



More on Technology

Sukhad Anand
3 years ago
How Do Discord's Trillions Of Messages Get Indexed?
They depend heavily on open source..

Discord users send billions of messages daily. Users wish to search these messages. How do we index these to search by message keywords?
Let’s find out.
Discord utilizes Elasticsearch. Elasticsearch is a free, open search engine for textual, numerical, geographical, structured, and unstructured data. Apache Lucene powers Elasticsearch.
How does elastic search store data? It stores it as numerous key-value pairs in JSON documents.
How does elastic search index? Elastic search's index is inverted. An inverted index lists every unique word in every page and where it appears.
4. Elasticsearch indexes documents and generates an inverted index to make data searchable in near real-time. The index API adds or updates JSON documents in a given index.
Let's examine how discord uses Elastic Search. Elasticsearch prefers bulk indexing. Discord couldn't index real-time messages. You can't search posted messages. You want outdated messages.
6. Let's check what bulk indexing requires.
1. A temporary queue for incoming communications.
2. Indexer workers that index messages into elastic search.
Discord's queue is Celery. The queue is open-source. Elastic search won't run on a single server. It's clustered. Where should a message go? Where?
8. A shard allocator decides where to put the message. Nevertheless. Shattered? A shard combines elastic search and index on. So, these two form a shard which is used as a unit by discord. The elastic search itself has some shards. But this is different, so don’t get confused.
Now, the final part is service discovery — to discover the elastic search clusters and the hosts within that cluster. This, they do with the help of etcd another open source tool.
A great thing to notice here is that discord relies heavily on open source systems and their base implementations which is very different from a lot of other products.

Frank Andrade
3 years ago
I discovered a bug that allowed me to use ChatGPT to successfully web scrape. Here's how it operates.
This method scrapes websites with ChatGPT (demo with Amazon and Twitter)

In a recent article, I demonstrated how to scrape websites using ChatGPT prompts like scrape website X using Python.
But that doesn’t always work.
After scraping dozens of websites with ChatGPT, I realized that simple prompts rarely work for web scraping.
Using ChatGPT and basic HTML, we can scrape any website.
First things first, use ChatGPT's advanced version (Playground)
ChatGPT Playground's enhanced version is needed to scrape websites quickly. It generates code faster and has less constraints.
Here’s how it looks.
The classic ChatGPT display just allows you to type a prompt. Playground is more customizable and generates code faster than the basic version.
No more delays or restrictions.
In this tutorial, we'll write prompts underneath Playground.
How to Use ChatGPT to Scrape Any Website
To show you how to utilize ChatGPT to scrape any website, we'll use subslikescript, which lists movies.
Later in this post, I'll show you how to scrape Amazon and Twitter, but let's start easy.
If we try a basic prompt like “scrape the movie titles on this website: https://subslikescript.com/movies” it won’t scrape anything. Here’s when we need some HTML knowledge to build the right prompt for ChatGPT.Let's scrape the above movie titles. First, check the webpage. Right-click any element and choose Inspect.
Then see below.
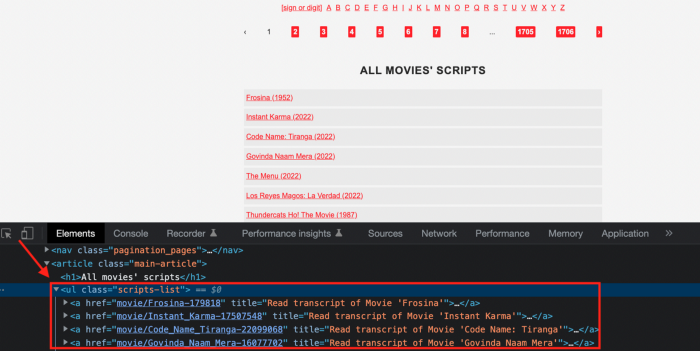
We identify the element to scrape (those in the red box). The data elements are ul, a, and scripts-list.
Here's the prompt for movie titles.
Scrape this website: https://subslikescript.com/movies with Python and Beautiful Soup. Locate the element with tag “ul” and class “scripts-list”. Scrape all the “a” elements inside. Get the text attribute and print it.
