



More on Personal Growth

Sad NoCoiner
3 years ago
Two Key Money Principles You Should Understand But Were Never Taught

Prudence is advised. Be debt-free. Be frugal. Spend less.
This advice sounds nice, but it rarely works.
Most people never learn these two money rules. Both approaches will impact how you see personal finance.
It may safeguard you from inflation or the inability to preserve money.
Let’s dive in.
#1: Making long-term debt your ally
High-interest debt hurts consumers. Many credit cards carry 25% yearly interest (or more), so always pay on time. Otherwise, you’re losing money.
Some low-interest debt is good. Especially when buying an appreciating asset with borrowed money.
Inflation helps you.
If you borrow $800,000 at 3% interest and invest it at 7%, you'll make $32,000 (4%).
As money loses value, fixed payments get cheaper. Your assets' value and cash flow rise.
The never-in-debt crowd doesn't know this. They lose money paying off mortgages and low-interest loans early when they could have bought assets instead.
#2: How To Buy Or Build Assets To Make Inflation Irrelevant
Dozens of studies demonstrate actual wage growth is static; $2.50 in 1964 was equivalent to $22.65 now.
These reports never give solutions unless they're selling gold.
But there is one.
Assets beat inflation.
$100 invested into the S&P 500 would have an inflation-adjusted return of 17,739.30%.
Likewise, you can build assets from nothing. Doing is easy and quick. The returns can boost your income by 10% or more.
The people who obsess over inflation inadvertently make the problem worse for themselves. They wait for The Big Crash to buy assets. Or they moan about debt clocks and spending bills instead of seeking a solution.
Conclusion
Being ultra-prudent is like playing golf with a putter to avoid hitting the ball into the water. Sure, you might not slice a drive into the pond. But, you aren’t going to play well either. Or have very much fun.
Money has rules.
Avoiding debt or investment risks will limit your rewards. Long-term, being too cautious hurts your finances.
Disclaimer: This article is for entertainment purposes only. It is not financial advice, always do your own research.

James White
3 years ago
I read three of Elon Musk's suggested books (And His Taste Is Incredible)
A reading list for successful people

Elon Musk reads and talks. So, one learns. Many brilliant individuals & amazing literature.
This article recommends 3 Elon Musk novels. All of them helped me succeed. Hope they'll help you.
Douglas Adams's The Hitchhiker's Guide to the Galaxy
Page Count: 193
Rating on Goodreads: 4.23
Arthur Dent is pulled off Earth by a buddy seconds before it's razed for a cosmic motorway. The trio hitchhikes through space and gets into problems.
I initially read Hitchhiker's as a child. To evade my mum, I'd read with a flashlight under the covers. She'd scold at me for not sleeping on school nights when she found out. Oops.
The Hitchhiker's Guide to the Galaxy is lighthearted science fiction.

My favorite book quotes are:
“Space is big. You won’t believe how vastly, hugely, mind-bogglingly big it is. I mean, you may think it’s a long way down the road to the chemist’s, but that’s just peanuts to space.”
“Far out in the uncharted backwaters of the unfashionable end of the western spiral arm of the Galaxy lies a small unregarded yellow sun. Orbiting this at a distance of roughly ninety-two million miles is an utterly insignificant little blue-green planet whose ape-descended life forms are so amazingly primitive that they still think digital watches are a pretty neat idea.”
“On planet Earth, man had always assumed that he was more intelligent than dolphins because he had achieved so much — the wheel, New York, wars, and so on — whilst all the dolphins had ever done was muck about in the water having a good time. But conversely, the dolphins had always believed that they were far more intelligent than man — for precisely the same reasons.”
the Sun Tzu book The Art Of War
Page Count: 273
Rating on Goodreads: 3.97
It's a classic. You may apply The Art of War's ideas to (nearly) every facet of life. Ex:
Pick your fights.
Keep in mind that timing is crucial.
Create a backup plan in case something goes wrong.
Obstacles provide us a chance to adapt and change.
This book was my first. Since then, I'm a more strategic entrepreneur. Excellent book. And read it ASAP!

My favorite book quotes are:
“Victorious warriors win first and then go to war, while defeated warriors go to war first and then seek to win.”
“Engage people with what they expect; it is what they are able to discern and confirms their projections. It settles them into predictable patterns of response, occupying their minds while you wait for the extraordinary moment — that which they cannot anticipate.”
“If you know the enemy and know yourself, you need not fear the result of a hundred battles. If you know yourself but not the enemy, for every victory gained, you will also suffer a defeat. If you know neither the enemy nor yourself, you will succumb in every battle.”
Peter Thiel's book Zero to One
Page Count: 195
Rating on Goodreads: 4.18
Peter argues the best money-making strategies are typically unproven. Entrepreneurship should never have a defined path to success. Whoever says differently is lying.
Zero to One explores technology and society. Peter is a philosophy major and law school graduate, which informs the work.
Peters' ideas, depth, and intellect stood out in Zero to One. It's a top business book.

