





More on Leadership

Bart Krawczyk
3 years ago
Understanding several Value Proposition kinds will help you create better goods.
Fixing problems isn't enough.
Numerous articles and how-to guides on value propositions focus on fixing consumer concerns.
Contrary to popular opinion, addressing customer pain rarely suffices. Win your market category too.

Core Value Statement
Value proposition usually means a product's main value.
Its how your product solves client problems. The product's core.
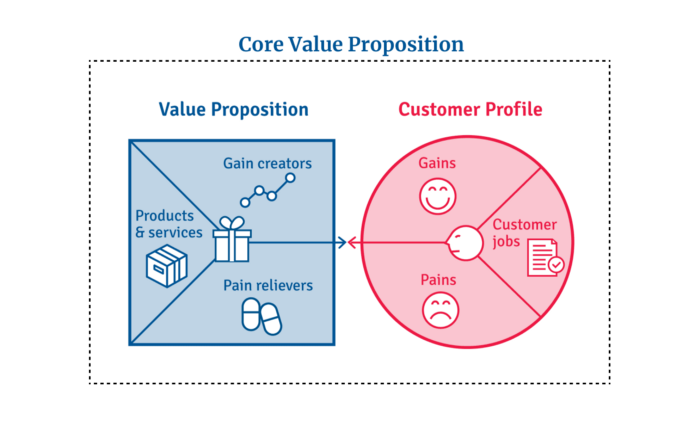
Answering these questions creates a relevant core value proposition:
What tasks is your customer trying to complete? (Jobs for clients)
How much discomfort do they feel while they perform this? (pains)
What would they like to see improved or changed? (gains)
After that, you create products and services that alleviate those pains and give value to clients.
Value Proposition by Category
Your product belongs to a market category and must follow its regulations, regardless of its value proposition.
Creating a new market category is challenging. Fitting into customers' product perceptions is usually better than trying to change them.
New product users simplify market categories. Products are labeled.
Your product will likely be associated with a collection of products people already use.
Example: IT experts will use your communication and management app.
If your target clients think it's an advanced mail software, they'll compare it to others and expect things like:
comprehensive calendar
spam detectors
adequate storage space
list of contacts
etc.
If your target users view your product as a task management app, things change. You can survive without a contact list, but not status management.
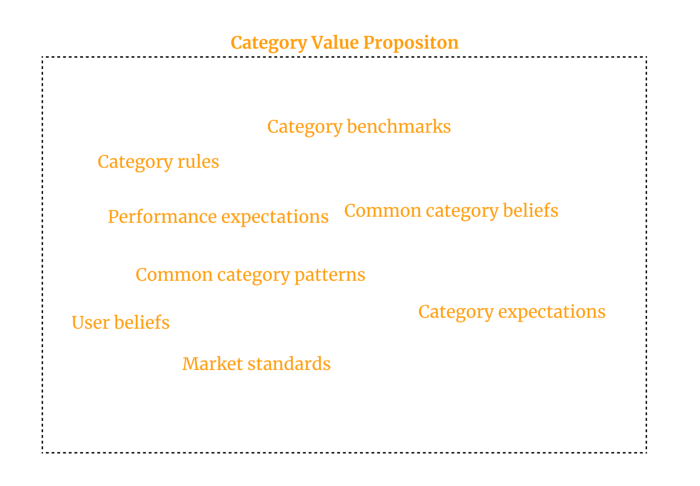
Find out what your customers compare your product to and if it fits your value offer. If so, adapt your product plan to dominate this market. If not, try different value propositions and messaging to put the product in the right context.
Finished Value Proposition
A comprehensive value proposition is when your solution addresses user problems and wins its market category.
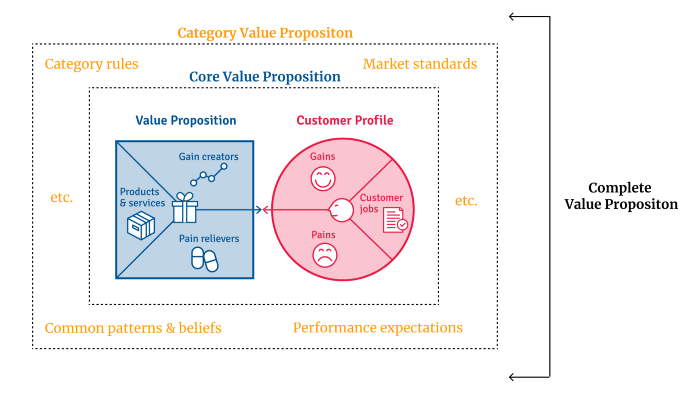
Addressing simply the primary value proposition may produce a valuable and original product, but it may struggle to cross the chasm into the mainstream market. Meeting expectations is easier than changing views.
Without a unique value proposition, you will drown in the red sea of competition.
To conclude:
Find out who your target consumer is and what their demands and problems are.
To meet these needs, develop and test a primary value proposition.
Speak with your most devoted customers. Recognize the alternatives they use to compare you against and the market segment they place you in.
Recognize the requirements and expectations of the market category.
To meet or surpass category standards, modify your goods.
Great products solve client problems and win their category.