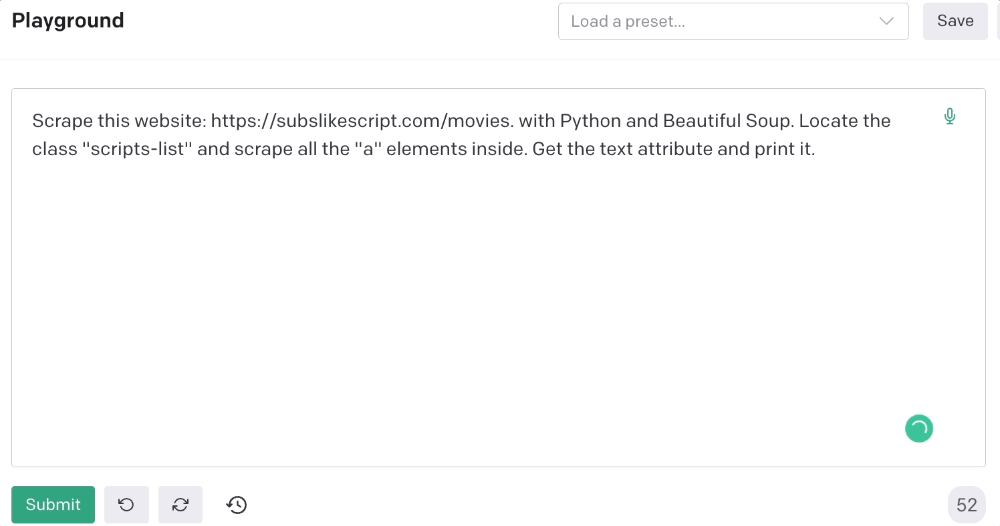
Code generated:
import requests
from bs4 import BeautifulSoup
page = requests.get('https://subslikescript.com/movies/')
soup = BeautifulSoup(page.content, 'html.parser')
scripts_list = soup.find(class_="scripts-list")
all_a_elements = scripts_list.find_all('a')
for element in all_a_elements:
print(element.get_text())It extracts movie titles successfully.
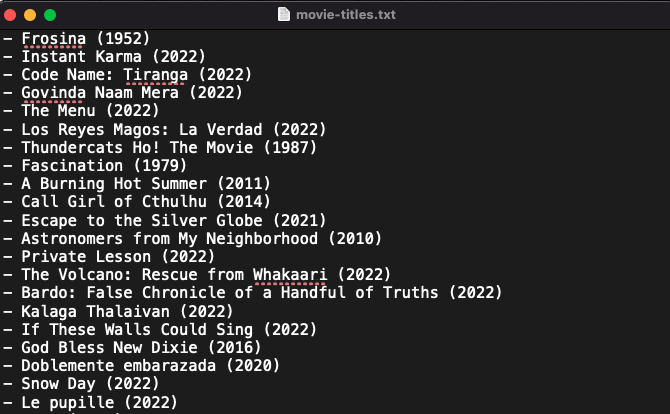
Let's scrape Amazon and Twitter.
ChatGPT's Amazon scraping
Consider scraping Amazon for self-help books. First, copy the Amazon link for self-help books.
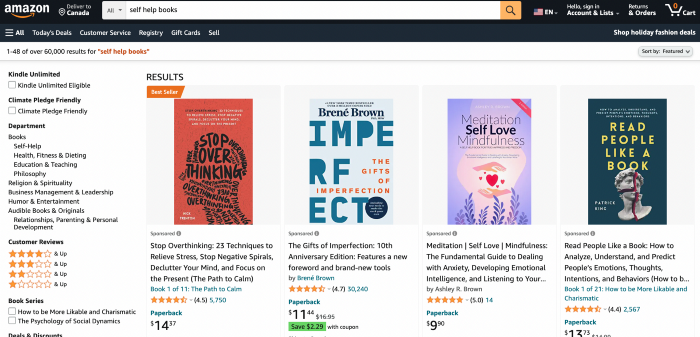
Here’s the link I got. Location-dependent connection. Use my link to replicate my results.
Now we'll check book titles. Here's our element.
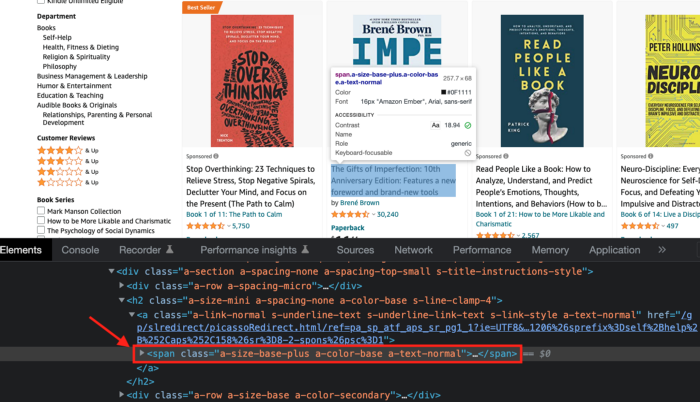
If we want to extract the book titles, we need to use the tag name span, class attribute name and a-size-base-plus a-color-base a-text-normalattribute value.