My favorite book quotes are:
“The most valuable businesses of coming decades will be built by entrepreneurs who seek to empower people rather than try to make them obsolete.”
“The next Bill Gates will not build an operating system. The next Larry Page or Sergey Brin won’t make a search engine. And the next Mark Zuckerberg won’t create a social network. If you are copying these guys, you aren’t learning from them.”
“If your goal is to never make a mistake in your life, you shouldn’t look for secrets. The prospect of being lonely but right — dedicating your life to something that no one else believes in — is already hard. The prospect of being lonely and wrong can be unbearable.”

Samer Buna
3 years ago
The Errors I Committed As a Novice Programmer
Learn to identify them, make habits to avoid them

First, a clarification. This article is aimed to make new programmers aware of their mistakes, train them to detect them, and remind them to prevent them.
I learned from all these blunders. I'm glad I have coding habits to avoid them. Do too.
These mistakes are not ordered.
1) Writing code haphazardly
Writing good content is hard. It takes planning and investigation. Quality programs don't differ.
Think. Research. Plan. Write. Validate. Modify. Unfortunately, no good acronym exists. Create a habit of doing the proper quantity of these activities.
As a newbie programmer, my biggest error was writing code without thinking or researching. This works for small stand-alone apps but hurts larger ones.
Like saying anything you might regret, you should think before coding something you could regret. Coding expresses your thoughts.
When angry, count to 10 before you speak. If very angry, a hundred. — Thomas Jefferson.
My quote:
When reviewing code, count to 10 before you refactor a line. If the code does not have tests, a hundred. — Samer Buna
Programming is primarily about reviewing prior code, investigating what is needed and how it fits into the current system, and developing small, testable features. Only 10% of the process involves writing code.
Programming is not writing code. Programming need nurturing.
2) Making excessive plans prior to writing code
Yes. Planning before writing code is good, but too much of it is bad. Water poisons.
Avoid perfect plans. Programming does not have that. Find a good starting plan. Your plan will change, but it helped you structure your code for clarity. Overplanning wastes time.
Only planning small features. All-feature planning should be illegal! The Waterfall Approach is a step-by-step system. That strategy requires extensive planning. This is not planning. Most software projects fail with waterfall. Implementing anything sophisticated requires agile changes to reality.
Programming requires responsiveness. You'll add waterfall plan-unthinkable features. You will eliminate functionality for reasons you never considered in a waterfall plan. Fix bugs and adjust. Be agile.
Plan your future features, though. Do it cautiously since too little or too much planning can affect code quality, which you must risk.
3) Underestimating the Value of Good Code
Readability should be your code's exclusive goal. Unintelligible code stinks. Non-recyclable.
Never undervalue code quality. Coding communicates implementations. Coders must explicitly communicate solution implementations.
Programming quote I like:
Always code as if the guy who ends up maintaining your code will be a violent psychopath who knows where you live. — John Woods
John, great advice!
Small things matter. If your indentation and capitalization are inconsistent, you should lose your coding license.
Long queues are also simple. Readability decreases after 80 characters. To highlight an if-statement block, you might put a long condition on the same line. No. Just never exceed 80 characters.
Linting and formatting tools fix many basic issues like this. ESLint and Prettier work great together in JavaScript. Use them.
Code quality errors:
Multiple lines in a function or file. Break long code into manageable bits. My rule of thumb is that any function with more than 10 lines is excessively long.
Double-negatives. Don't.
Using double negatives is just very not not wrong
Short, generic, or type-based variable names. Name variables clearly.
There are only two hard things in Computer Science: cache invalidation and naming things. — Phil Karlton
Hard-coding primitive strings and numbers without descriptions. If your logic relies on a constant primitive string or numeric value, identify it.
Avoiding simple difficulties with sloppy shortcuts and workarounds. Avoid evasion. Take stock.
Considering lengthier code better. Shorter code is usually preferable. Only write lengthier versions if they improve code readability. For instance, don't utilize clever one-liners and nested ternary statements just to make the code shorter. In any application, removing unneeded code is better.
Measuring programming progress by lines of code is like measuring aircraft building progress by weight. — Bill Gates
Excessive conditional logic. Conditional logic is unnecessary for most tasks. Choose based on readability. Measure performance before optimizing. Avoid Yoda conditions and conditional assignments.
4) Selecting the First Approach
When I started programming, I would solve an issue and move on. I would apply my initial solution without considering its intricacies and probable shortcomings.
After questioning all the solutions, the best ones usually emerge. If you can't think of several answers, you don't grasp the problem.
Programmers do not solve problems. Find the easiest solution. The solution must work well and be easy to read, comprehend, and maintain.
There are two ways of constructing a software design. One way is to make it so simple that there are obviously no deficiencies, and the other way is to make it so complicated that there are no obvious deficiencies. — C.A.R. Hoare
5) Not Giving Up
I generally stick with the original solution even though it may not be the best. The not-quitting mentality may explain this. This mindset is helpful for most things, but not programming. Program writers should fail early and often.
If you doubt a solution, toss it and rethink the situation. No matter how much you put in that solution. GIT lets you branch off and try various solutions. Use it.
Do not be attached to code because of how much effort you put into it. Bad code needs to be discarded.
6) Avoiding Google
I've wasted time solving problems when I should have researched them first.
Unless you're employing cutting-edge technology, someone else has probably solved your problem. Google It First.
Googling may discover that what you think is an issue isn't and that you should embrace it. Do not presume you know everything needed to choose a solution. Google surprises.
But Google carefully. Newbies also copy code without knowing it. Use only code you understand, even if it solves your problem.
Never assume you know how to code creatively.
The most dangerous thought that you can have as a creative person is to think that you know what you’re doing. — Bret Victor
7) Failing to Use Encapsulation
Not about object-oriented paradigm. Encapsulation is always useful. Unencapsulated systems are difficult to maintain.
An application should only handle a feature once. One object handles that. The application's other objects should only see what's essential. Reducing application dependencies is not about secrecy. Following these guidelines lets you safely update class, object, and function internals without breaking things.
Classify logic and state concepts. Class means blueprint template. Class or Function objects are possible. It could be a Module or Package.
Self-contained tasks need methods in a logic class. Methods should accomplish one thing well. Similar classes should share method names.
As a rookie programmer, I didn't always establish a new class for a conceptual unit or recognize self-contained units. Newbie code has a Util class full of unrelated code. Another symptom of novice code is when a small change cascades and requires numerous other adjustments.
Think before adding a method or new responsibilities to a method. Time's needed. Avoid skipping or refactoring. Start right.
High Cohesion and Low Coupling involves grouping relevant code in a class and reducing class dependencies.
8) Arranging for Uncertainty
Thinking beyond your solution is appealing. Every line of code will bring up what-ifs. This is excellent for edge cases but not for foreseeable needs.
Your what-ifs must fall into one of these two categories. Write only code you need today. Avoid future planning.
Writing a feature for future use is improper. No.
Write only the code you need today for your solution. Handle edge-cases, but don't introduce edge-features.
Growth for the sake of growth is the ideology of the cancer cell. — Edward Abbey
9) Making the incorrect data structure choices
Beginner programmers often overemphasize algorithms when preparing for interviews. Good algorithms should be identified and used when needed, but memorizing them won't make you a programming genius.
However, learning your language's data structures' strengths and shortcomings will make you a better developer.
The improper data structure shouts "newbie coding" here.
Let me give you a few instances of data structures without teaching you:
Managing records with arrays instead of maps (objects).
Most data structure mistakes include using lists instead of maps to manage records. Use a map to organize a list of records.
This list of records has an identifier to look up each entry. Lists for scalar values are OK and frequently superior, especially if the focus is pushing values to the list.
Arrays and objects are the most common JavaScript list and map structures, respectively (there is also a map structure in modern JavaScript).
Lists over maps for record management often fail. I recommend always using this point, even though it only applies to huge collections. This is crucial because maps are faster than lists in looking up records by identifier.
Stackless
Simple recursive functions are often tempting when writing recursive programming. In single-threaded settings, optimizing recursive code is difficult.
Recursive function returns determine code optimization. Optimizing a recursive function that returns two or more calls to itself is harder than optimizing a single call.
Beginners overlook the alternative to recursive functions. Use Stack. Push function calls to a stack and start popping them out to traverse them back.
10) Worsening the current code
Imagine this:

