



More on Web3 & Crypto

Modern Eremite
3 years ago
The complete, easy-to-understand guide to bitcoin

Introduction
Markets rely on knowledge.
The internet provided practically endless knowledge and wisdom. Humanity has never seen such leverage. Technology's progress drives us to adapt to a changing world, changing our routines and behaviors.
In a digital age, people may struggle to live in the analogue world of their upbringing. Can those who can't adapt change their lives? I won't answer. We should teach those who are willing to learn, nevertheless. Unravel the modern world's riddles and give them wisdom.
Adapt or die . Accept the future or remain behind.
This essay will help you comprehend Bitcoin better than most market participants and the general public. Let's dig into Bitcoin.
Join me.

Ascension
Bitcoin.org was registered in August 2008. Bitcoin whitepaper was published on 31 October 2008. The document intrigued and motivated people around the world, including technical engineers and sovereignty seekers. Since then, Bitcoin's whitepaper has been read and researched to comprehend its essential concept.
I recommend reading the whitepaper yourself. You'll be able to say you read the Bitcoin whitepaper instead of simply Googling "what is Bitcoin" and reading the fundamental definition without knowing the revolution's scope. The article links to Bitcoin's whitepaper. To avoid being overwhelmed by the whitepaper, read the following article first.
Bitcoin isn't the first peer-to-peer digital currency. Hashcash or Bit Gold were once popular cryptocurrencies. These two Bitcoin precursors failed to gain traction and produce the network effect needed for general adoption. After many struggles, Bitcoin emerged as the most successful cryptocurrency, leading the way for others.
Satoshi Nakamoto, an active bitcointalk.org user, created Bitcoin. Satoshi's identity remains unknown. Satoshi's last bitcointalk.org login was 12 December 2010. Since then, he's officially disappeared. Thus, conspiracies and riddles surround Bitcoin's creators. I've heard many various theories, some insane and others well-thought-out.
It's not about who created it; it's about knowing its potential. Since its start, Satoshi's legacy has changed the world and will continue to.
Block-by-block blockchain
Bitcoin is a distributed ledger. What's the meaning?
Everyone can view all blockchain transactions, but no one can undo or delete them.
Imagine you and your friends routinely eat out, but only one pays. You're careful with money and what others owe you. How can everyone access the info without it being changed?

You'll keep a notebook of your evening's transactions. Everyone will take a page home. If one of you changed the page's data, the group would notice and reject it. The majority will establish consensus and offer official facts.
Miners add a new Bitcoin block to the main blockchain every 10 minutes. The appended block contains miner-verified transactions. Now that the next block has been added, the network will receive the next set of user transactions.
Bitcoin Proof of Work—prove you earned it
Any firm needs hardworking personnel to expand and serve clients. Bitcoin isn't that different.
Bitcoin's Proof of Work consensus system needs individuals to validate and create new blocks and check for malicious actors. I'll discuss Bitcoin's blockchain consensus method.
Proof of Work helps Bitcoin reach network consensus. The network is checked and safeguarded by CPU, GPU, or ASIC Bitcoin-mining machines (Application-Specific Integrated Circuit).
Every 10 minutes, miners are rewarded in Bitcoin for securing and verifying the network. It's unlikely you'll finish the block. Miners build pools to increase their chances of winning by combining their processing power.
In the early days of Bitcoin, individual mining systems were more popular due to high maintenance costs and larger earnings prospects. Over time, people created larger and larger Bitcoin mining facilities that required a lot of space and sophisticated cooling systems to keep machines from overheating.
Proof of Work is a vital part of the Bitcoin network, as network security requires the processing power of devices purchased with fiat currency. Miners must invest in mining facilities, which creates a new business branch, mining facilities ownership. Bitcoin mining is a topic for a future article.
More mining, less reward
Bitcoin is usually scarce.
Why is it rare? It all comes down to 21,000,000 Bitcoins.
Were all Bitcoins mined? Nope. Bitcoin's supply grows until it hits 21 million coins. Initially, 50BTC each block was mined, and each block took 10 minutes. Around 2140, the last Bitcoin will be mined.
But 50BTC every 10 minutes does not give me the year 2140. Indeed careful reader. So important is Bitcoin's halving process.
What is halving?
The block reward is halved every 210,000 blocks, which takes around 4 years. The initial payout was 50BTC per block and has been decreased to 25BTC after 210,000 blocks. First halving occurred on November 28, 2012, when 10,500,000 BTC (50%) had been mined. As of April 2022, the block reward is 6.25BTC and will be lowered to 3.125BTC by 19 March 2024.
The halving method is tied to Bitcoin's hashrate. Here's what "hashrate" means.
What if we increased the number of miners and hashrate they provide to produce a block every 10 minutes? Wouldn't we manufacture blocks faster?

