, according to the Greater Fool Theory.
People are struggling. Some are ruined by collateralized loans and the gold rush.
Finances are ruined.
It's uncomfortable.
The same happened in 2018, during the ICO crash or in 1999/2000 when the dot com bubble burst. But the underlying technology hasn’t gone away.
You might also like

Tom Smykowski
3 years ago
CSS Scroll-linked Animations Will Transform The Web's User Experience
We may never tap again in ten years.
I discussed styling websites and web apps on smartwatches in my earlier article on W3C standardization.
The Parallax Chronicles
Section containing examples and flying objects
Another intriguing Working Draft I found applies to all devices, including smartphones.
These pages may have something intriguing. Take your time. Return after scrolling:
What connects these three pages?
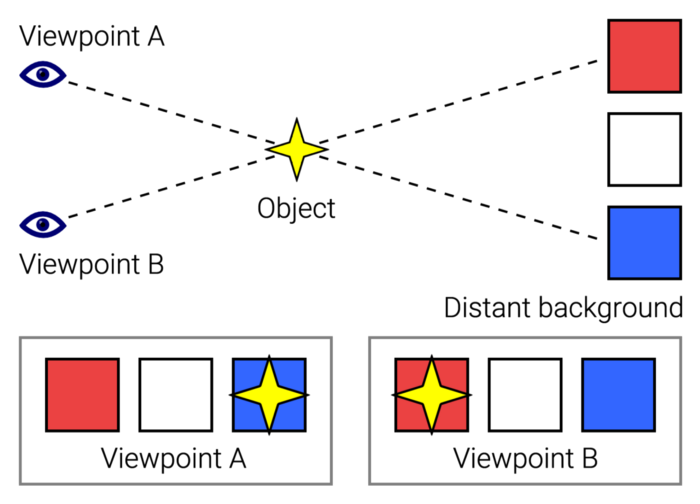
JustinWick at English Wikipedia • CC-BY-SA-3.0
Scroll-linked animation, commonly called parallax, is the effect.
WordPress theme developers' quick setup and low-code tools made the effect popular around 2014.
Parallax: Why Designers Love It
The chapter that your designer shouldn't read
Online video playback required searching, scrolling, and clicking ten years ago. Scroll and click four years ago.
Some video sites let you swipe to autoplay the next video from an endless list.
UI designers create scrollable pages and apps to accommodate the behavioral change.
Web interactivity used to be mouse-based. Clicking a button opened a help drawer, and hovering animated it.
However, a large page with more material requires fewer buttons and less interactiveness.
Designers choose scroll-based effects. Design and frontend developers must fight the trend but prepare for the worst.
How to Create Parallax
The component that you might want to show the designer
JavaScript-based effects track page scrolling and apply animations.
Javascript libraries like lax.js simplify it.
Using it needs a lot of human mathematical and physical computations.
Your asset library must also be prepared to display your website on a laptop, television, smartphone, tablet, foldable smartphone, and possibly even a microwave.
Overall, scroll-based animations can be solved better.
CSS Scroll-linked Animations
CSS makes sense since it's presentational. A Working Draft has been laying the groundwork for the next generation of interactiveness.
The new CSS property scroll-timeline powers the feature, which MDN describes well.
Before testing it, you should realize it is poorly supported:

Firefox 103 currently supports it.
There is also a polyfill, with some demo examples to explore.
Summary
Web design was a protracted process. Started with pages with static backdrop images and scrollable text. Artists and designers may use the scroll-based animation CSS API to completely revamp our web experience.
It's a promising frontier. This post may attract a future scrollable web designer.
Ps. I have created flashcards for HTML, Javascript etc. Check them out!

Glorin Santhosh
3 years ago
Start organizing your ideas by using The Second Brain.