Add an item to that room. You might want to store that object anywhere as it's a mess. You can finish in seconds.
Not with messy code. Do not worsen! Keep the code cleaner than when you started.
Clean the room above to place the new object. If the item is clothing, clear a route to the closet. That's proper execution.
The following bad habits frequently make code worse:
code duplication You are merely duplicating code and creating more chaos if you copy/paste a code block and then alter just the line after that. This would be equivalent to adding another chair with a lower base rather than purchasing a new chair with a height-adjustable seat in the context of the aforementioned dirty room example. Always keep abstraction in mind, and use it when appropriate.
utilizing configuration files not at all. A configuration file should contain the value you need to utilize if it may differ in certain circumstances or at different times. A configuration file should contain a value if you need to use it across numerous lines of code. Every time you add a new value to the code, simply ask yourself: "Does this value belong in a configuration file?" The most likely response is "yes."
using temporary variables and pointless conditional statements. Every if-statement represents a logic branch that should at the very least be tested twice. When avoiding conditionals doesn't compromise readability, it should be done. The main issue with this is that branch logic is being used to extend an existing function rather than creating a new function. Are you altering the code at the appropriate level, or should you go think about the issue at a higher level every time you feel you need an if-statement or a new function variable?
This code illustrates superfluous if-statements:
function isOdd(number) {
if (number % 2 === 1) {
return true;
} else {
return false;
}
}Can you spot the biggest issue with the isOdd function above?
Unnecessary if-statement. Similar code:
function isOdd(number) {
return (number % 2 === 1);
};11) Making remarks on things that are obvious
I've learnt to avoid comments. Most code comments can be renamed.
instead of:
// This function sums only odd numbers in an array
const sum = (val) => {
return val.reduce((a, b) => {
if (b % 2 === 1) { // If the current number is odd
a+=b; // Add current number to accumulator
}
return a; // The accumulator
}, 0);
};Commentless code looks like this:
const sumOddValues = (array) => {
return array.reduce((accumulator, currentNumber) => {
if (isOdd(currentNumber)) {
return accumulator + currentNumber;
}
return accumulator;
}, 0);
};Better function and argument names eliminate most comments. Remember that before commenting.
Sometimes you have to use comments to clarify the code. This is when your comments should answer WHY this code rather than WHAT it does.
Do not write a WHAT remark to clarify the code. Here are some unnecessary comments that clutter code:
// create a variable and initialize it to 0
let sum = 0;
// Loop over array
array.forEach(
// For each number in the array
(number) => {
// Add the current number to the sum variable
sum += number;
}
);Avoid that programmer. Reject that code. Remove such comments if necessary. Most importantly, teach programmers how awful these remarks are. Tell programmers who publish remarks like this that they may lose their jobs. That terrible.
12) Skipping tests
I'll simplify. If you develop code without tests because you think you're an excellent programmer, you're a rookie.
If you're not writing tests in code, you're probably testing manually. Every few lines of code in a web application will be refreshed and interacted with. Also. Manual code testing is fine. To learn how to automatically test your code, manually test it. After testing your application, return to your code editor and write code to automatically perform the same interaction the next time you add code.
Human. After each code update, you will forget to test all successful validations. Automate it!
Before writing code to fulfill validations, guess or design them. TDD is real. It improves your feature design thinking.
If you can use TDD, even partially, do so.
13) Making the assumption that if something is working, it must be right.
See this sumOddValues function. Is it flawed?
const sumOddValues = (array) => {
return array.reduce((accumulator, currentNumber) => {
if (currentNumber % 2 === 1) {
return accumulator + currentNumber;
}
return accumulator;
});
};
console.assert(
sumOddValues([1, 2, 3, 4, 5]) === 9
);Verified. Good life. Correct?
Code above is incomplete. It handles some scenarios correctly, including the assumption used, but it has many other issues. I'll list some:
#1: No empty input handling. What happens when the function is called without arguments? That results in an error revealing the function's implementation:
TypeError: Cannot read property 'reduce' of undefined.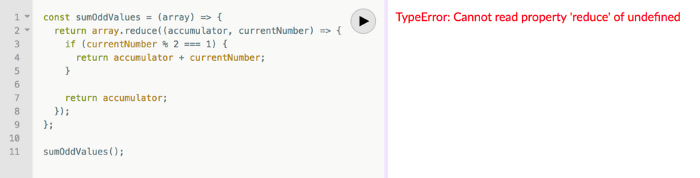
Two main factors indicate faulty code.
Your function's users shouldn't come across implementation-related information.
The user cannot benefit from the error. Simply said, they were unable to use your function. They would be aware that they misused the function if the error was more obvious about the usage issue. You might decide to make the function throw a custom exception, for instance:
TypeError: Cannot execute function for empty list.Instead of returning an error, your method should disregard empty input and return a sum of 0. This case requires action.
Problem #2: No input validation. What happens if the function is invoked with a text, integer, or object instead of an array?
The function now throws:
sumOddValues(42);
TypeError: array.reduce is not a functionUnfortunately, array. cut's a function!