This time I'll use Selenium. I'll add Selenium-specific commands like wait 5 seconds and generate an XPath.
Scrape this website https://www.amazon.com/s?k=self+help+books&sprefix=self+help+%2Caps%2C158&ref=nb_sb_ss_ts-doa-p_2_10 with Python and Selenium.
Wait 5 seconds and locate all the elements with the following xpath: “span” tag, “class” attribute name, and “a-size-base-plus a-color-base a-text-normal” attribute value. Get the text attribute and print them.
Code generated: (I only had to manually add the path where my chromedriver is located).
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
#initialize webdriver
driver = webdriver.Chrome('<add path of your chromedriver>')
#navigate to the website
driver.get("https://www.amazon.com/s?k=self+help+books&sprefix=self+help+%2Caps%2C158&ref=nb_sb_ss_ts-doa-p_2_10")
#wait 5 seconds to let the page load
sleep(5)
#locate all the elements with the following xpath
elements = driver.find_elements(By.XPATH, '//span[@class="a-size-base-plus a-color-base a-text-normal"]')
#get the text attribute of each element and print it
for element in elements:
print(element.text)
#close the webdriver
driver.close()It pulls Amazon book titles.

Utilizing ChatGPT to scrape Twitter
Say you wish to scrape ChatGPT tweets. Search Twitter for ChatGPT and copy the URL.
Here’s the link I got. We must check every tweet. Here's our element.
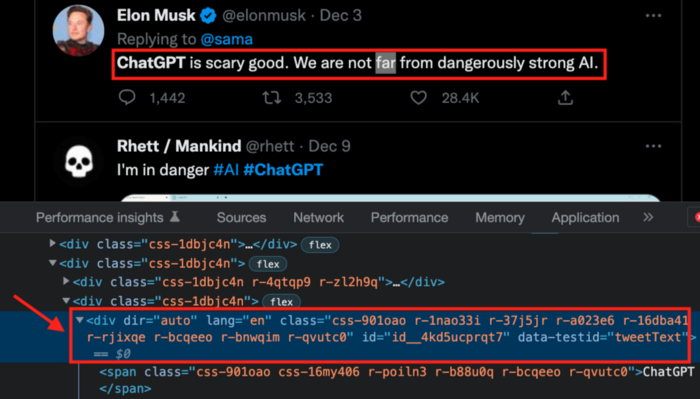
To extract a tweet, use the div tag and lang attribute.
Again, Selenium.
Scrape this website: https://twitter.com/search?q=chatgpt&src=typed_query using Python, Selenium and chromedriver.
Maximize the window, wait 15 seconds and locate all the elements that have the following XPath: “div” tag, attribute name “lang”. Print the text inside these elements.
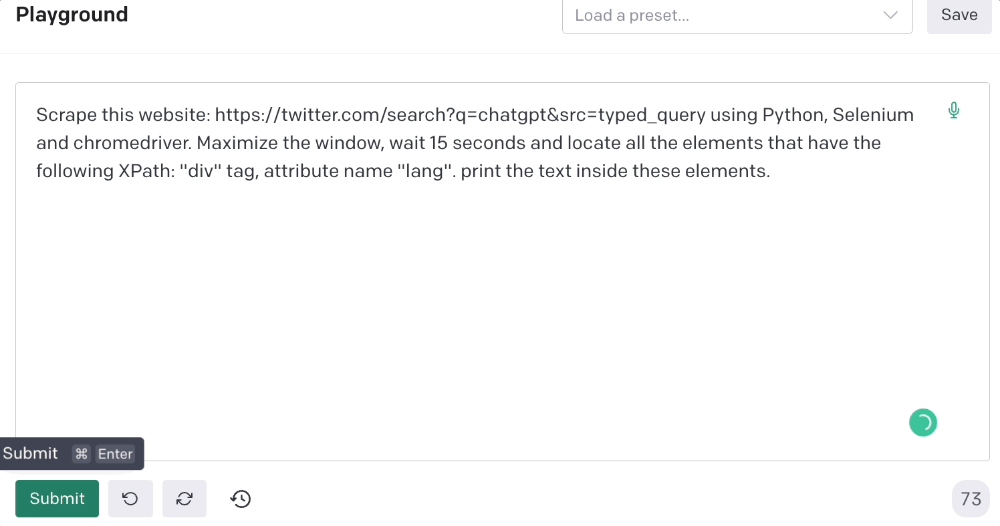
Code generated: (again, I had to add the path where my chromedriver is located)
from selenium import webdriver
import time
driver = webdriver.Chrome("/Users/frankandrade/Downloads/chromedriver")
driver.maximize_window()
driver.get("https://twitter.com/search?q=chatgpt&src=typed_query")
time.sleep(15)
elements = driver.find_elements_by_xpath("//div[@lang]")
for element in elements:
print(element.text)
driver.quit()You'll get the first 2 or 3 tweets from a search. To scrape additional tweets, click X times.