Jano le Roux
3 years ago
The Real Reason Adobe Just Paid $20 billion for Figma
Sketch or Figma?

Designers are pissed.
The beast ate the beauty.
Figma deserves $20B.
Do designers deserve Adobe?
Adobe devours new creative tools and spits them out with a slimy Adobe aftertaste.
Frame.io — $1.3B
Magento — $1.7B
Macromedia — $3.6B
Nothing compares to the risky $20B acquisition.
If they can't be beaten, buy them.
And then make them boring.
Adobe's everywhere.
Like that friend who dabbles in everything creatively, there's not enough time to master one thing.
Figma was Adobe's thigh-mounted battle axe.
a UX design instrument with a sizable free tier.
a UX design tool with a simple and quick user interface.
a tool for fluid collaboration in user experience design.
a web-based UX design tool that functions well.
a UX design tool with a singular goal of perfection.
UX design software that replaced Adobe XD.
Adobe XD could do many of Figma's things, but it didn't focus on the details. This is a major issue when working with detail-oriented professionals.
UX designers.
Design enthusiasts first used Figma. More professionals used it. Institutions taught it. Finally, major brands adopted Figma.
Adobe hated that.
Adobe dispatched a team of lawyers to resolve the Figma issue, as big companies do. Figma didn’t bite for months.
Oh no.
Figma resisted.
Figma helped designers leave Adobe. Figma couldn't replace Photoshop, but most designers used it to remove backgrounds.
Online background removal tools improved.
The Figma problem grew into a thorn, a knife, and a battle ax in Adobe's soft inner thigh.
Figma appeared to be going public. Adobe couldn’t allow that. It bought Figma for $20B during the IPO drought.
Adobe has a new issue—investors are upset.
The actual cause of investors' ire toward Adobe
Spoiler: The math just doesn’t add up.
According to Adobe's press release, Figma's annual recurring revenue (ARR) is $400M and growing rapidly.
The $20B valuation requires a 50X revenue multiple, which is unheard of.
Venture capitalists typically use:
10% to 29% growth per year: ARR multiplied by 1 to 5
30% to 99% growth per year: ARR multiplied by 6 to 10
100% to 400% growth per year: ARR multiplied by 10 to 20
Showing an investor a 50x multiple is like telling friends you saw a UFO. They'll think you're crazy.
Adobe's stock fell immediately after the acquisition because it didn't make sense to a number-cruncher.
Designers started a Tweet storm in the digital town hall where VCs and designers often meet.
Adobe acquired Workfront for $1.5 billion at the end of 2020. This purchase made sense for investors.
Many investors missed the fact that Adobe is acquiring Figma not only for its ARR but also for its brilliant collaboration tech.
Adobe could use Figmas web app technology to make more products web-based to compete with Canva.
Figma's high-profile clients could switch to Adobe's enterprise software.
However, questions arise:
Will Adobe make Figma boring?
Will Adobe tone down Figma to boost XD?
Would you ditch Adobe and Figma for Sketch?
Jano le Roux
3 years ago
Quit worrying about Twitter: Elon moves quickly before refining
Elon's rides start rough, but then...