The function labels anything you call it with (42 in the example above) as array because we named the argument array. The error says 42.reduce is not a function.
See how that error confuses? An mistake like:
TypeError: 42 is not an array, dude.Edge-cases are #1 and #2. These edge-cases are typical, but you should also consider less obvious ones. Negative numbers—what happens?
sumOddValues([1, 2, 3, 4, 5, -13]) // => still 9-13's unusual. Is this the desired function behavior? Error? Should it sum negative numbers? Should it keep ignoring negative numbers? You may notice the function should have been titled sumPositiveOddNumbers.
This decision is simple. The more essential point is that if you don't write a test case to document your decision, future function maintainers won't know if you ignored negative values intentionally or accidentally.
It’s not a bug. It’s a feature. — Someone who forgot a test case
#3: Valid cases are not tested. Forget edge-cases, this function mishandles a straightforward case:
sumOddValues([2, 1, 3, 4, 5]) // => 11The 2 above was wrongly included in sum.
The solution is simple: reduce accepts a second input to initialize the accumulator. Reduce will use the first value in the collection as the accumulator if that argument is not provided, like in the code above. The sum included the test case's first even value.
This test case should have been included in the tests along with many others, such as all-even numbers, a list with 0 in it, and an empty list.
Newbie code also has rudimentary tests that disregard edge-cases.
14) Adhering to Current Law
Unless you're a lone supercoder, you'll encounter stupid code. Beginners don't identify it and assume it's decent code because it works and has been in the codebase for a while.
Worse, if the terrible code uses bad practices, the newbie may be enticed to use them elsewhere in the codebase since they learnt them from good code.
A unique condition may have pushed the developer to write faulty code. This is a nice spot for a thorough note that informs newbies about that condition and why the code is written that way.
Beginners should presume that undocumented code they don't understand is bad. Ask. Enquire. Blame it!
If the code's author is dead or can't remember it, research and understand it. Only after understanding the code can you judge its quality. Before that, presume nothing.
15) Being fixated on best practices
Best practices damage. It suggests no further research. Best practice ever. No doubts!
No best practices. Today's programming language may have good practices.
Programming best practices are now considered bad practices.
Time will reveal better methods. Focus on your strengths, not best practices.
Do not do anything because you read a quote, saw someone else do it, or heard it is a recommended practice. This contains all my article advice! Ask questions, challenge theories, know your options, and make informed decisions.
16) Being preoccupied with performance
Premature optimization is the root of all evil (or at least most of it) in programming — Donald Knuth (1974)
I think Donald Knuth's advice is still relevant today, even though programming has changed.
Do not optimize code if you cannot measure the suspected performance problem.
Optimizing before code execution is likely premature. You may possibly be wasting time optimizing.
There are obvious optimizations to consider when writing new code. You must not flood the event loop or block the call stack in Node.js. Remember this early optimization. Will this code block the call stack?
Avoid non-obvious code optimization without measurements. If done, your performance boost may cause new issues.
Stop optimizing unmeasured performance issues.
17) Missing the End-User Experience as a Goal
How can an app add a feature easily? Look at it from your perspective or in the existing User Interface. Right? Add it to the form if the feature captures user input. Add it to your nested menu of links if it adds a link to a page.
Avoid that developer. Be a professional who empathizes with customers. They imagine this feature's consumers' needs and behavior. They focus on making the feature easy to find and use, not just adding it to the software.
18) Choosing the incorrect tool for the task
Every programmer has their preferred tools. Most tools are good for one thing and bad for others.
The worst tool for screwing in a screw is a hammer. Do not use your favorite hammer on a screw. Don't use Amazon's most popular hammer on a screw.
A true beginner relies on tool popularity rather than problem fit.
You may not know the best tools for a project. You may know the best tool. However, it wouldn't rank high. You must learn your tools and be open to new ones.
Some coders shun new tools. They like their tools and don't want to learn new ones. I can relate, but it's wrong.
You can build a house slowly with basic tools or rapidly with superior tools. You must learn and use new tools.
19) Failing to recognize that data issues are caused by code issues
Programs commonly manage data. The software will add, delete, and change records.
Even the simplest programming errors can make data unpredictable. Especially if the same defective application validates all data.
Code-data relationships may be confusing for beginners. They may employ broken code in production since feature X is not critical. Buggy coding may cause hidden data integrity issues.
Worse, deploying code that corrected flaws without fixing minor data problems caused by these defects will only collect more data problems that take the situation into the unrecoverable-level category.
How do you avoid these issues? Simply employ numerous data integrity validation levels. Use several interfaces. Front-end, back-end, network, and database validations. If not, apply database constraints.
