

More on Marketing

M.G. Siegler
3 years ago
Apple: Showing Ads on Your iPhone
This report from Mark Gurman has stuck with me:
In the News and Stocks apps, the display ads are no different than what you might get on an ad-supported website. In the App Store, the ads are for actual apps, which are probably more useful for Apple users than mortgage rates. Some people may resent Apple putting ads in the News and Stocks apps. After all, the iPhone is supposed to be a premium device. Let’s say you shelled out $1,000 or more to buy one, do you want to feel like Apple is squeezing more money out of you just to use its standard features? Now, a portion of ad revenue from the News app’s Today tab goes to publishers, but it’s not clear how much. Apple also lets publishers advertise within their stories and keep the vast majority of that money. Surprisingly, Today ads also appear if you subscribe to News+ for $10 per month (though it’s a smaller number).
I use Apple News often. It's a good general news catch-up tool, like Twitter without the BS. Customized notifications are helpful. Fast and lovely. Except for advertisements. I have Apple One, which includes News+, and while I understand why the magazines still have brand ads, it's ridiculous to me that Apple enables web publishers to introduce awful ads into this experience. Apple's junky commercials are ridiculous.
We know publishers want and probably requested this. Let's keep Apple News ad-free for the much smaller percentage of paid users, and here's your portion. (Same with Stocks, which is more sillier.)
Paid app placement in the App Store is a wonderful approach for developers to find new users (though far too many of those ads are trying to trick users, in my opinion).
Apple is also planning to increase ads in its Maps app. This sounds like Google Maps, and I don't like it. I never find these relevant, and they clutter up the user experience. Apple Maps now has a UI advantage (though not a data/search one, which matters more).
Apple is nickel-and-diming its customers. We spend thousands for their products and premium services like Apple One. We all know why: income must rise, and new firms are needed to scale. This will eventually backfire.

Jenn Leach
3 years ago
This clever Instagram marketing technique increased my sales to $30,000 per month.
No Paid Ads Required

I had an online store. After a year of running the company alongside my 9-to-5, I made enough to resign.
That day was amazing.
This Instagram marketing plan helped the store succeed.
How did I increase my sales to five figures a month without using any paid advertising?
I used customer event marketing.
I'm not sure this term exists. I invented it to describe what I was doing.
Instagram word-of-mouth, fan engagement, and interaction drove sales.
If a customer liked or disliked a product, the buzz would drive attention to the store.
I used customer-based events to increase engagement and store sales.
Success!
Here are the weekly Instagram customer events I coordinated while running my business:
Be the Buyer Days
Flash sales
Mystery boxes
Be the Buyer Days: How do they work?
Be the Buyer Days are exactly that.
You choose a day to share stock selections with social media followers.
This is an easy approach to engaging customers and getting fans enthusiastic about new releases.
First, pick a handful of items you’re considering ordering. I’d usually pick around 3 for Be the Buyer Day.
Then I'd poll the crowd on Instagram to vote on their favorites.
This was before Instagram stories, polls, and all the other cool features Instagram offers today. I think using these tools now would make this event even better.
I'd ask customers their favorite back then.
The growing comments excited customers.
Then I'd declare the winner, acquire the products, and start selling it.
How do flash sales work?
I mostly ran flash sales.
You choose a limited number of itemsdd for a few-hour sale.
We wanted most sales to result in sold-out items.
When an item sells out, it contributes to the sensation of scarcity and can inspire customers to visit your store to buy a comparable product, join your email list, become a fan, etc.
We hoped they'd act quickly.
I'd hold flash deals twice a week, which generated scarcity and boosted sales.
The store had a few thousand Instagram followers when I started flash deals.
Each flash sale item would make $400 to $600.
$400 x 3= $1,200
That's $1,200 on social media!
Twice a week, you'll make roughly $10K a month from Instagram.
$1,200/day x 8 events/month=$9,600
Flash sales did great.
We held weekly flash deals and sent social media and email reminders. That’s about it!
How are mystery boxes put together?
All you do is package a box of store products and sell it as a mystery box on TikTok or retail websites.
A $100 mystery box would cost $30.
You're discounting high-value boxes.
This is a clever approach to get rid of excess inventory and makes customers happy.
It worked!
Be the Buyer Days, flash deals, and mystery boxes helped build my company without paid advertisements.
All companies can use customer event marketing. Involving customers and providing an engaging environment can boost sales.
Try it!