Elon Musk has never been so hated.
They don’t get Elon.
He began using PayPal in this manner.
He began with SpaceX in a similar manner.
He began with Tesla in this manner.
Disruptive.
Elon had rocky starts. His creativity requires it. Just like writing a first draft.
His fastest way to find the way is to avoid it.
PayPal's pricey launch
PayPal was a 1999 business flop.
They were considered insane.
Elon and his co-founders had big plans for PayPal. They adopted the popular philosophy of the time, exchanging short-term profit for growth, and pulled off a miracle just before the bubble burst.
PayPal was created as a dollar alternative. Original PayPal software allowed PalmPilot money transfers. Unfortunately, there weren't enough PalmPilot users.
Since everyone had email, the company emailed payments. Costs rose faster than sales.
The startup wanted to get a million subscribers by paying $10 to sign up and $10 for each referral. Elon thought the price was fair because PayPal made money by charging transaction fees. They needed to make money quickly.
A Wall Street Journal article valuing PayPal at $500 million attracted investors. The dot-com bubble burst soon after they rushed to get financing.
Musk and his partners sold PayPal to eBay for $1.5 billion in 2002. Musk's most successful company was PayPal.
SpaceX's start-up error
Elon and his friends bought a reconditioned ICBM in Russia in 2002.
He planned to invest much of his wealth in a stunt to promote NASA and space travel.
Many called Elon crazy.
The goal was to buy a cheap Russian rocket to launch mice or plants to Mars and return them. He thought SpaceX would revive global space interest. After a bad meeting in Moscow, Elon decided to build his own rockets to undercut launch contracts.
Then SpaceX was founded.
Elon’s plan was harder than expected.
Explosions followed explosions.
Millions lost on cargo.
Millions lost on the rockets.
Investors thought Elon was crazy, but he wasn't.
NASA's biggest competitor became SpaceX. NASA hired SpaceX to handle many of its missions.
Tesla's shaky beginning
Tesla began shakily.
Clients detested their roadster.
They continued to miss deadlines.
Lotus would handle the car while Tesla focused on the EV component, easing Tesla's entry. The business experienced elegance creep. Modifying specific parts kept the car from getting worse.
Cost overruns, delays, and other factors changed the Elise-like car's appearance. Only 7% of the Tesla Roadster's parts matched its Lotus twin.
Tesla was about to die.
Elon saved the mess as CEO.
He fired 25% of the workforce to reduce costs.
Elon Musk transformed Tesla into the world's most valuable automaker by running it like a startup.
Tesla hasn't spent a dime on advertising. They let the media do the talking by investing in innovation.
Elon sheds. Elon tries. Elon learns. Elon refines.
Twitter doesn't worry me.
The media is shocked. I’m not.
This is just Elon being Elon.
Elon makes lean.
Elon tries new things.
Elon listens to feedback.
Elon refines.
Besides Twitter will always be Twitter.
You might also like

Zuzanna Sieja
3 years ago
In 2022, each data scientist needs to read these 11 books.

Non-technical talents can benefit data scientists in addition to statistics and programming.
As our article 5 Most In-Demand Skills for Data Scientists shows, being business-minded is useful. How can you get such a diverse skill set? We've compiled a list of helpful resources.
Data science, data analysis, programming, and business are covered. Even a few of these books will make you a better data scientist.
Ready? Let’s dive in.
Best books for data scientists
1. The Black Swan
Author: Nassim Taleb

First, a less obvious title. Nassim Nicholas Taleb's seminal series examines uncertainty, probability, risk, and decision-making.
Three characteristics define a black swan event:
It is erratic.
It has a significant impact.
Many times, people try to come up with an explanation that makes it seem more predictable than it actually was.
People formerly believed all swans were white because they'd never seen otherwise. A black swan in Australia shattered their belief.
Taleb uses this incident to illustrate how human thinking mistakes affect decision-making. The book teaches readers to be aware of unpredictability in the ever-changing IT business.
Try multiple tactics and models because you may find the answer.
2. High Output Management
Author: Andrew Grove