Use all database constraints when adding columns and tables:
If a column has a NOT NULL constraint, null values will be rejected for that column. If your application expects that field has a value, your database should designate its source as not null.
If a column has a UNIQUE constraint, the entire table cannot include duplicate values for that column. This is ideal for a username or email field on a Users table, for instance.
For the data to be accepted, a CHECK constraint, or custom expression, must evaluate to true. For instance, you can apply a check constraint to ensure that the values of a normal % column must fall within the range of 0 and 100.
With a PRIMARY KEY constraint, the values of the columns must be both distinct and not null. This one is presumably what you're utilizing. To distinguish the records in each table, the database needs have a primary key.
A FOREIGN KEY constraint requires that the values in one database column, typically a primary key, match those in another table column.
Transaction apathy is another data integrity issue for newbies. If numerous actions affect the same data source and depend on each other, they must be wrapped in a transaction that can be rolled back if one fails.
20) Reinventing the Wheel
Tricky. Some programming wheels need reinvention. Programming is undefined. New requirements and changes happen faster than any team can handle.
Instead of modifying the wheel we all adore, maybe we should rethink it if you need a wheel that spins at varied speeds depending on the time of day. If you don't require a non-standard wheel, don't reinvent it. Use the darn wheel.
Wheel brands can be hard to choose from. Research and test before buying! Most software wheels are free and transparent. Internal design quality lets you evaluate coding wheels. Try open-source wheels. Debug and fix open-source software simply. They're easily replaceable. In-house support is also easy.
If you need a wheel, don't buy a new automobile and put your maintained car on top. Do not include a library to use a few functions. Lodash in JavaScript is the finest example. Import shuffle to shuffle an array. Don't import lodash.
21) Adopting the incorrect perspective on code reviews
Beginners often see code reviews as criticism. Dislike them. Not appreciated. Even fear them.
Incorrect. If so, modify your mindset immediately. Learn from every code review. Salute them. Observe. Most crucial, thank reviewers who teach you.
Always learning code. Accept it. Most code reviews teach something new. Use these for learning.
You may need to correct the reviewer. If your code didn't make that evident, it may need to be changed. If you must teach your reviewer, remember that teaching is one of the most enjoyable things a programmer can do.
22) Not Using Source Control
Newbies often underestimate Git's capabilities.
Source control is more than sharing your modifications. It's much bigger. Clear history is source control. The history of coding will assist address complex problems. Commit messages matter. They are another way to communicate your implementations, and utilizing them with modest commits helps future maintainers understand how the code got where it is.
Commit early and often with present-tense verbs. Summarize your messages but be detailed. If you need more than a few lines, your commit is too long. Rebase!
Avoid needless commit messages. Commit summaries should not list new, changed, or deleted files. Git commands can display that list from the commit object. The summary message would be noise. I think a big commit has many summaries per file altered.
Source control involves discoverability. You can discover the commit that introduced a function and see its context if you doubt its need or design. Commits can even pinpoint which code caused a bug. Git has a binary search within commits (bisect) to find the bug-causing commit.
Source control can be used before commits to great effect. Staging changes, patching selectively, resetting, stashing, editing, applying, diffing, reversing, and others enrich your coding flow. Know, use, and enjoy them.
I consider a Git rookie someone who knows less functionalities.
23) Excessive Use of Shared State
Again, this is not about functional programming vs. other paradigms. That's another article.
Shared state is problematic and should be avoided if feasible. If not, use shared state as little as possible.
As a new programmer, I didn't know that all variables represent shared states. All variables in the same scope can change its data. Global scope reduces shared state span. Keep new states in limited scopes and avoid upward leakage.
When numerous resources modify common state in the same event loop tick, the situation becomes severe (in event-loop-based environments). Races happen.
This shared state race condition problem may encourage a rookie to utilize a timer, especially if they have a data lock issue. Red flag. No. Never accept it.
24) Adopting the Wrong Mentality Toward Errors
Errors are good. Progress. They indicate a simple way to improve.
Expert programmers enjoy errors. Newbies detest them.
If these lovely red error warnings irritate you, modify your mindset. Consider them helpers. Handle them. Use them to advance.
Some errors need exceptions. Plan for user-defined exceptions. Ignore some mistakes. Crash and exit the app.
25) Ignoring rest periods
Humans require mental breaks. Take breaks. In the zone, you'll forget breaks. Another symptom of beginners. No compromises. Make breaks mandatory in your process. Take frequent pauses. Take a little walk to plan your next move. Reread the code.
This has been a long post. You deserve a break.