Every 10 minutes, blocks are generated with little asymmetry. Due to the built-in adaptive difficulty algorithm, the overall hashrate does not affect block production time. With increased hashrate, it's harder to construct a block. We can estimate when the next halving will occur because 10 minutes per block is fixed.
Building with nodes and blocks
For someone new to crypto, the unusual terms and words may be overwhelming. You'll also find everyday words that are easy to guess or have a vague idea of what they mean, how they work, and what they do. Consider blockchain technology.
Nodes and blocks: Think about that for a moment. What is your first idea?
The blockchain is a chain of validated blocks added to the main chain. What's a "block"? What's inside?
The block is another page in the blockchain book that has been filled with transaction information and accepted by the majority.
We won't go into detail about what each block includes and how it's built, as long as you understand its purpose.
What about nodes?
Nodes, along with miners, verify the blockchain's state independently. But why?
To create a full blockchain node, you must download the whole Bitcoin blockchain and check every transaction against Bitcoin's consensus criteria.
What's Bitcoin's size?
In April 2022, the Bitcoin blockchain was 389.72GB.
Bitcoin's blockchain has miners and node runners.
Let's revisit the US gold rush. Miners mine gold with their own power (physical and monetary resources) and are rewarded with gold (Bitcoin). All become richer with more gold, and so does the country.
Nodes are like sheriffs, ensuring everything is done according to consensus rules and that there are no rogue miners or network users.
Lost and held bitcoin
Does the Bitcoin exchange price match each coin's price? How many coins remain after 21,000,000? 21 million or less?
Common reason suggests a 21 million-coin supply.
What if I lost 1BTC from a cold wallet?
What if I saved 1000BTC on paper in 2010 and it was damaged?
What if I mined Bitcoin in 2010 and lost the keys?
Satoshi Nakamoto's coins? Since then, those coins haven't moved.
How many BTC are truly in circulation?
Many people are trying to answer this question, and you may discover a variety of studies and individual research on the topic. Be cautious of the findings because they can't be evaluated and the statistics are hazy guesses.
On the other hand, we have long-term investors who won't sell their Bitcoin or will sell little amounts to cover mining or living needs.
The price of Bitcoin is determined by supply and demand on exchanges using liquid BTC. How many BTC are left after subtracting lost and non-custodial BTC?
We have significantly less Bitcoin in circulation than you think, thus the price may not reflect demand if we knew the exact quantity of coins available.
True HODLers and diamond-hand investors won't sell you their coins, no matter the market.
What's UTXO?
Unspent (U) Transaction (TX) Output (O)

Imagine taking a $100 bill to a store. After choosing a drink and munchies, you walk to the checkout to pay. The cashier takes your $100 bill and gives you $25.50 in change. It's in your wallet.
Is it simply 100$? No way.
The $25.50 in your wallet is unrelated to the $100 bill you used. Your wallet's $25.50 is just bills and coins. Your wallet may contain these coins and bills:
2x 10$ 1x 10$
1x 5$ or 3x 5$
1x 0.50$ 2x 0.25$
Any combination of coins and bills can equal $25.50. You don't care, and I'd wager you've never ever considered it.
That is UTXO. Now, I'll detail the Bitcoin blockchain and how UTXO works, as it's crucial to know what coins you have in your (hopefully) cold wallet.
You purchased 1BTC. Is it all? No. UTXOs equal 1BTC. Then send BTC to a cold wallet. Say you pay 0.001BTC and send 0.999BTC to your cold wallet. Is it the 1BTC you got before? Well, yes and no. The UTXOs are the same or comparable as before, but the blockchain address has changed. It's like if you handed someone a wallet, they removed the coins needed for a network charge, then returned the rest of the coins and notes.
UTXO is a simple concept, but it's crucial to grasp how it works to comprehend dangers like dust attacks and how coins may be tracked.
Lightning Network: fast cash
You've probably heard of "Layer 2 blockchain" projects.
What does it mean?
Layer 2 on a blockchain is an additional layer that increases the speed and quantity of transactions per minute and reduces transaction fees.
Imagine going to an obsolete bank to transfer money to another account and having to pay a charge and wait. You can transfer funds via your bank account or a mobile app without paying a fee, or the fee is low, and the cash appear nearly quickly. Layer 1 and 2 payment systems are different.
Layer 1 is not obsolete; it merely has more essential things to focus on, including providing the blockchain with new, validated blocks, whereas Layer 2 solutions strive to offer Layer 1 with previously processed and verified transactions. The primary blockchain, Bitcoin, will only receive the wallets' final state. All channel transactions until shutting and balancing are irrelevant to the main chain.
Layer 2 and the Lightning Network's goal are now clear. Most Layer 2 solutions on multiple blockchains are created as blockchains, however Lightning Network is not. Remember the following remark, as it best describes Lightning.

Lightning Network connects public and private Bitcoin wallets.
Opening a private channel with another wallet notifies just two parties. The creation and opening of a public channel tells the network that anyone can use it.
Why create a public Lightning Network channel?
Every transaction through your channel generates fees.
Money, if you don't know.
See who benefits when in doubt.
Anonymity, huh?
Bitcoin anonymity? Bitcoin's anonymity was utilized to launder money.
Well… You've heard similar stories. When you ask why or how it permits people to remain anonymous, the conversation ends as if it were just a story someone heard.
Bitcoin isn't private. Pseudonymous.
What if someone tracks your transactions and discovers your wallet address? Where is your anonymity then?