Intel's former chairman and CEO provides his insights on developing a global firm in this business book. We think Grove would choose “management” to describe the talent needed to start and run a business.
That's a skill for CEOs, techies, and data scientists. Grove writes on developing productive teams, motivation, real-life business scenarios, and revolutionizing work.
Five lessons:
Every action is a procedure.
Meetings are a medium of work
Manage short-term goals in accordance with long-term strategies.
Mission-oriented teams accelerate while functional teams increase leverage.
Utilize performance evaluations to enhance output.
So — if the above captures your imagination, it’s well worth getting stuck in.
3. The Hard Thing About Hard Things: Building a Business When There Are No Easy Answers
Author: Ben Horowitz

Few realize how difficult it is to run a business, even though many see it as a tremendous opportunity.
Business schools don't teach managers how to handle the toughest difficulties; they're usually on their own. So Ben Horowitz wrote this book.
It gives tips on creating and maintaining a new firm and analyzes the hurdles CEOs face.
Find suggestions on:
create software
Run a business.
Promote a product
Obtain resources
Smart investment
oversee daily operations
This book will help you cope with tough times.
4. Obviously Awesome: How to Nail Product Positioning
Author: April Dunford

Your job as a data scientist is a product. You should be able to sell what you do to clients. Even if your product is great, you must convince them.
How to? April Dunford's advice: Her book explains how to connect with customers by making your offering seem like a secret sauce.
You'll learn:
Select the ideal market for your products.
Connect an audience to the value of your goods right away.
Take use of three positioning philosophies.
Utilize market trends to aid purchasers
5. The Mom test
Author: Rob Fitzpatrick

The Mom Test improves communication. Client conversations are rarely predictable. The book emphasizes one of the most important communication rules: enquire about specific prior behaviors.
Both ways work. If a client has suggestions or demands, listen carefully and ensure everyone understands. The book is packed with client-speaking tips.
6. Introduction to Machine Learning with Python: A Guide for Data Scientists
Authors: Andreas C. Müller, Sarah Guido

Now, technical documents.
This book is for Python-savvy data scientists who wish to learn machine learning. Authors explain how to use algorithms instead of math theory.
Their technique is ideal for developers who wish to study machine learning basics and use cases. Sci-kit-learn, NumPy, SciPy, pandas, and Jupyter Notebook are covered beyond Python.
If you know machine learning or artificial neural networks, skip this.
7. Python Data Science Handbook: Essential Tools for Working with Data
Author: Jake VanderPlas

Data work isn't easy. Data manipulation, transformation, cleansing, and visualization must be exact.
Python is a popular tool. The Python Data Science Handbook explains everything. The book describes how to utilize Pandas, Numpy, Matplotlib, Scikit-Learn, and Jupyter for beginners.
The only thing missing is a way to apply your learnings.
8. Python for Data Analysis: Data Wrangling with Pandas, NumPy, and IPython
Author: Wes McKinney

The author leads you through manipulating, processing, cleaning, and analyzing Python datasets using NumPy, Pandas, and IPython.
The book's realistic case studies make it a great resource for Python or scientific computing beginners. Once accomplished, you'll uncover online analytics, finance, social science, and economics solutions.
9. Data Science from Scratch
Author: Joel Grus

Here's a title for data scientists with Python, stats, maths, and algebra skills (alongside a grasp of algorithms and machine learning). You'll learn data science's essential libraries, frameworks, modules, and toolkits.
The author works through all the key principles, providing you with the practical abilities to develop simple code. The book is appropriate for intermediate programmers interested in data science and machine learning.
Not that prior knowledge is required. The writing style matches all experience levels, but understanding will help you absorb more.
10. Machine Learning Yearning
Author: Andrew Ng

Andrew Ng is a machine learning expert. Co-founded and teaches at Stanford. This free book shows you how to structure an ML project, including recognizing mistakes and building in complex contexts.
The book delivers knowledge and teaches how to apply it, so you'll know how to:
Determine the optimal course of action for your ML project.
Create software that is more effective than people.
Recognize when to use end-to-end, transfer, and multi-task learning, and how to do so.
Identifying machine learning system flaws
Ng writes easy-to-read books. No rigorous math theory; just a terrific approach to understanding how to make technical machine learning decisions.
11. Deep Learning with PyTorch Step-by-Step
Author: Daniel Voigt Godoy