You might also like

Vitalik
4 years ago
An approximate introduction to how zk-SNARKs are possible (part 2)
If tasked with the problem of coming up with a zk-SNARK protocol, many people would make their way to this point and then get stuck and give up. How can a verifier possibly check every single piece of the computation, without looking at each piece of the computation individually? But it turns out that there is a clever solution.
Polynomials
Polynomials are a special class of algebraic expressions of the form:
- x+5
- x^4
- x^3+3x^2+3x+1
- 628x^{271}+318x^{270}+530x^{269}+…+69x+381
i.e. they are a sum of any (finite!) number of terms of the form cx^k
There are many things that are fascinating about polynomials. But here we are going to zoom in on a particular one: polynomials are a single mathematical object that can contain an unbounded amount of information (think of them as a list of integers and this is obvious). The fourth example above contained 816 digits of tau, and one can easily imagine a polynomial that contains far more.
Furthermore, a single equation between polynomials can represent an unbounded number of equations between numbers. For example, consider the equation A(x)+ B(x) = C(x). If this equation is true, then it's also true that:
- A(0)+B(0)=C(0)
- A(1)+B(1)=C(1)
- A(2)+B(2)=C(2)
- A(3)+B(3)=C(3)
And so on for every possible coordinate. You can even construct polynomials to deliberately represent sets of numbers so you can check many equations all at once. For example, suppose that you wanted to check:
- 12+1=13
- 10+8=18
- 15+8=23
- 15+13=28
You can use a procedure called Lagrange interpolation to construct polynomials A(x) that give (12,10,15,15) as outputs at some specific set of coordinates (eg. (0,1,2,3)), B(x) the outputs (1,8,8,13) on thos same coordinates, and so forth. In fact, here are the polynomials:
- A(x)=-2x^3+\frac{19}{2}x^2-\frac{19}{2}x+12
- B(x)=2x^3-\frac{19}{2}x^2+\frac{29}{2}x+1
- C(x)=5x+13
Checking the equation A(x)+B(x)=C(x) with these polynomials checks all four above equations at the same time.
Comparing a polynomial to itself
You can even check relationships between a large number of adjacent evaluations of the same polynomial using a simple polynomial equation. This is slightly more advanced. Suppose that you want to check that, for a given polynomial F, F(x+2)=F(x)+F(x+1) with the integer range {0,1…89} (so if you also check F(0)=F(1)=1, then F(100) would be the 100th Fibonacci number)
As polynomials, F(x+2)-F(x+1)-F(x) would not be exactly zero, as it could give arbitrary answers outside the range x={0,1…98}. But we can do something clever. In general, there is a rule that if a polynomial P is zero across some set S=\{x_1,x_2…x_n\} then it can be expressed as P(x)=Z(x)*H(x), where Z(x)=(x-x_1)*(x-x_2)*…*(x-x_n) and H(x) is also a polynomial. In other words, any polynomial that equals zero across some set is a (polynomial) multiple of the simplest (lowest-degree) polynomial that equals zero across that same set.
Why is this the case? It is a nice corollary of polynomial long division: the factor theorem. We know that, when dividing P(x) by Z(x), we will get a quotient Q(x) and a remainder R(x) is strictly less than that of Z(x). Since we know that P is zero on all of S, it means that R has to be zero on all of S as well. So we can simply compute R(x) via polynomial interpolation, since it's a polynomial of degree at most n-1 and we know n values (the zeros at S). Interpolating a polynomial with all zeroes gives the zero polynomial, thus R(x)=0 and H(x)=Q(x).
Going back to our example, if we have a polynomial F that encodes Fibonacci numbers (so F(x+2)=F(x)+F(x+1) across x=\{0,1…98\}), then I can convince you that F actually satisfies this condition by proving that the polynomial P(x)=F(x+2)-F(x+1)-F(x) is zero over that range, by giving you the quotient:
H(x)=\frac{F(x+2)-F(x+1)-F(x)}{Z(x)}
Where Z(x) = (x-0)*(x-1)*…*(x-98).
You can calculate Z(x) yourself (ideally you would have it precomputed), check the equation, and if the check passes then F(x) satisfies the condition!
Now, step back and notice what we did here. We converted a 100-step-long computation into a single equation with polynomials. Of course, proving the N'th Fibonacci number is not an especially useful task, especially since Fibonacci numbers have a closed form. But you can use exactly the same basic technique, just with some extra polynomials and some more complicated equations, to encode arbitrary computations with an arbitrarily large number of steps.
see part 3