Bitcoin is like bulletproof glass storage; you can't take or change the money. If you dig and analyze the data, you can see what's inside.
Every online action leaves a trace, and traces may be tracked. People often forget this guideline.
A tool like that can help you observe what the major players, or whales, are doing with their coins when the market is uncertain. Many people spend time analyzing on-chain data. Worth it?
Ask yourself a question. What are the big players' options? Do you think they're letting you see their wallets for a small on-chain data fee?
Instead of short-term behaviors, focus on long-term trends.
More wallet transactions leave traces. Having nothing to conceal isn't a defect. Can it lead to regulating Bitcoin so every transaction is tracked like in banks today?
But wait. How can criminals pay out Bitcoin? They're doing it, aren't they?
Mixers can anonymize your coins, letting you to utilize them freely. This is not a guide on how to make your coins anonymous; it could do more harm than good if you don't know what you're doing.
Remember, being anonymous attracts greater attention.
Bitcoin isn't the only cryptocurrency we can use to buy things. Using cryptocurrency appropriately can provide usability and anonymity. Monero (XMR), Zcash (ZEC), and Litecoin (LTC) following the Mimblewimble upgrade are examples.
Summary
Congratulations! You've reached the conclusion of the article and learned about Bitcoin and cryptocurrency. You've entered the future.
You know what Bitcoin is, how its blockchain works, and why it's not anonymous. I bet you can explain Lightning Network and UTXO to your buddies.
Markets rely on knowledge. Prepare yourself for success before taking the first step. Let your expertise be your edge.
This article is a summary of this one.

The Verge
4 years ago
Bored Ape Yacht Club creator raises $450 million at a $4 billion valuation.
Yuga Labs, owner of three of the biggest NFT brands on the market, announced today a $450 million funding round. The money will be used to create a media empire based on NFTs, starting with games and a metaverse project.
The team's Otherside metaverse project is an MMORPG meant to connect the larger NFT universe. They want to create “an interoperable world” that is “gamified” and “completely decentralized,” says Wylie Aronow, aka Gordon Goner, co-founder of Bored Ape Yacht Club. “We think the real Ready Player One experience will be player run.”
Just a few weeks ago, Yuga Labs announced the acquisition of CryptoPunks and Meebits from Larva Labs. The deal brought together three of the most valuable NFT collections, giving Yuga Labs more IP to work with when developing games and metaverses. Last week, ApeCoin was launched as a cryptocurrency that will be governed independently and used in Yuga Labs properties.
Otherside will be developed by “a few different game studios,” says Yuga Labs CEO Nicole Muniz. The company plans to create development tools that allow NFTs from other projects to work inside their world. “We're welcoming everyone into a walled garden.”
However, Yuga Labs believes that other companies are approaching metaverse projects incorrectly, allowing the startup to stand out. People won't bond spending time in a virtual space with nothing going on, says Yuga Labs co-founder Greg Solano, aka Gargamel. Instead, he says, people bond when forced to work together.
In order to avoid getting smacked, Solano advises making friends. “We don't think a Zoom chat and walking around saying ‘hi' creates a deep social experience.” Yuga Labs refused to provide a release date for Otherside. Later this year, a play-to-win game is planned.
The funding round was led by Andreessen Horowitz, a major investor in the Web3 space. It previously backed OpenSea and Coinbase. Animoca Brands, Coinbase, and MoonPay are among those who have invested. Andreessen Horowitz general partner Chris Lyons will join Yuga Labs' board. The Financial Times broke the story last month.
"META IS A DOMINANT DIGITAL EXPERIENCE PROVIDER IN A DYSTOPIAN FUTURE."
This emerging [Web3] ecosystem is important to me, as it is to companies like Meta,” Chris Dixon, head of Andreessen Horowitz's crypto arm, tells The Verge. “In a dystopian future, Meta is the dominant digital experience provider, and it controls all the money and power.” (Andreessen Horowitz co-founder Marc Andreessen sits on Meta's board and invested early in Facebook.)
Yuga Labs has been profitable so far. According to a leaked pitch deck, the company made $137 million last year, primarily from its NFT brands, with a 95% profit margin. (Yuga Labs declined to comment on deck figures.)
But the company has built little so far. According to OpenSea data, it has only released one game for a limited time. That means Yuga Labs gets hundreds of millions of dollars to build a gaming company from scratch, based on a hugely lucrative art project.
Investors fund Yuga Labs based on its success. That's what they did, says Dixon, “they created a culture phenomenon”. But ultimately, the company is betting on the same thing that so many others are: that a metaverse project will be the next big thing. Now they must construct it.