Congratulations! You scraped websites without coding by using ChatGPT.

Shalitha Suranga
3 years ago
The Top 5 Mathematical Concepts Every Programmer Needs to Know
Using math to write efficient code in any language

Programmers design, build, test, and maintain software. Employ cases and personal preferences determine the programming languages we use throughout development. Mobile app developers use JavaScript or Dart. Some programmers design performance-first software in C/C++.
A generic source code includes language-specific grammar, pre-implemented function calls, mathematical operators, and control statements. Some mathematical principles assist us enhance our programming and problem-solving skills.
We all use basic mathematical concepts like formulas and relational operators (aka comparison operators) in programming in our daily lives. Beyond these mathematical syntaxes, we'll see discrete math topics. This narrative explains key math topics programmers must know. Master these ideas to produce clean and efficient software code.
Expressions in mathematics and built-in mathematical functions
A source code can only contain a mathematical algorithm or prebuilt API functions. We develop source code between these two ends. If you create code to fetch JSON data from a RESTful service, you'll invoke an HTTP client and won't conduct any math. If you write a function to compute the circle's area, you conduct the math there.
When your source code gets more mathematical, you'll need to use mathematical functions. Every programming language has a math module and syntactical operators. Good programmers always consider code readability, so we should learn to write readable mathematical expressions.
Linux utilizes clear math expressions.
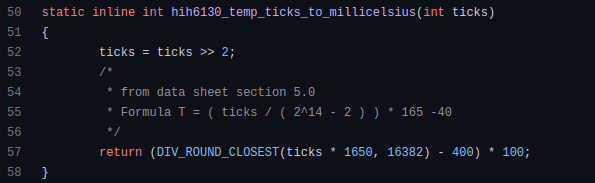
Inbuilt max and min functions can minimize verbose if statements.
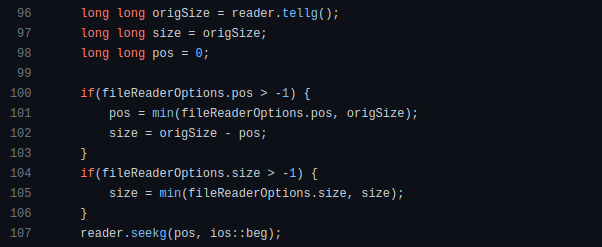
How can we compute the number of pages needed to display known data? In such instances, the ceil function is often utilized.
import math as m
results = 102
items_per_page = 10
pages = m.ceil(results / items_per_page)
print(pages)Learn to write clear, concise math expressions.
Combinatorics in Algorithm Design
Combinatorics theory counts, selects, and arranges numbers or objects. First, consider these programming-related questions. Four-digit PIN security? what options exist? What if the PIN has a prefix? How to locate all decimal number pairs?
Combinatorics questions. Software engineering jobs often require counting items. Combinatorics counts elements without counting them one by one or through other verbose approaches, therefore it enables us to offer minimum and efficient solutions to real-world situations. Combinatorics helps us make reliable decision tests without missing edge cases. Write a program to see if three inputs form a triangle. This is a question I commonly ask in software engineering interviews.
Graph theory is a subfield of combinatorics. Graph theory is used in computerized road maps and social media apps.
Logarithms and Geometry Understanding
Geometry studies shapes, angles, and sizes. Cartesian geometry involves representing geometric objects in multidimensional planes. Geometry is useful for programming. Cartesian geometry is useful for vector graphics, game development, and low-level computer graphics. We can simply work with 2D and 3D arrays as plane axes.
GetWindowRect is a Windows GUI SDK geometric object.
High-level GUI SDKs and libraries use geometric notions like coordinates, dimensions, and forms, therefore knowing geometry speeds up work with computer graphics APIs.
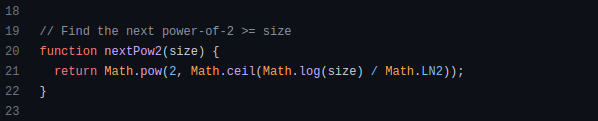
How does exponentiation's inverse function work? Logarithm is exponentiation's inverse function. Logarithm helps programmers find efficient algorithms and solve calculations. Writing efficient code involves finding algorithms with logarithmic temporal complexity. Programmers prefer binary search (O(log n)) over linear search (O(n)). Git source specifies O(log n):
Logarithms aid with programming math. Metas Watchman uses a logarithmic utility function to find the next power of two.