Dung Claire Tran
3 years ago
Is the future of brand marketing with virtual influencers?
Digital influences that mimic humans are rising.
Lil Miquela has 3M Instagram followers, 3.6M TikTok followers, and 30K Twitter followers. She's been on the covers of Prada, Dior, and Calvin Klein magazines. Miquela released Not Mine in 2017 and launched Hard Feelings at Lollapazoolas this year. This isn't surprising, given the rise of influencer marketing.
This may be unexpected. Miquela's fake. Brud, a Los Angeles startup, produced her in 2016.
Lil Miquela is one of many rising virtual influencers in the new era of social media marketing. She acts like a real person and performs the same tasks as sports stars and models.
The emergence of online influencers
Before 2018, computer-generated characters were rare. Since the virtual human industry boomed, they've appeared in marketing efforts worldwide.
In 2020, the WHO partnered up with Atlanta-based virtual influencer Knox Frost (@knoxfrost) to gather contributions for the COVID-19 Solidarity Response Fund.
Lu do Magalu (@magazineluiza) has been the virtual spokeswoman for Magalu since 2009, using social media to promote reviews, product recommendations, unboxing videos, and brand updates. Magalu's 10-year profit was $552M.
In 2020, PUMA partnered with Southeast Asia's first virtual model, Maya (@mayaaa.gram). She joined Singaporean actor Tosh Zhang in the PUMA campaign. Local virtual influencer Ava Lee-Graham (@avagram.ai) partnered with retail firm BHG to promote their in-house labels.

In Japan, Imma (@imma.gram) is the face of Nike, PUMA, Dior, Salvatore Ferragamo SpA, and Valentino. Imma's bubblegum pink bob and ultra-fine fashion landed her on the cover of Grazia magazine.