Onchain Wizard
3 years ago
Three Arrows Capital & Celsius Updates
I read 1k+ page 3AC liquidation documentation so you don't have to. Also sharing revised Celsius recovery plans.
3AC's liquidation documents:
Someone disclosed 3AC liquidation records in the BVI courts recently. I'll discuss the leak's timeline and other highlights.
Three Arrows Capital began trading traditional currencies in emerging markets in 2012. They switched to equities and crypto, then purely crypto in 2018.
By 2020, the firm had $703mm in net assets and $1.8bn in loans (these guys really like debt).

The firm's net assets under control reached $3bn in April 2022, according to the filings. 3AC had $600mm of LUNA/UST exposure before May 9th 2022, which put them over.

LUNA and UST go to zero quickly (I wrote about the mechanics of the blowup here). Kyle Davies, 3AC co-founder, told Blockchain.com on May 13 that they have $2.4bn in assets and $2.3bn NAV vs. $2bn in borrowings. As BTC and ETH plunged 33% and 50%, the company became insolvent by mid-2022.

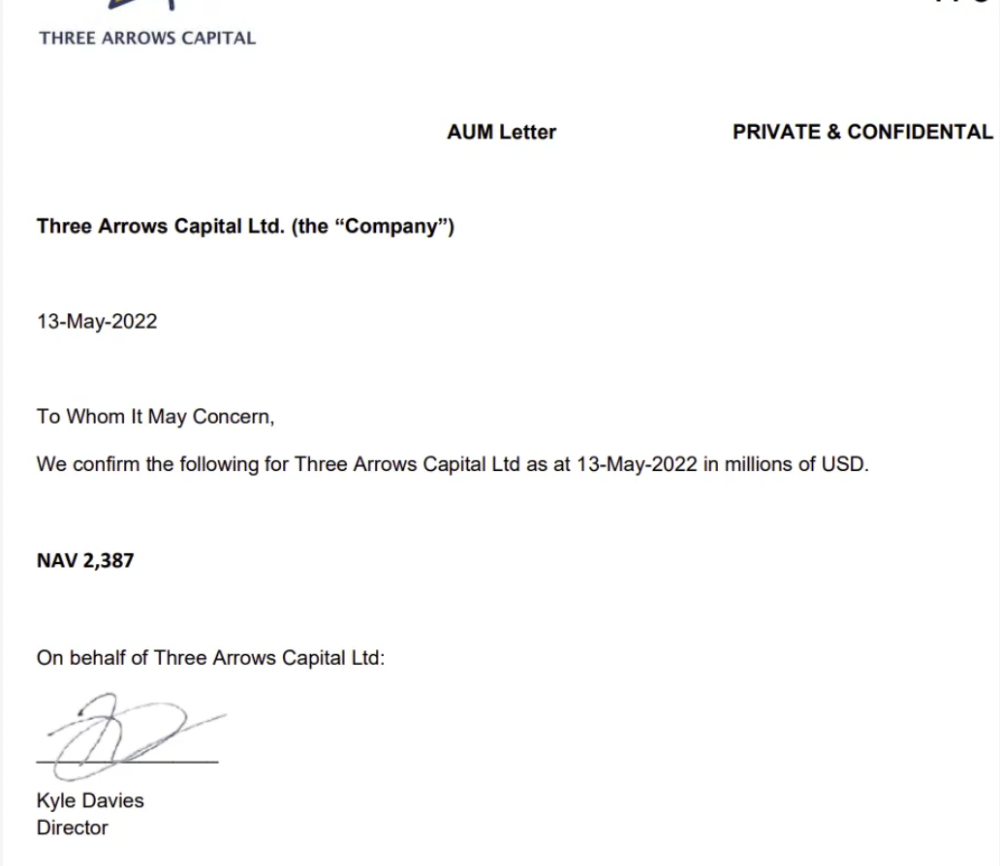
3AC sent $32mm to Tai Ping Shen, a Cayman Islands business owned by Su Zhu and Davies' partner, Kelly Kaili Chen (who knows what is going on here).
3AC had borrowed over $3.5bn in notional principle, with Genesis ($2.4bn) and Voyager ($650mm) having the most exposure.
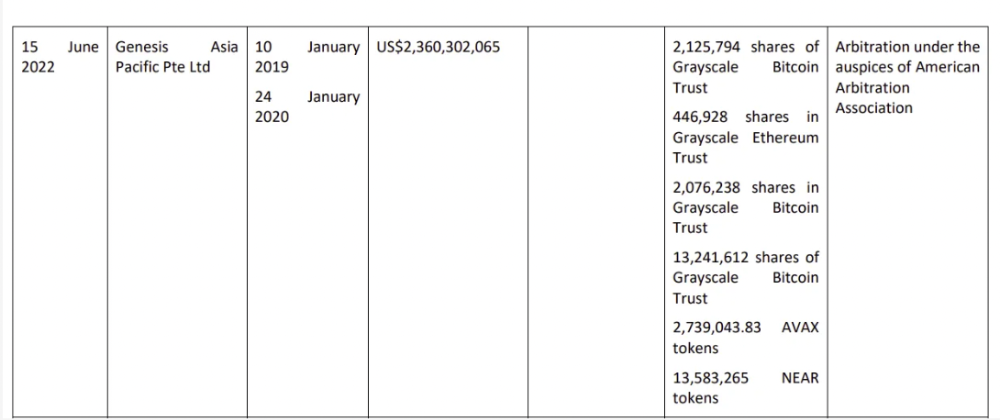
Genesis demanded $355mm in further collateral in June.
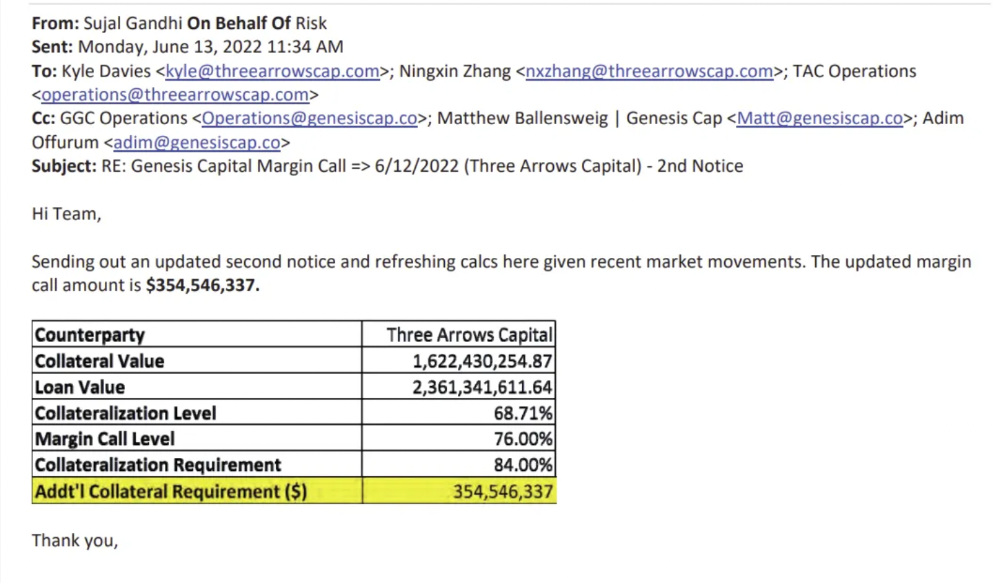
Deribit (another 3AC investment) called for $80 million in mid-June.
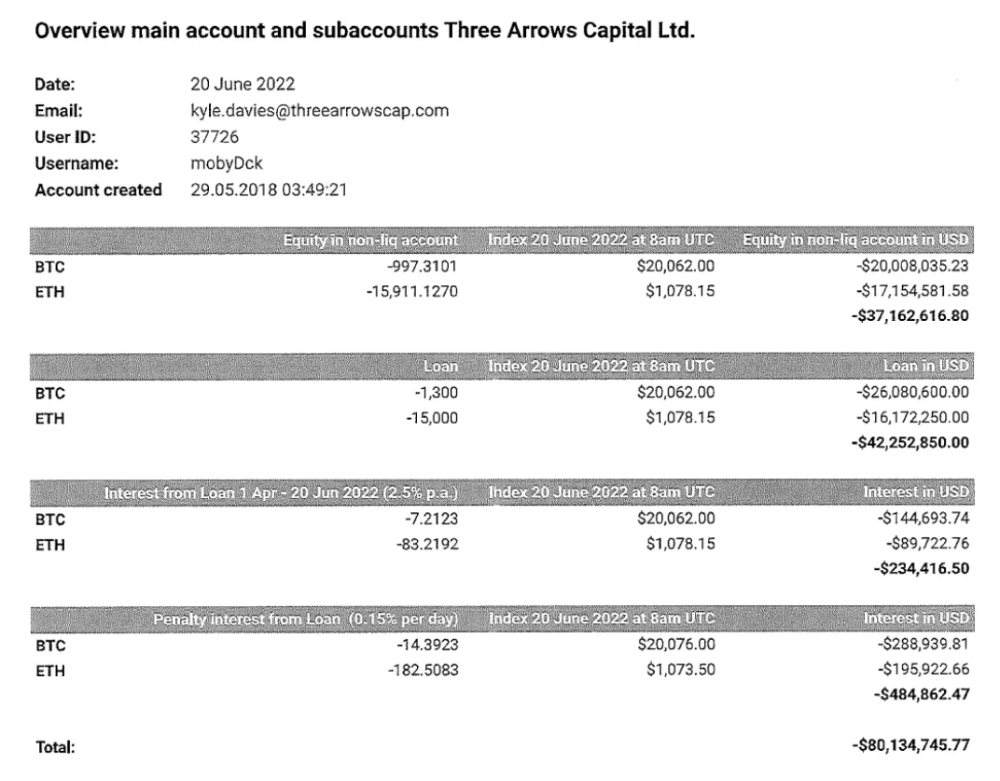
Even in mid-June, the corporation was trying to borrow more money to stay afloat. They approached Genesis for another $125mm loan (to pay another lender) and HODLnauts for BTC & ETH loans.
Pretty crazy. 3AC founders used borrowed money to buy a $50 million boat, according to the leak.