Employing Mathematical Data Structures
Programmers must know data structures to develop clean, efficient code. Stack, queue, and hashmap are computer science basics. Sets and graphs are discrete arithmetic data structures. Most computer languages include a set structure to hold distinct data entries. In most computer languages, graphs can be represented using neighboring lists or objects.
Using sets as deduped lists is powerful because set implementations allow iterators. Instead of a list (or array), store WebSocket connections in a set.
Most interviewers ask graph theory questions, yet current software engineers don't practice algorithms. Graph theory challenges become obligatory in IT firm interviews.
Recognizing Applications of Recursion
A function in programming isolates input(s) and output(s) (s). Programming functions may have originated from mathematical function theories. Programming and math functions are different but similar. Both function types accept input and return value.
Recursion involves calling the same function inside another function. In its implementation, you'll call the Fibonacci sequence. Recursion solves divide-and-conquer software engineering difficulties and avoids code repetition. I recently built the following recursive Dart code to render a Flutter multi-depth expanding list UI:
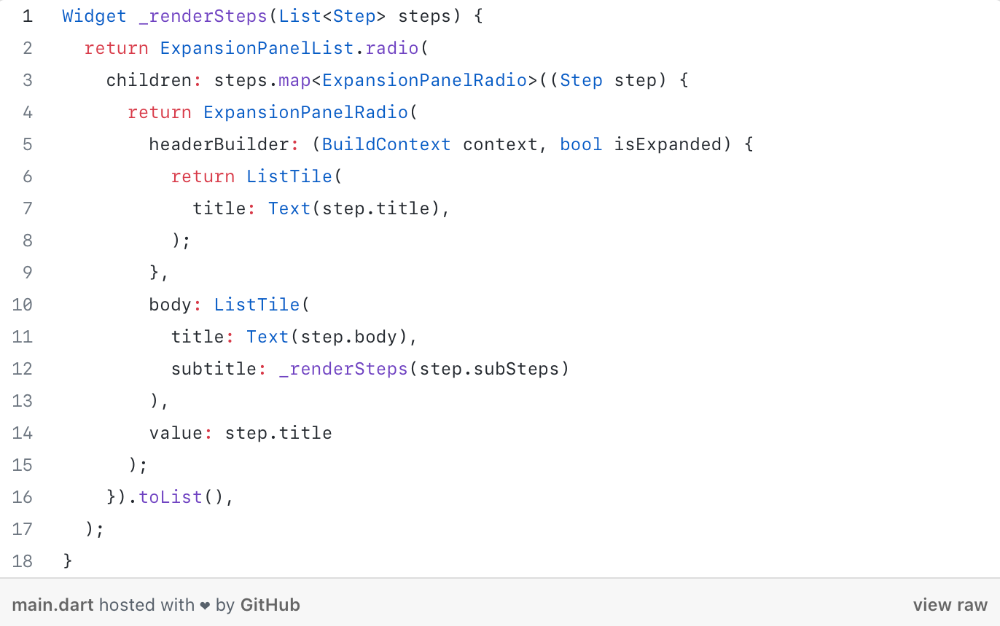
Recursion is not the natural linear way to solve problems, hence thinking recursively is difficult. Everything becomes clear when a mathematical function definition includes a base case and recursive call.
Conclusion
Every codebase uses arithmetic operators, relational operators, and expressions. To build mathematical expressions, we typically employ log, ceil, floor, min, max, etc. Combinatorics, geometry, data structures, and recursion help implement algorithms. Unless you operate in a pure mathematical domain, you may not use calculus, limits, and other complex math in daily programming (i.e., a game engine). These principles are fundamental for daily programming activities.
Master the above math fundamentals to build clean, efficient code.
You might also like

Tim Smedley
3 years ago
When Investment in New Energy Surpassed That in Fossil Fuels (Forever)
A worldwide energy crisis might have hampered renewable energy and clean tech investment. Nope.
BNEF's 2023 Energy Transition Investment Trends study surprised and encouraged. Global energy transition investment reached $1 trillion for the first time ($1.11t), up 31% from 2021. From 2013, the clean energy transition has come and cannot be reversed.