The last title is also the most recent. The book was revised on 23 January 2022 to discuss Deep Learning and PyTorch, a Python coding tool.
It comprises four parts:
Fundamentals (gradient descent, training linear and logistic regressions in PyTorch)
Machine Learning (deeper models and activation functions, convolutions, transfer learning, initialization schemes)
Sequences (RNN, GRU, LSTM, seq2seq models, attention, self-attention, transformers)
Automatic Language Recognition (tokenization, embeddings, contextual word embeddings, ELMo, BERT, GPT-2)
We admire the book's readability. The author avoids difficult mathematical concepts, making the material feel like a conversation.
Is every data scientist a humanist?
Even as a technological professional, you can't escape human interaction, especially with clients.
We hope these books will help you develop interpersonal skills.

Julie Plavnik
3 years ago
How to Become a Crypto Broker [Complying and Making Money]
Three options exist. The third one is the quickest and most fruitful.

You've mastered crypto trading and want to become a broker.
So you may wonder: Where to begin?
If so, keep reading.
Today I'll compare three different approaches to becoming a cryptocurrency trader.
What are cryptocurrency brokers, and how do they vary from stockbrokers?
A stockbroker implements clients' market orders (retail or institutional ones).
Brokerage firms are regulated, insured, and subject to regulatory monitoring.
Stockbrokers are required between buyers and sellers. They can't trade without a broker. To trade, a trader must open a broker account and deposit money. When a trader shops, he tells his broker what orders to place.
Crypto brokerage is trade intermediation with cryptocurrency.
In crypto trading, however, brokers are optional.
Crypto exchanges offer direct transactions. Open an exchange account (no broker needed) and make a deposit.
Question:
Since crypto allows DIY trading, why use a broker?
Let's compare cryptocurrency exchanges vs. brokers.
Broker versus cryptocurrency exchange
Most existing crypto exchanges are basically brokers.
Examine their primary services:
connecting purchasers and suppliers
having custody of clients' money (with the exception of decentralized cryptocurrency exchanges),
clearance of transactions.
Brokerage is comparable, don't you think?
There are exceptions. I mean a few large crypto exchanges that follow the stock exchange paradigm. They outsource brokerage, custody, and clearing operations. Classic exchange setups are rare in today's bitcoin industry.
Back to our favorite “standard” crypto exchanges. All-in-one exchanges and brokers. And usually, they operate under a broker or a broker-dealer license, save for the exchanges registered somewhere in a free-trade offshore paradise. Those don’t bother with any licensing.
What’s the sense of having two brokers at a time?
Better liquidity and trading convenience.
The crypto business is compartmentalized.
We have CEXs, DEXs, hybrid exchanges, and semi-exchanges (those that aggregate liquidity but do not execute orders on their sides). All have unique regulations and act as sovereign states.
There are about 18k coins and hundreds of blockchain protocols, most of which are heterogeneous (i.e., different in design and not interoperable).