Su requesting for $5m + Chen Kaili Kelly asserting they loaned $65m unsecured to 3AC are identified as creditors.


Celsius:
This bankruptcy presentation shows the Celsius breakdown from March to July 14, 2022. From $22bn to $4bn, crypto assets plummeted from $14.6bn to $1.8bn (ouch). $16.5bn in user liabilities dropped to $4.72bn.
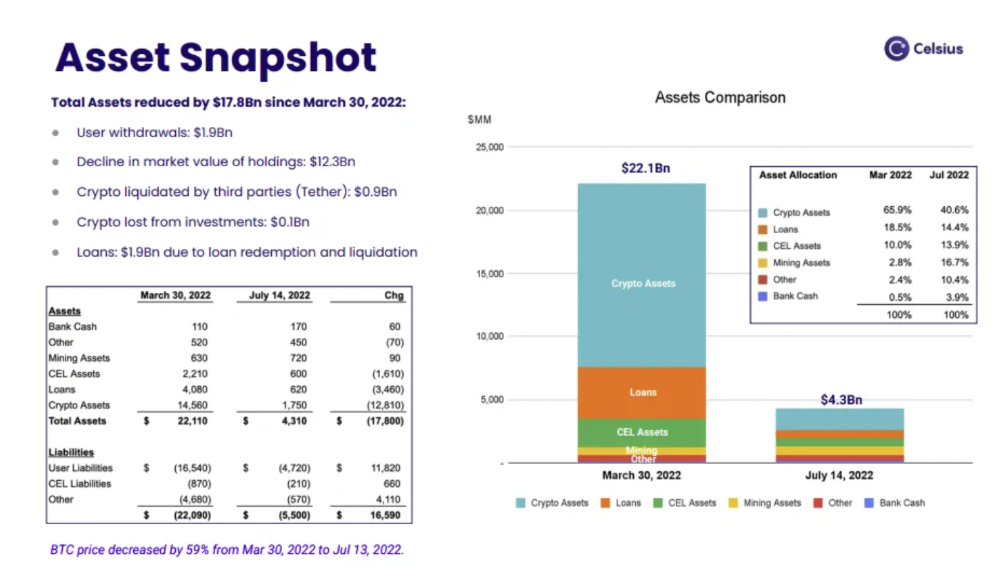
In my recent post, I examined if "forced selling" is over, with Celsius' crypto assets being a major overhang. In this presentation, it looks that Chapter 11 will provide clients the opportunity to accept cash at a discount or remain long crypto. Provided that a fresh source of money is unlikely to enter the Celsius situation, cash at a discount or crypto given to customers will likely remain a near-term market risk - cash at a discount will likely come from selling crypto assets, while customers who receive crypto could sell at any time. I'll share any Celsius updates I find.
Conclusion
Only Celsius and the Mt Gox BTC unlock remain as forced selling catalysts. While everything went through a "relief" pump, with ETH up 75% from the bottom and numerous alts multiples higher, there are still macro dangers to equities + risk assets. There's a lot of wealth waiting to be deployed in crypto ($153bn in stables), but fund managers are risk apprehensive (lower than 2008 levels).
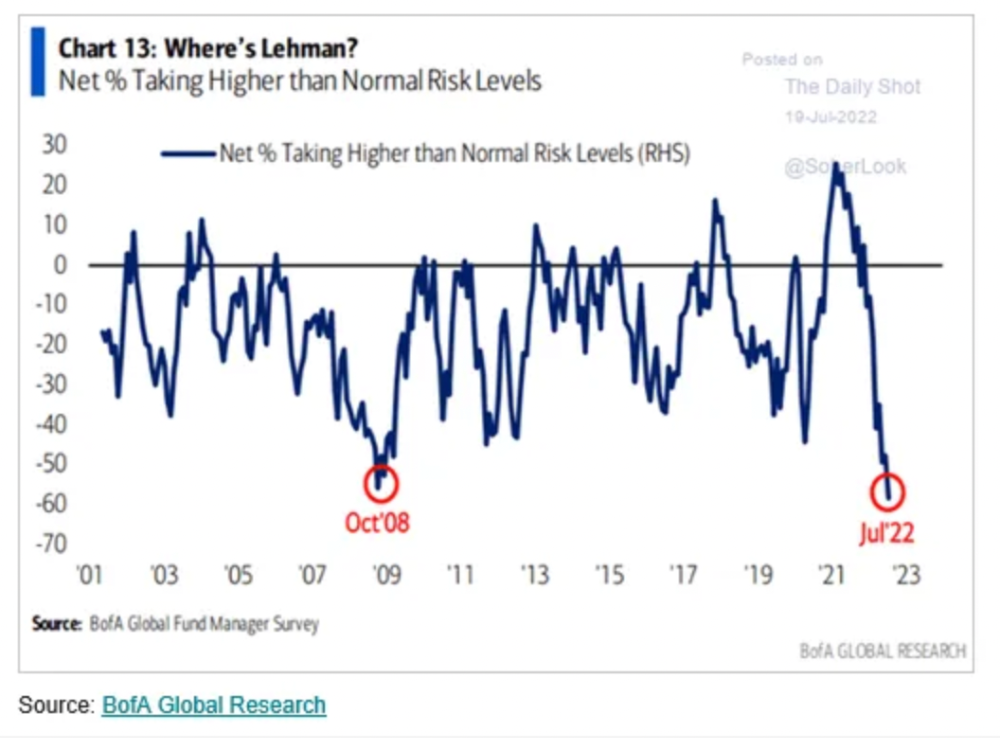
We're hopefully over crypto's "bottom," with peak anxiety and forced selling behind us, but we may chop around.
To see the full article, click here.
You might also like