Lotte Home Shopping created Lucy (@here.me.lucy) in September 2020. She made her TV debut as a Christmas show host in 2021. Since then, she has 100K Instagram followers and 13K TikTok followers.
Liu Yiexi gained 3 million fans in five days on Douyin, China's TikTok, in 2021. Her two-minute video went viral overnight. She's posted 6 videos and has 830 million Douyin followers.
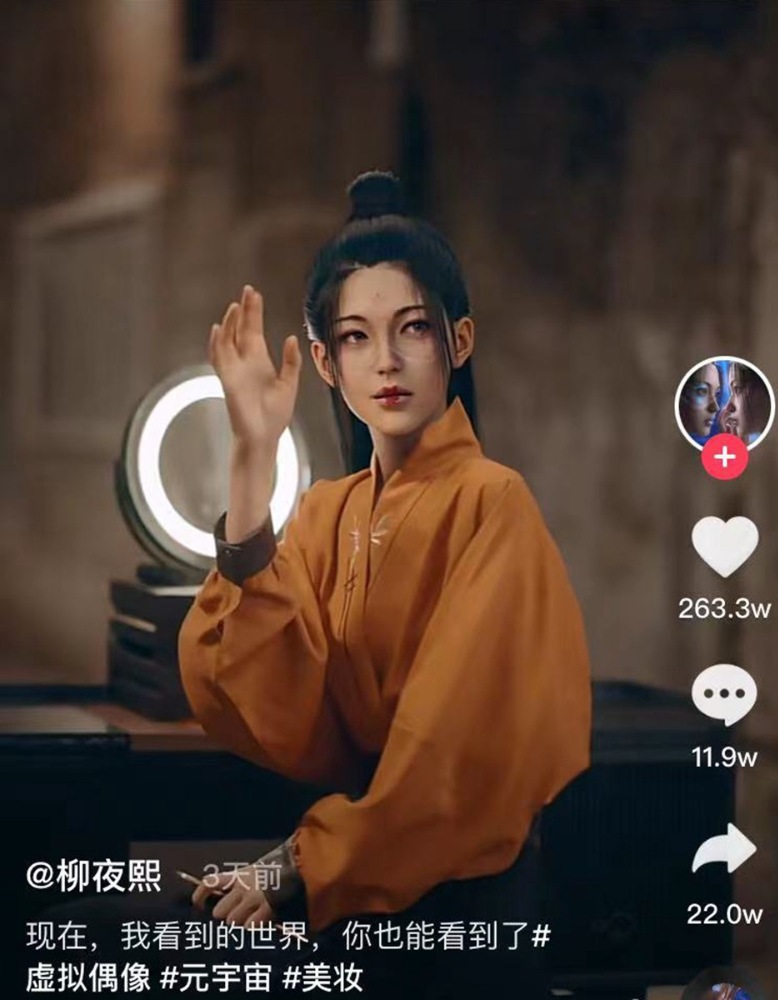
China's virtual human industry was worth $487 million in 2020, up 70% year over year, and is expected to reach $875.9 million in 2021.
Investors worldwide are interested. Immas creator Aww Inc. raised $1 million from Coral Capital in September 2020, according to Bloomberg. Superplastic Inc., the Vermont-based startup behind influencers Janky and Guggimon, raised $16 million by 2020. Craft Ventures, SV Angels, and Scooter Braun invested. Crunchbase shows the company has raised $47 million.
The industries they represent, including Augmented and Virtual reality, were worth $14.84 billion in 2020 and are projected to reach $454.73 billion by 2030, a CAGR of 40.7%, according to PR Newswire.
Advantages for brands
Forbes suggests brands embrace computer-generated influencers. Examples:
Unlimited creative opportunities: Because brands can personalize everything—from a person's look and activities to the style of their content—virtual influencers may be suited to a brand's needs and personalities.
100% brand control: Brand managers now have more influence over virtual influencers, so they no longer have to give up and rely on content creators to include brands into their storytelling and style. Virtual influencers can constantly produce social media content to promote a brand's identity and ideals because they are completely scandal-free.
Long-term cost savings: Because virtual influencers are made of pixels, they may be reused endlessly and never lose their beauty. Additionally, they can move anywhere around the world and even into space to fit a brand notion. They are also always available. Additionally, the expense of creating their content will not rise in step with their expanding fan base.
Introduction to the metaverse: Statista reports that 75% of American consumers between the ages of 18 and 25 follow at least one virtual influencer. As a result, marketers that support virtual celebrities may now interact with younger audiences that are more tech-savvy and accustomed to the digital world. Virtual influencers can be included into any digital space, including the metaverse, as they are entirely computer-generated 3D personas. Virtual influencers can provide brands with a smooth transition into this new digital universe to increase brand trust and develop emotional ties, in addition to the young generations' rapid adoption of the metaverse.
Better engagement than in-person influencers: A Hype Auditor study found that online influencers have roughly three times the engagement of their conventional counterparts. Virtual influencers should be used to boost brand engagement even though the data might not accurately reflect the entire sector.
Concerns about influencers created by computers
Virtual influencers could encourage excessive beauty standards in South Korea, which has a $10.7 billion plastic surgery industry.
A classic Korean beauty has a small face, huge eyes, and pale, immaculate skin. Virtual influencers like Lucy have these traits. According to Lee Eun-hee, a professor at Inha University's Department of Consumer Science, this could make national beauty standards more unrealistic, increasing demand for plastic surgery or cosmetic items.