A trader must register many accounts on different exchanges, deposit funds, and manage them all concurrently to access global crypto liquidity.
It’s extremely inconvenient.
Crypto liquidity fragmentation is the largest obstacle and bottleneck blocking crypto from mass adoption.
Crypto brokers help clients solve this challenge by providing one-gate access to deep and diverse crypto liquidity from numerous exchanges and suppliers. Professionals and institutions need it.
Another killer feature of a brokerage may be allowing clients to trade crypto with fiat funds exclusively, without fiat/crypto conversion. It is essential for professional and institutional traders.
Who may work as a cryptocurrency broker?
Apparently, not anyone. Brokerage requires high-powered specialists because it involves other people's money.
Here's the essentials:
excellent knowledge, skills, and years of trading experience
high-quality, quick, and secure infrastructure
highly developed team
outstanding trading capital
High-ROI network: long-standing, trustworthy connections with customers, exchanges, liquidity providers, payment gates, and similar entities
outstanding marketing and commercial development skills.
What about a license for a cryptocurrency broker? Is it necessary?
Complex question.
If you plan to play in white-glove jurisdictions, you may need a license. For example, in the US, as a “money transmitter” or as a CASSP (crypto asset secondary services provider) in Australia.
Even in these jurisdictions, there are no clear, holistic crypto brokerage and licensing policies.
Your lawyer will help you decide if your crypto brokerage needs a license.
Getting a license isn't quick. Two years of patience are needed.
How can you turn into a cryptocurrency broker?
Finally, we got there! 🎉
Three actionable ways exist:
To kickstart a regulated stand-alone crypto broker
To get a crypto broker franchise, and
To become a liquidity network broker.
Let's examine each.
1. Opening a regulated cryptocurrency broker
It's difficult. Especially If you're targeting first-world users.
You must comply with many regulatory, technical, financial, HR, and reporting obligations to keep your organization running. Some are mentioned above.
The licensing process depends on the products you want to offer (spots or derivatives) and the geographic areas you plan to service. There are no general rules for that.
In an overgeneralized way, here are the boxes you will have to check:
capital availability (usually a large amount of capital c is required)
You will have to move some of your team members to the nation providing the license in order to establish an office presence there.
the core team with the necessary professional training (especially applies to CEO, Head of Trading, Assistant to Head of Trading, etc.)
insurance
infrastructure that is trustworthy and secure
adopted proper AML/KYC/financial monitoring policies, etc.
Assuming you passed, what's next?
I bet it won’t be mind-blowing for you that the license is just a part of the deal. It won't attract clients or revenue.
To bring in high-dollar clientele, you must be a killer marketer and seller. It's not easy to convince people to give you money.
You'll need to be a great business developer to form successful, long-term agreements with exchanges (ideally for no fees), liquidity providers, banks, payment gates, etc. Persuade clients.
It's a tough job, isn't it?