Building A Second Brain helps us remember connections, ideas, inspirations, and insights. Using contemporary technologies and networks increases our intelligence.
This approach makes and preserves concepts. It's a straightforward, practical way to construct a second brain—a remote, centralized digital store for your knowledge and its sources.
How to build ‘The Second Brain’
Have you forgotten any brilliant ideas? What insights have you ignored?
We're pressured to read, listen, and watch informative content. Where did the data go? What happened?
Our brains can store few thoughts at once. Our brains aren't idea banks.
Building a Second Brain helps us remember thoughts, connections, and insights. Using digital technologies and networks expands our minds.
Ten Rules for Creating a Second Brain
1. Creative Stealing
Instead of starting from scratch, integrate other people's ideas with your own.
This way, you won't waste hours starting from scratch and can focus on achieving your goals.
Users of Notion can utilize and customize each other's templates.
2. The Habit of Capture
We must record every idea, concept, or piece of information that catches our attention since our minds are fragile.
When reading a book, listening to a podcast, or engaging in any other topic-related activity, save and use anything that resonates with you.
3. Recycle Your Ideas
Reusing our own ideas across projects might be advantageous since it helps us tie new information to what we already know and avoids us from starting a project with no ideas.
4. Projects Outside of Category
Instead of saving an idea in a folder, group it with documents for a project or activity.
If you want to be more productive, gather suggestions.
5. Burns Slowly
Even if you could finish a job, work, or activity if you focused on it, you shouldn't.
You'll get tired and can't advance many projects. It's easier to divide your routine into daily tasks.
Few hours of daily study is more productive and healthier than entire nights.
6. Begin with a surplus
Instead of starting with a blank sheet when tackling a new subject, utilise previous articles and research.
You may have read or saved related material.
7. Intermediate Packets
A bunch of essay facts.
You can utilize it as a document's section or paragraph for different tasks.
Memorize useful information so you can use it later.
8. You only know what you make
We can see, hear, and read about anything.
What matters is what we do with the information, whether that's summarizing it or writing about it.
9. Make it simpler for yourself in the future.
Create documents or files that your future self can easily understand. Use your own words, mind maps, or explanations.
10. Keep your thoughts flowing.
If you don't employ the knowledge in your second brain, it's useless.
Few people exercise despite knowing its benefits.
Conclusion:
You may continually move your activities and goals closer to completion by organizing and applying your information in a way that is results-focused.
Profit from the information economy's explosive growth by turning your specialized knowledge into cash.
Make up original patterns and linkages between topics.
You may reduce stress and information overload by appropriately curating and managing your personal information stream.
Learn how to apply your significant experience and specific knowledge to a new job, business, or profession.
Without having to adhere to tight, time-consuming constraints, accumulate a body of relevant knowledge and concepts over time.
Take advantage of all the learning materials that are at your disposal, including podcasts, online courses, webinars, books, and articles.

NonConformist
3 years ago
Before 6 AM, read these 6 quotations.
These quotes will change your perspective.

I try to reflect on these quotes daily. Reading it in the morning can affect your day, decisions, and priorities. Let's start.
1. Friedrich Nietzsche once said, "He who has a why to live for can bear almost any how."
What's your life goal?
80% of people don't know why they live or what they want to accomplish in life if you ask them randomly.
Even those with answers may not pursue their why. Without a purpose, life can be dull.
Your why can guide you through difficult times.
Create a life goal. Growing may change your goal. Having a purpose in life prevents feeling lost.

2. Seneca said, "He who fears death will never do anything fit for a man in life."
FAILURE STINKS Yes.
This quote is great if you're afraid to try because of failure. What if I'm not made for it? What will they think if I fail?
This wastes most of our lives. Many people prefer not failing over trying something with a better chance of success, according to studies.
Failure stinks in the short term, but it can transform our lives over time.

3. Two men peered through the bars of their cell windows; one saw mud, the other saw stars. — Dale Carnegie
It’s not what you look at that matters; it’s what you see.
The glass-full-or-empty meme is everywhere. It's hard to be positive when facing adversity.
This is a skill. Positive thinking can change our future.
We should stop complaining about our life and how easy success is for others.
Seductive pessimism. Realize this and start from first principles.

4. “Smart people learn from everything and everyone, average people from their experiences, and stupid people already have all the answers.” — Socrates.
Knowing we're ignorant can be helpful.
Every person and situation teaches you something. You can learn from others' experiences so you don't have to. Analyzing your and others' actions and applying what you learn can be beneficial.
Reading (especially non-fiction or biographies) is a good use of time. Walter Issacson wrote Benjamin Franklin's biography. Ben Franklin's early mistakes and successes helped me in some ways.
Knowing everything leads to disaster. Every incident offers lessons.

5. “We must all suffer one of two things: the pain of discipline or the pain of regret or disappointment.“ — James Rohn
My favorite Jim Rohn quote.
Exercise hurts. Healthy eating can be painful. But they're needed to get in shape. Avoiding pain can ruin our lives.
Always choose progress over hopelessness. Myth: overnight success Everyone who has mastered a craft knows that mastery comes from overcoming laziness.
Turn off your inner critic and start working. Try Can't Hurt Me by David Goggins.

6. “A champion is defined not by their wins, but by how they can recover when they fail.“ — Serena Williams
Have you heard of Traf-o-Data?
Gates and Allen founded Traf-O-Data. After some success, it failed. Traf-o-Data's failure led to Microsoft.
Allen said Traf-O-Data's setback was important for Microsoft's first product a few years later. Traf-O-Data was a business failure, but it helped them understand microprocessors, he wrote in 2017.
“The obstacle in the path becomes the path. Never forget, within every obstacle is an opportunity to improve our condition.” — Ryan Holiday.
Bonus Quotes
More helpful quotes:
“Those who cannot change their minds cannot change anything.” — George Bernard Shaw.
“Do something every day that you don’t want to do; this is the golden rule for acquiring the habit of doing your duty without pain.” — Mark Twain.
“Never give up on a dream just because of the time it will take to accomplish it. The time will pass anyway.” — Earl Nightingale.
“A life spent making mistakes is not only more honorable, but more useful than a life spent doing nothing.” — George Bernard Shaw.
“We don’t stop playing because we grow old; we grow old because we stop playing.” — George Bernard Shaw.
Conclusion
Words are powerful. Utilize it. Reading these inspirational quotes will help you.