Aaron Dinin, PhD
3 years ago
I put my faith in a billionaire, and he destroyed my business.
How did his money blind me?

Like most fledgling entrepreneurs, I wanted a mentor. I met as many nearby folks with "entrepreneur" in their LinkedIn biographies for coffee.
These meetings taught me a lot, and I'd suggest them to any new creator. Attention! Meeting with many experienced entrepreneurs means getting contradictory advice. One entrepreneur will tell you to do X, then the next one you talk to may tell you to do Y, which are sometimes opposites. You'll have to chose which suggestion to take after the chats.
I experienced this. Same afternoon, I had two coffee meetings with experienced entrepreneurs. The first meeting was with a billionaire entrepreneur who took his company public.
I met him in a swanky hotel lobby and ordered a drink I didn't pay for. As a fledgling entrepreneur, money was scarce.
During the meeting, I demoed the software I'd built, he liked it, and we spent the hour discussing what features would make it a success. By the end of the meeting, he requested I include a killer feature we both agreed would attract buyers. The feature was complex and would require some time. The billionaire I was sipping coffee with in a beautiful hotel lobby insisted people would love it, and that got me enthusiastic.
The second meeting was with a young entrepreneur who had recently raised a small amount of investment and looked as eager to pitch me as I was to pitch him. I forgot his name. I mostly recall meeting him in a filthy coffee shop in a bad section of town and buying his pricey cappuccino. Water for me.
After his pitch, I demoed my app. When I was done, he barely noticed. He questioned my customer acquisition plan. Who was my client? What did they offer? What was my plan? Etc. No decent answers.
After our meeting, he insisted I spend more time learning my market and selling. He ignored my questions about features. Don't worry about features, he said. Customers will request features. First, find them.
Putting your faith in results over relevance
Problems plagued my afternoon. I met with two entrepreneurs who gave me differing advice about how to proceed, and I had to decide which to pursue. I couldn't decide.
Ultimately, I followed the advice of the billionaire.
Obviously.
Who wouldn’t? That was the guy who clearly knew more.
A few months later, I constructed the feature the billionaire said people would line up for.
The new feature was unpopular. I couldn't even get the billionaire to answer an email showing him what I'd done. He disappeared.
Within a few months, I shut down the company, wasting all the time and effort I'd invested into constructing the killer feature the billionaire said I required.
Would follow the struggling entrepreneur's advice have saved my company? It would have saved me time in retrospect. Potential consumers would have told me they didn't want what I was producing, and I could have shut down the company sooner or built something they did want. Both outcomes would have been better.
Now I know, but not then. I favored achievement above relevance.
Success vs. relevance
The millionaire gave me advice on building a large, successful public firm. A successful public firm is different from a startup. Priorities change in the last phase of business building, which few entrepreneurs reach. He gave wonderful advice to founders trying to double their stock values in two years, but it wasn't beneficial for me.
The other failing entrepreneur had relevant, recent experience. He'd recently been in my shoes. We still had lots of problems. He may not have achieved huge success, but he had valuable advice on how to pass the closest hurdle.
The money blinded me at the moment. Not alone So much of company success is defined by money valuations, fundraising, exits, etc., so entrepreneurs easily fall into this trap. Money chatter obscures the value of knowledge.
Don't base startup advice on a person's income. Focus on what and when the person has learned. Relevance to you and your goals is more important than a person's accomplishments when considering advice.