I expect a Quora-type question here:
Can I start an unlicensed crypto broker?
Well, there is always a workaround with crypto!
You can register your broker in a free-trade zone like Seychelles to avoid US and other markets with strong watchdogs.
This is neither wise nor sustainable.
First, such experiments are illegal.
Second, you'll have trouble attracting clients and strategic partners.
A license equals trust. That’s it.
Even a pseudo-license from Mauritius matters.
Here are this method's benefits and downsides.
Cons first.
As you navigate this difficult and expensive legal process, you run the risk of missing out on business prospects. It's quite simple to become excellent compliance yet unable to work. Because your competitors are already courting potential customers while you are focusing all of your effort on paperwork.
Only God knows how long it will take you to pass the break-even point when everything with the license has been completed.
It is a money-burning business, especially in the beginning when the majority of your expenses will go toward marketing, sales, and maintaining license requirements. Make sure you have the fortitude and resources necessary to face such a difficult challenge.
Pros
It may eventually develop into a tool for making money. Because big guys who are professionals at trading require a white-glove regulated brokerage. You have every possibility if you work hard in the areas of sales, marketing, business development, and wealth. Simply put, everything must align.
Launching a regulated crypto broker is analogous to launching a crypto exchange. It's ROUGH. Sure you can take it?
2. Franchise for Crypto Broker (Crypto Sub-Brokerage)
A broker franchise is easier and faster than becoming a regulated crypto broker. Not a traditional brokerage.
A broker franchisee, often termed a sub-broker, joins with a broker (a franchisor) to bring them new clients. Sub-brokers market a broker's products and services to clients.
Sub-brokers are the middlemen between a broker and an investor.
Why is sub-brokering easier?
less demanding qualifications and legal complexity. All you need to do is keep a few certificates on hand (each time depends on the jurisdiction).
No significant investment is required
there is no demand that you be a trading member of an exchange, etc.
As a sub-broker, you can do identical duties without as many rights and certifications.
What about the crypto broker franchise?
Sub-brokers aren't common in crypto.
In most existing examples (PayBito, PCEX, etc.), franchises are offered by crypto exchanges, not brokers. Though we remember that crypto exchanges are, in fact, brokers, do we?
Similarly:
For a commission, a franchiser crypto broker receives new leads from a crypto sub-broker.
See above for why enrolling is easy.
Finding clients is difficult. Most crypto traders prefer to buy-sell on their own or through brokers over sub-broker franchises.
3. Broker of the Crypto Trading Network (or a Network Broker)
It's the greatest approach to execute crypto brokerage, based on effort/return.
Network broker isn't an established word. I wrote it for clarity.
Remember how we called crypto liquidity fragmentation the current crypto finance paradigm's main bottleneck?
Where there's a challenge, there's progress.
Several well-funded projects are aiming to fix crypto liquidity fragmentation. Instead of launching another crypto exchange with siloed trading, the greatest minds create trading networks that aggregate crypto liquidity from desynchronized sources and enable quick, safe, and affordable cross-blockchain transactions. Each project offers a distinct option for users.
Crypto liquidity implies:
One-account access to cryptocurrency liquidity pooled from network participants' exchanges and other liquidity sources
compiled price feeds
Cross-chain transactions that are quick and inexpensive, even for HFTs
link between participants of all kinds, and
interoperability among diverse blockchains
Fast, diversified, and cheap global crypto trading from one account.
How does a trading network help cryptocurrency brokers?
I’ll explain it, taking Yellow Network as an example.
Yellow provides decentralized Layer-3 peer-to-peer trading.
trade across chains globally with real-time settlement and
Between cryptocurrency exchanges, brokers, trading companies, and other sorts of network members, there is communication and the exchange of financial information.
Have you ever heard about ECN (electronic communication network)? If not, it's an automated system that automatically matches buy and sell orders. Yellow is a decentralized digital asset ECN.
Brokers can:
Start trading right now without having to meet stringent requirements; all you need to do is integrate with Yellow Protocol and successfully complete some KYC verification.
Access global aggregated crypto liquidity through a single point.
B2B (Broker to Broker) liquidity channels that provide peer liquidity from other brokers. Orders from the other broker will appear in the order book of a broker who is peering with another broker on the market. It will enable a broker to broaden his offer and raise the total amount of liquidity that is available to his clients.
Select a custodian or use non-custodial practices.
Comparing network crypto brokerage to other types:
A licensed stand-alone brokerage business is much more difficult and time-consuming to launch than network brokerage, and
Network brokerage, in contrast to crypto sub-brokerage, is scalable, independent, and offers limitless possibilities for revenue generation.
Yellow Network Whitepaper. has more details on how to start a brokerage business and what rewards you'll obtain.
Final thoughts
There are three ways to become a cryptocurrency broker, including the non-conventional liquidity network brokerage. The last option appears time/cost-effective.
Crypto brokerage isn't crowded yet. Act quickly to find your right place in this market.
Choose the way that works for you best and see you in crypto trading.
Discover Web3 & DeFi with Yellow Network!
Yellow, powered by Openware, is developing a cross-chain P2P liquidity aggregator to unite the crypto sector and provide global remittance services that aid people.
Join the Yellow Community and plunge into this decade's biggest product-oriented crypto project.
Observe Yellow Twitter
Enroll in Yellow Telegram
Visit Yellow Discord.
On Hacker Noon, look us up.
Yellow Network will expose development, technology, developer tools, crypto brokerage nodes software, and community liquidity mining.