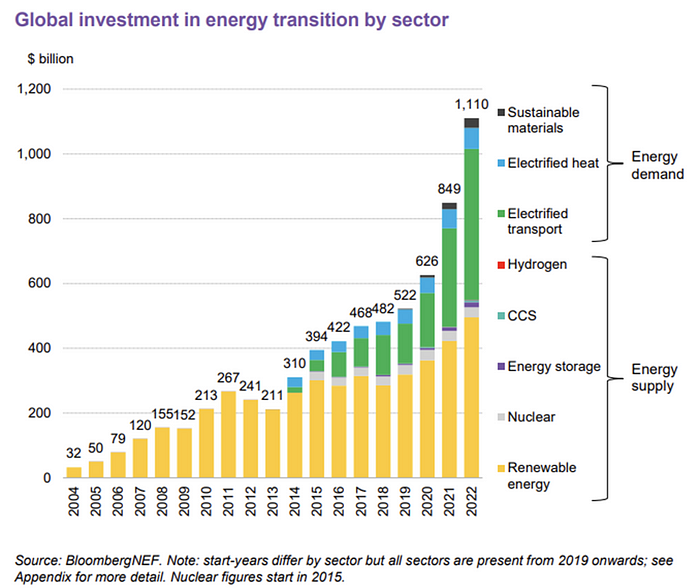
BNEF Head of Global Analysis Albert Cheung said our findings ended the energy crisis's influence on renewable energy deployment. Energy transition investment has reached a record as countries and corporations implement transition strategies. Clean energy investments will soon surpass fossil fuel investments.
The table below indicates the tripping point, which means the energy shift is occuring today.
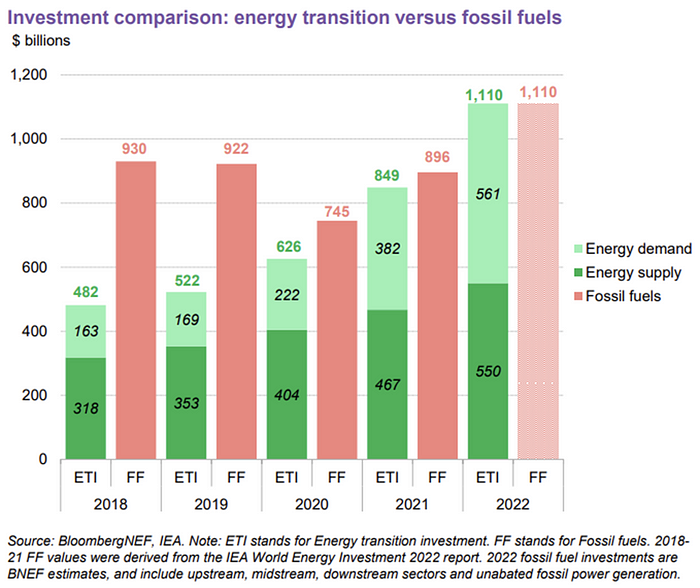
BNEF calls money invested on clean technology including electric vehicles, heat pumps, hydrogen, and carbon capture energy transition investment. In 2022, electrified heat received $64b and energy storage $15.7b.
Nonetheless, $495b in renewables (up 17%) and $466b in electrified transport (up 54%) account for most of the investment. Hydrogen and carbon capture are tiny despite the fanfare. Hydrogen received the least funding in 2022 at $1.1 billion (0.1%).
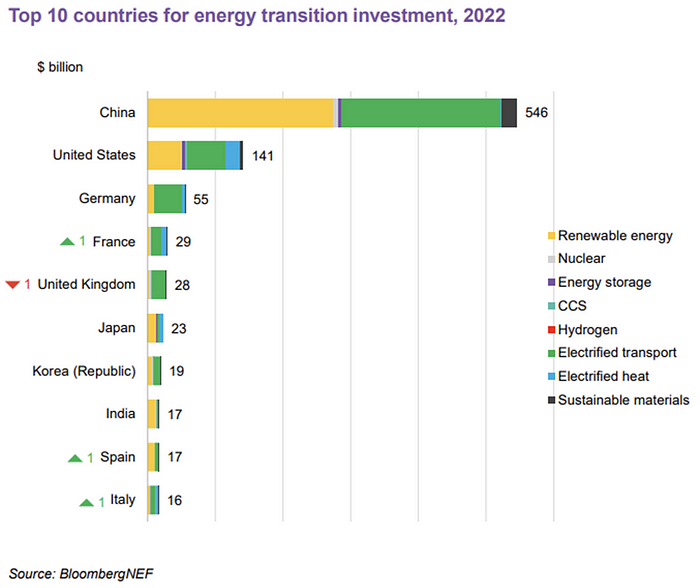
China dominates investment. China spends $546 billion on energy transition, half the global amount. Second, the US total of $141 billion in 2022 was up 11% from 2021. With $180 billion, the EU is unofficially second. China invested 91% in battery technologies.