Mike Tarullo
3 years ago
Even In a Crazy Market, Hire the Best People: The "First Ten" Rules
Hiring is difficult, but you shouldn't compromise on team members. Or it may suggest you need to look beyond years in a similar role/function.
Every hire should be someone we'd want as one of our first ten employees.
If you hire such people, your team will adapt, initiate, and problem-solve, and your company will grow. You'll stay nimble even as you scale, and you'll learn from your colleagues.
If you only hire for a specific role or someone who can execute the job, you'll become a cluster of optimizers, and talent will depart for a more fascinating company. A startup is continually changing, therefore you want individuals that embrace it.
As a leader, establishing ideal conditions for talent and having a real ideology should be high on your agenda. You can't eliminate attrition, nor would you want to, but you can hire people who will become your company's leaders.
In my last four jobs I was employee 2, 5, 3, and 5. So while this is all a bit self serving, you’re the one reading my writing — and I have some experience with who works out in the first ten!
First, we'll examine what they do well (and why they're beneficial for startups), then what they don't, and how to hire them.
First 10 are:
Business partners: Because it's their company, they take care of whatever has to be done and have ideas about how to do it. You can rely on them to always put the success of the firm first because it is their top priority (company success is strongly connected with success for early workers). This approach will eventually take someone to leadership positions.
High Speed Learners: They process knowledge quickly and can reach 80%+ competency in a new subject matter rather quickly. A growing business that is successful tries new things frequently. We have all lost a lot of money and time on employees who follow the wrong playbook or who wait for someone else within the company to take care of them.
Autodidacts learn by trial and error, osmosis, networking with others, applying first principles, and reading voraciously (articles, newsletters, books, and even social media). Although teaching is wonderful, you won't have time.
Self-scaling: They figure out a means to deal with issues and avoid doing the grunt labor over the long haul, increasing their leverage. Great people don't keep doing the same thing forever; as they expand, they use automation and delegation to fill in their lower branches. This is a crucial one; even though you'll still adore them, you'll have to manage their scope or help them learn how to scale on their own.
Free Range: You can direct them toward objectives rather than specific chores. Check-ins can be used to keep them generally on course without stifling invention instead of giving them precise instructions because doing so will obscure their light.
When people are inspired, they bring their own ideas about what a firm can be and become animated during discussions about how to get there.
Novelty Seeking: They look for business and personal growth chances. Give them fresh assignments and new directions to follow around once every three months.
Here’s what the First Ten types may not be:
Domain specialists. When you look at their resumes, you'll almost certainly think they're unqualified. Fortunately, a few strategically positioned experts may empower a number of First Ten types by serving on a leadership team or in advising capacities.
Balanced. These people become very invested, and they may be vulnerable to many types of stress. You may need to assist them in managing their own stress and coaching them through obstacles. If you are reading this and work at Banza, I apologize for not doing a better job of supporting this. I need to be better at it.
Able to handle micromanagement with ease. People who like to be in charge will suppress these people. Good decision-making should be delegated to competent individuals. Generally speaking, if you wish to scale.
Great startup team members have versatility, learning, innovation, and energy. When we hire for the function, not the person, we become dull and staid. Could this person go to another department if needed? Could they expand two levels in a few years?
First Ten qualities and experience level may have a weak inverse association. People with 20+ years of experience who had worked at larger organizations wanted to try something new and had a growth mentality. College graduates may want to be told what to do and how to accomplish it so they can stay in their lane and do what their management asks.
Does the First Ten archetype sound right for your org? Cool, let’s go hiring. How will you know when you’ve found one?
They exhibit adaptive excellence, excelling at a variety of unrelated tasks. It could be hobbies or professional talents. This suggests that they will succeed in the next several endeavors they pursue.
Successful risk-taking is doing something that wasn't certain to succeed, sometimes more than once, and making it do so. It's an attitude.
Rapid Rise: They regularly change roles and get promoted. However, they don't leave companies when the going gets tough. Look for promotions at every stop and at least one position with three or more years of experience.
You can ask them:
Tell me about a time when you started from scratch or achieved success. What occurred en route? You might request a variety of tales from various occupations or even aspects of life. They ought to be energized by this.
What new skills have you just acquired? It is not required to be work-related. They must be able to describe it and unintentionally become enthusiastic about it.
Tell me about a moment when you encountered a challenge and had to alter your strategy. The core of a startup is reinventing itself when faced with obstacles.
Tell me about a moment when you eliminated yourself from a position at work. They've demonstrated they can permanently solve one issue and develop into a new one, as stated above.
Why do you want to leave X position or Y duty? These people ought to be moving forward, not backward, all the time. Instead, they will discuss what they are looking forward to visiting your location.
Any questions? Due to their inherent curiosity and desire to learn new things, they should practically never run out of questions. You can really tell if they are sufficiently curious at this point.
People who see their success as being the same as the success of the organization are the best-case team members, in any market. They’ll grow and change with the company, and always try to prioritize what matters. You’ll find yourself more energized by your work because you’re surrounded by others who are as well. Happy teambuilding!