Emils Uztics
3 years ago
This billionaire created a side business that brings around $90,000 per month.

Dharmesh Shah co-founded HubSpot. WordPlay reached $90,000 per month in revenue without utilizing any of his wealth.
His method:
Take Advantage Of An Established Trend
Remember Wordle? Dharmesh was instantly hooked. As was the tech world.

HubSpot's co-founder noted inefficiencies in a recent My First Million episode. He wanted to play daily. Dharmesh, a tinkerer and software engineer, decided to design a word game.
He's a billionaire. How could he?
Wordle had limitations in his opinion;
Dharmesh is fundamentally a developer. He desired to start something new and increase his programming knowledge;
This project may serve as an excellent illustration for his son, who had begun learning about software development.
Better It Up
Building a new Wordle wasn't successful.
WordPlay lets you play with friends and family. You could challenge them and compare the results. It is a built-in growth tool.
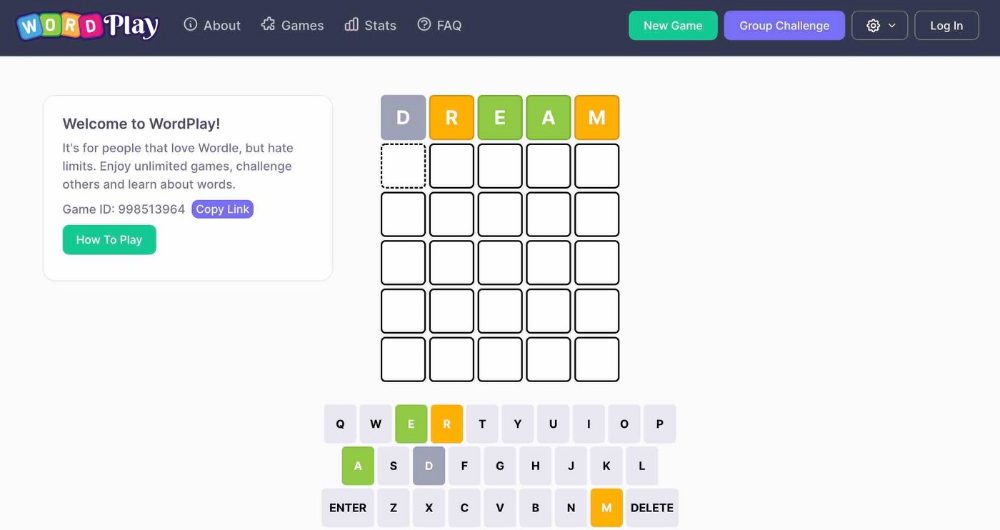
WordPlay features:
the capacity to follow sophisticated statistics after creating an account;
continuous feedback on your performance;
Outstanding domain name (wordplay.com).
Project Development
WordPlay has 9.5 million visitors and 45 million games played since February.
HubSpot co-founder credits tremendous growth to flywheel marketing, pushing the game through his own following.
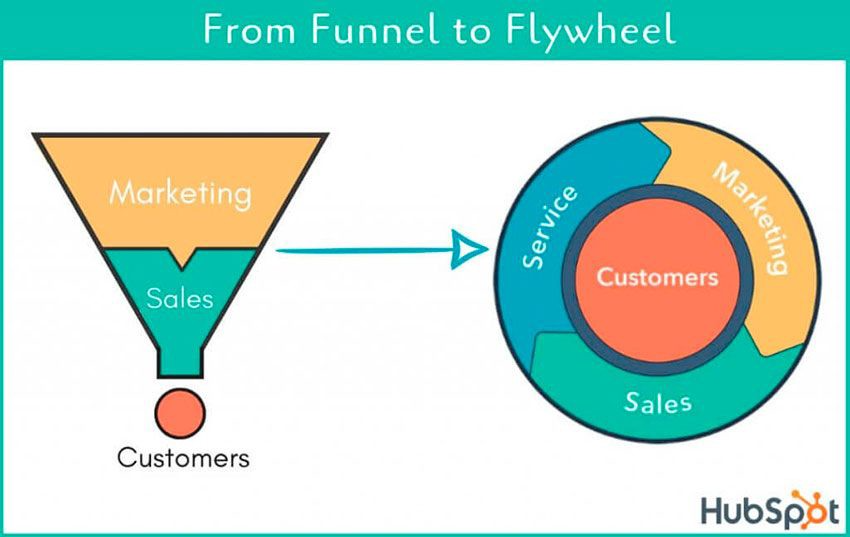
Choosing an exploding specialty and making sharing easy also helped.
Shah enabled Google Ads on the website to test earning potential. Monthly revenue was $90,000.
That's just Google Ads. If monetization was the goal, a specialized ad network like Ezoic could double or triple the amount.
Wordle was a great buy for The New York Times at $1 million.