The 2022 transition tipping point is encouraging, but the BNEF research shows how far we must go to get Net Zero. Energy transition investment must average $4.55 trillion between 2023 and 2030—three times the amount spent in 2022—to reach global Net Zero. Investment must be seven times today's record to reach Net Zero by 2050.
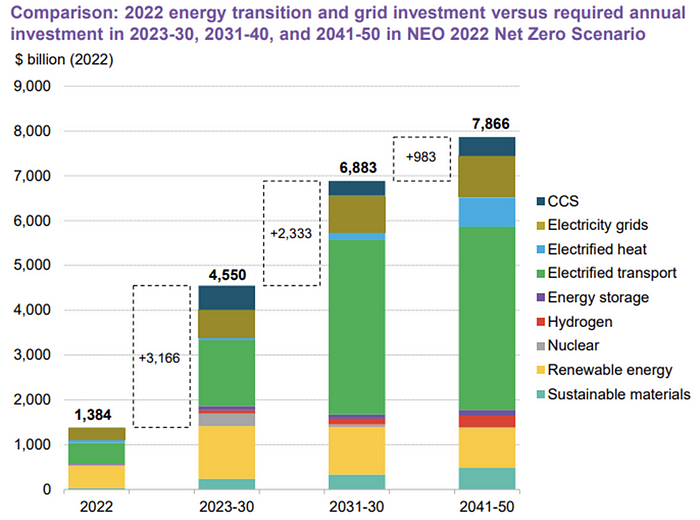
BNEF 2023 Energy Transition Investment Trends.
As shown in the graph above, BNEF experts have been using their crystal balls to determine where that investment should go. CCS and hydrogen are still modest components of the picture. Interestingly, they see nuclear almost fading. Active transport advocates like me may have something to say about the massive $4b in electrified transport. If we focus on walkable 15-minute cities, we may need fewer electric automobiles. Though we need more electric trains and buses.
Albert Cheung of BNEF emphasizes the challenge. This week's figures promise short-term job creation and medium-term energy security, but more investment is needed to reach net zero in the long run.
I expect the BNEF Energy Transition Investment Trends report to show clean tech investment outpacing fossil fuels investment every year. Finally saying that is amazing. It's insufficient. The planet must maintain its electric (not gas) pedal. In response to the research, Christina Karapataki, VC at Breakthrough Energy Ventures, a clean tech investment firm, tweeted: Clean energy investment needs to average more than 3x this level, for the remainder of this decade, to get on track for BNEFs Net Zero Scenario. Go!

Aaron Dinin, PhD
3 years ago
I put my faith in a billionaire, and he destroyed my business.
How did his money blind me?

Like most fledgling entrepreneurs, I wanted a mentor. I met as many nearby folks with "entrepreneur" in their LinkedIn biographies for coffee.
These meetings taught me a lot, and I'd suggest them to any new creator. Attention! Meeting with many experienced entrepreneurs means getting contradictory advice. One entrepreneur will tell you to do X, then the next one you talk to may tell you to do Y, which are sometimes opposites. You'll have to chose which suggestion to take after the chats.
I experienced this. Same afternoon, I had two coffee meetings with experienced entrepreneurs. The first meeting was with a billionaire entrepreneur who took his company public.
I met him in a swanky hotel lobby and ordered a drink I didn't pay for. As a fledgling entrepreneur, money was scarce.
During the meeting, I demoed the software I'd built, he liked it, and we spent the hour discussing what features would make it a success. By the end of the meeting, he requested I include a killer feature we both agreed would attract buyers. The feature was complex and would require some time. The billionaire I was sipping coffee with in a beautiful hotel lobby insisted people would love it, and that got me enthusiastic.
The second meeting was with a young entrepreneur who had recently raised a small amount of investment and looked as eager to pitch me as I was to pitch him. I forgot his name. I mostly recall meeting him in a filthy coffee shop in a bad section of town and buying his pricey cappuccino. Water for me.
After his pitch, I demoed my app. When I was done, he barely noticed. He questioned my customer acquisition plan. Who was my client? What did they offer? What was my plan? Etc. No decent answers.
After our meeting, he insisted I spend more time learning my market and selling. He ignored my questions about features. Don't worry about features, he said. Customers will request features. First, find them.
Putting your faith in results over relevance
Problems plagued my afternoon. I met with two entrepreneurs who gave me differing advice about how to proceed, and I had to decide which to pursue. I couldn't decide.
Ultimately, I followed the advice of the billionaire.
Obviously.
Who wouldn’t? That was the guy who clearly knew more.