Chris Moyse
4 years ago
Sony and LEGO raise $2 billion for Epic Games' metaverse
‘Kid-friendly’ project holds $32 billion valuation
Epic Games announced today that it has raised $2 billion USD from Sony Group Corporation and KIRKBI (holding company of The LEGO Group). Both companies contributed $1 billion to Epic Games' upcoming ‘metaverse' project.
“We need partners who share our vision as we reimagine entertainment and play. Our partnership with Sony and KIRKBI has found this,” said Epic Games CEO Tim Sweeney. A new metaverse will be built where players can have fun with friends and brands create creative and immersive experiences, as well as creators thrive.
Last week, LEGO and Epic Games announced their plans to create a family-friendly metaverse where kids can play, interact, and create in digital environments. The service's users' safety and security will be prioritized.
With this new round of funding, Epic Games' project is now valued at $32 billion.
“Epic Games is known for empowering creators large and small,” said KIRKBI CEO Sren Thorup Srensen. “We invest in trends that we believe will impact the world we and our children will live in. We are pleased to invest in Epic Games to support their continued growth journey, with a long-term focus on the future metaverse.”
Epic Games is expected to unveil its metaverse plans later this year, including its name, details, services, and release date.

Ossiana Tepfenhart
3 years ago
Has anyone noticed what an absolute shitshow LinkedIn is?
After viewing its insanity, I had to leave this platform.

I joined LinkedIn recently. That's how I aim to increase my readership and gain recognition. LinkedIn's premise appealed to me: a Facebook-like platform for professional networking.
I don't use Facebook since it's full of propaganda. It seems like a professional, apolitical space, right?
I expected people to:
be more formal and respectful than on Facebook.
Talk about the inclusiveness of the workplace. Studies consistently demonstrate that inclusive, progressive workplaces outperform those that adhere to established practices.
Talk about business in their industry. Yep. I wanted to read articles with advice on how to write better and reach a wider audience.
Oh, sh*t. I hadn't anticipated that.

After posting and reading about inclusivity and pro-choice, I was startled by how many professionals acted unprofessionally. I've seen:
Men have approached me in the DMs in a really aggressive manner. Yikes. huge yikes Not at all professional.
I've heard pro-choice women referred to as infant killers by many people. If I were the CEO of a company and I witnessed one of my employees acting that poorly, I would immediately fire them.
Many posts are anti-LGBTQIA+, as I've noticed. a lot, like, a lot. Some are subtly stating that the world doesn't need to know, while others are openly making fun of transgender persons like myself.
Several medical professionals were posting explicitly racist comments. Even if you are as white as a sheet like me, you should be alarmed by this. Who's to guarantee a patient who is black won't unintentionally die?
I won't even get into how many men in STEM I observed pushing for the exclusion of women from their fields. I shouldn't be surprised considering the majority of those men I've encountered have a passionate dislike for women, but goddamn, dude.
Many people appear entirely too at ease displaying their bigotry on their professional profiles.

As a white female, I'm always shocked by people's open hostility. Professional environments are very important.
I don't know if this is still true (people seem too politicized to care), but if I heard many of these statements in person, I'd suppose they feel ashamed. Really.
Are you not ashamed of being so mean? Are you so weak that competing with others terrifies you? Isn't this embarrassing?
LinkedIn isn't great at censoring offensive comments. These people aren't getting warnings. So they were safe while others were unsafe.
The CEO in me would want to know if I had placed a bigot on my staff.

I always wondered if people's employers knew about their online behavior. If they know how horrible they appear, they don't care.
As a manager, I was picky about hiring. Obviously. In most industries, it costs $1,000 or more to hire a full-time employee, so be sure it pays off.
Companies that embrace diversity and tolerance (and are intolerant of intolerance) are more profitable, likely to recruit top personnel, and successful.
People avoid businesses that alienate them. That's why I don't eat at Chic-Fil-A and why folks avoid MyPillow. Being inclusive is good business.
CEOs are harmed by online bigots. Image is an issue. If you're a business owner, you can fire staff who don't help you.
On the one hand, I'm delighted it makes it simpler to identify those with whom not to do business.