Other parts of the world raise issues regarding selling items to consumers who don't recognize the models aren't human and the potential of cultural appropriation when generating influencers of other ethnicities, called digital blackface by some.
Meta, Facebook and Instagram's parent corporation, acknowledges this risk.
“Like any disruptive technology, synthetic media has the potential for both good and harm. Issues of representation, cultural appropriation and expressive liberty are already a growing concern,” the company stated in a blog post. “To help brands navigate the ethical quandaries of this emerging medium and avoid potential hazards, (Meta) is working with partners to develop an ethical framework to guide the use of (virtual influencers).”
Despite theoretical controversies, the industry will likely survive. Companies think virtual influencers are the next frontier in the digital world, which includes the metaverse, virtual reality, and digital currency.
In conclusion
Virtual influencers may garner millions of followers online and help marketers reach youthful audiences. According to a YouGov survey, the real impact of computer-generated influencers is yet unknown because people prefer genuine connections. Virtual characters can supplement brand marketing methods. When brands are metaverse-ready, the author predicts virtual influencer endorsement will continue to expand.
You might also like

Tim Smedley
3 years ago
When Investment in New Energy Surpassed That in Fossil Fuels (Forever)
A worldwide energy crisis might have hampered renewable energy and clean tech investment. Nope.
BNEF's 2023 Energy Transition Investment Trends study surprised and encouraged. Global energy transition investment reached $1 trillion for the first time ($1.11t), up 31% from 2021. From 2013, the clean energy transition has come and cannot be reversed.