A few months later, I constructed the feature the billionaire said people would line up for.
The new feature was unpopular. I couldn't even get the billionaire to answer an email showing him what I'd done. He disappeared.
Within a few months, I shut down the company, wasting all the time and effort I'd invested into constructing the killer feature the billionaire said I required.
Would follow the struggling entrepreneur's advice have saved my company? It would have saved me time in retrospect. Potential consumers would have told me they didn't want what I was producing, and I could have shut down the company sooner or built something they did want. Both outcomes would have been better.
Now I know, but not then. I favored achievement above relevance.
Success vs. relevance
The millionaire gave me advice on building a large, successful public firm. A successful public firm is different from a startup. Priorities change in the last phase of business building, which few entrepreneurs reach. He gave wonderful advice to founders trying to double their stock values in two years, but it wasn't beneficial for me.
The other failing entrepreneur had relevant, recent experience. He'd recently been in my shoes. We still had lots of problems. He may not have achieved huge success, but he had valuable advice on how to pass the closest hurdle.
The money blinded me at the moment. Not alone So much of company success is defined by money valuations, fundraising, exits, etc., so entrepreneurs easily fall into this trap. Money chatter obscures the value of knowledge.
Don't base startup advice on a person's income. Focus on what and when the person has learned. Relevance to you and your goals is more important than a person's accomplishments when considering advice.

Woo
3 years ago
How To Launch A Business Without Any Risk
> Say Hello To The Lean-Hedge Model
People think starting a business requires significant debt and investment. Like Shark Tank, you need a world-changing idea. I'm not saying to avoid investors or brilliant ideas.
Investing is essential to build a genuinely profitable company. Think Apple or Starbucks.
Entrepreneurship is risky because many people go bankrupt from debt. As starters, we shouldn't do it. Instead, use lean-hedge.
Simply defined, you construct a cash-flow business to hedge against long-term investment-heavy business expenses.
What the “fx!$rench-toast” is the lean-hedge model?
When you start a business, your money should move down, down, down, then up when it becomes profitable.
Many people don't survive the business's initial losses and debt. What if, we created a cash-flow business BEFORE we started our Starbucks to hedge against its initial expenses?
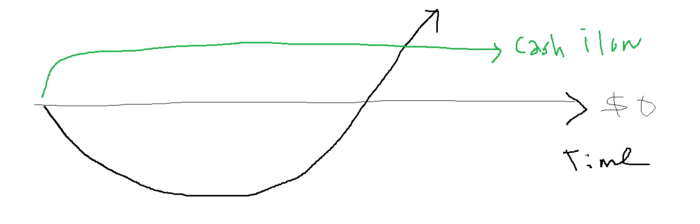
Lean-hedge has two sections. Start a cash-flow business. A cash-flow business takes minimal investment and usually involves sweat and time.
Let’s take a look at some examples:
A Translation company
Personal portfolio website (you make a site then you do cold e-mail marketing)
FREELANCE (UpWork, Fiverr).
Educational business.
Infomarketing. (You design a knowledge-based product. You sell the info).
Online fitness/diet/health coaching ($50-$300/month, calls, training plan)
Amazon e-book publishing. (Medium writers do this)
YouTube, cash-flow channel
A web development agency (I'm a dev, but if you're not, a graphic design agency, etc.) (Sell your time.)
Digital Marketing
Online paralegal (A million lawyers work in the U.S).
Some dropshipping (Organic Tik Tok dropshipping, where you create content to drive traffic to your shopify store instead of spend money on ads).
(Disclaimer: My first two cash-flow enterprises, which were language teaching, failed terribly. My translation firm is now booming because B2B e-mail marketing is easy.)
Crossover occurs. Your long-term business starts earning more money than your cash flow business.
My cash-flow business (freelancing, translation) makes $7k+/month.
I’ve decided to start a slightly more investment-heavy digital marketing agency
Here are the anticipated business's time- and money-intensive investments:
($$$) Top Front-End designer's Figma/UI-UX design (in negotiation)
(Time): A little copywriting (I will do this myself)
($$) Creating an animated webpage with HTML (in negotiation)
Backend Development (Duration) (I'll carry out this myself using Laravel.)
Logo Design ($$)
Logo Intro Video for $
Video Intro (I’ll edit this myself with Premiere Pro)
etc.
Then evaluate product, place, price, and promotion. Consider promotion and pricing.
The lean-hedge model's point is:
Don't gamble. Avoid debt. First create a cash-flow project, then grow it steadily.
Check read my previous posts on “Nightmare Mode” (which teaches you how to make work as interesting as video games) and Why most people can't escape a 9-5 to learn how to develop a cash-flow business.