Don’t get me wrong. I'm glad I know who to avoid when hiring, getting references, or searching for a job. When people are bad, it saves me time.
What's up with professionalism?
Really. I need to know. I've crossed the boundary between acceptable and unacceptable behavior, but never on a professional platform. I got in trouble for not wearing bras even though it's not part of my gender expression.
If I behaved like that at my last two office jobs, my supervisors would have fired me immediately. Some of the behavior I've seen is so outrageous, I can't believe these people have employment. Some are even leaders.
Like…how? Is hatred now normalized?
Please pay attention whether you're seeking for a job or even simply a side gig.

Do not add to the tragedy that LinkedIn comments can be, or at least don't make uninformed comments. Even if you weren't banned, the site may still bite you.
Recruiters can and do look at your activity. Your writing goes on your résumé. The wrong comment might lose you a job.
Recruiters and CEOs might reject candidates whose principles contradict with their corporate culture. Bigotry will get you banned from many companies, especially if others report you.
If you want a high-paying job, avoid being a LinkedIn asshole. People care even if you think no one does. Before speaking, ponder. Is this how you want to be perceived?
Better advice:
If your politics might turn off an employer, stop posting about them online and ask yourself why you hold such objectionable ideas.
Matthew Royse
3 years ago
Ten words and phrases to avoid in presentations
Don't say this in public!

Want to wow your audience? Want to deliver a successful presentation? Do you want practical takeaways from your presentation?
Then avoid these phrases.
Public speaking is difficult. People fear public speaking, according to research.
"Public speaking is people's biggest fear, according to studies. Number two is death. "Sounds right?" — Comedian Jerry Seinfeld
Yes, public speaking is scary. These words and phrases will make your presentation harder.
Using unnecessary words can weaken your message.
You may have prepared well for your presentation and feel confident. During your presentation, you may freeze up. You may blank or forget.
Effective delivery is even more important than skillful public speaking.
Here are 10 presentation pitfalls.
1. I or Me
Presentations are about the audience, not you. Replace "I or me" with "you, we, or us." Focus on your audience. Reward them with expertise and intriguing views about your issue.
Serve your audience actionable items during your presentation, and you'll do well. Your audience will have a harder time listening and engaging if you're self-centered.
2. Sorry if/for
Your presentation is fine. These phrases make you sound insecure and unprepared. Don't pressure the audience to tell you not to apologize. Your audience should focus on your presentation and essential messages.
3. Excuse the Eye Chart, or This slide's busy
Why add this slide if you're utilizing these phrases? If you don't like this slide, change it before presenting. After the presentation, extra data can be provided.
Don't apologize for unclear slides. Hide or delete a broken PowerPoint slide. If so, divide your message into multiple slides or remove the "business" slide.
4. Sorry I'm Nervous
Some think expressing yourself will win over the audience. Nerves are horrible. Even public speakers are nervous.
Nerves aren't noticeable. What's the point? Let the audience judge your nervousness. Please don't make this obvious.
5. I'm not a speaker or I've never done this before.
These phrases destroy credibility. People won't listen and will check their phones or computers.
Why present if you use these phrases?
Good speakers aren't necessarily public speakers. Be confident in what you say. When you're confident, many people will like your presentation.
6. Our Key Differentiators Are
Overused term. It's widely utilized. This seems "salesy," and your "important differentiators" are probably like a competitor's.
This statement has been diluted; say, "what makes us different is..."
7. Next Slide
Many slides or stories? Your presentation needs transitions. They help your viewers understand your argument.
You didn't transition well when you said "next slide." Think about organic transitions.
8. I Didn’t Have Enough Time, or I’m Running Out of Time
The phrase "I didn't have enough time" implies that you didn't care about your presentation. This shows the viewers you rushed and didn't care.
Saying "I'm out of time" shows poor time management. It means you didn't rehearse enough and plan your time well.
9. I've been asked to speak on
This phrase is used to emphasize your importance. This phrase conveys conceit.
When you say this sentence, you tell others you're intelligent, skilled, and appealing. Don't utilize this term; focus on your topic.
10. Moving On, or All I Have
These phrases don't consider your transitions or presentation's end. People recall a presentation's beginning and end.
How you end your discussion affects how people remember it. You must end your presentation strongly and use natural transitions.
Conclusion
10 phrases to avoid in a presentation. I or me, sorry if or sorry for, pardon the Eye Chart or this busy slide, forgive me if I appear worried, or I'm really nervous, and I'm not good at public speaking, I'm not a speaker, or I've never done this before.
Please don't use these phrases: next slide, I didn't have enough time, I've been asked to speak about, or that's all I have.
We shouldn't make public speaking more difficult than it is. We shouldn't exacerbate a difficult issue. Better public speakers avoid these words and phrases.
“Remember not only to say the right thing in the right place, but far more difficult still, to leave unsaid the wrong thing at the tempting moment.” — Benjamin Franklin, Founding Father
This is a summary. See the original post here.