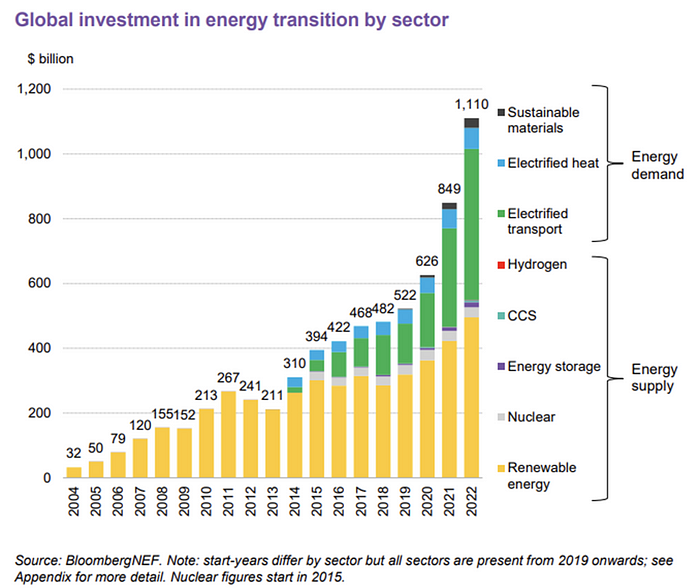
BNEF Head of Global Analysis Albert Cheung said our findings ended the energy crisis's influence on renewable energy deployment. Energy transition investment has reached a record as countries and corporations implement transition strategies. Clean energy investments will soon surpass fossil fuel investments.
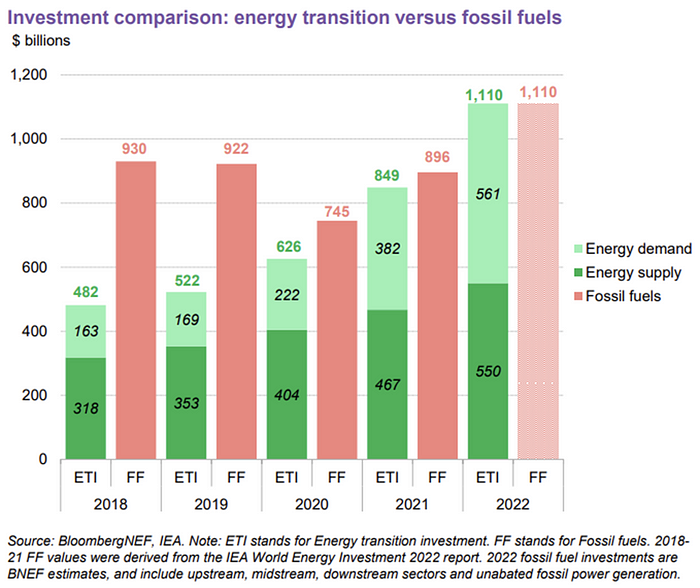
The table below indicates the tripping point, which means the energy shift is occuring today.
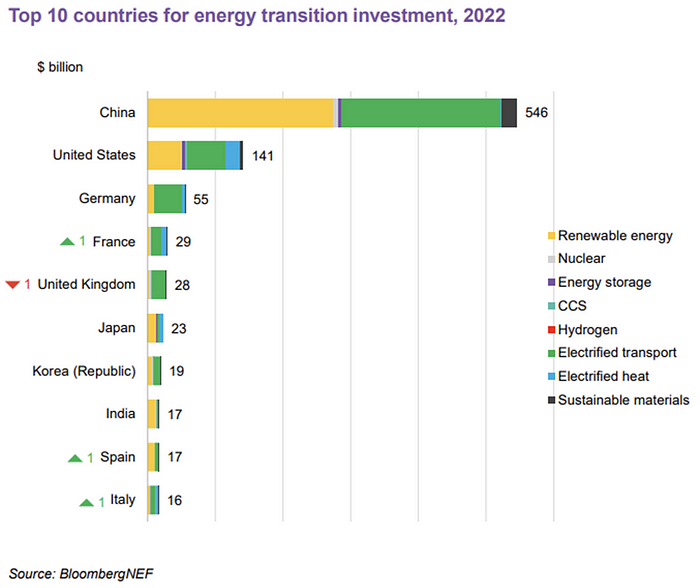
BNEF calls money invested on clean technology including electric vehicles, heat pumps, hydrogen, and carbon capture energy transition investment. In 2022, electrified heat received $64b and energy storage $15.7b.
Nonetheless, $495b in renewables (up 17%) and $466b in electrified transport (up 54%) account for most of the investment. Hydrogen and carbon capture are tiny despite the fanfare. Hydrogen received the least funding in 2022 at $1.1 billion (0.1%).
China dominates investment. China spends $546 billion on energy transition, half the global amount. Second, the US total of $141 billion in 2022 was up 11% from 2021. With $180 billion, the EU is unofficially second. China invested 91% in battery technologies.
The 2022 transition tipping point is encouraging, but the BNEF research shows how far we must go to get Net Zero. Energy transition investment must average $4.55 trillion between 2023 and 2030—three times the amount spent in 2022—to reach global Net Zero. Investment must be seven times today's record to reach Net Zero by 2050.
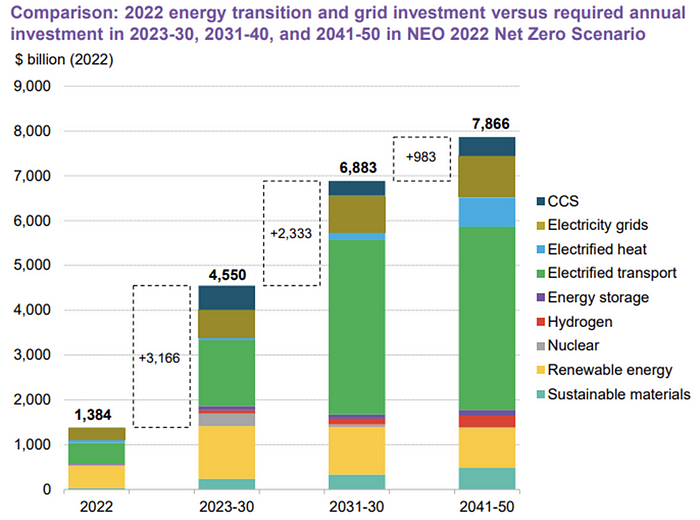
BNEF 2023 Energy Transition Investment Trends.
As shown in the graph above, BNEF experts have been using their crystal balls to determine where that investment should go. CCS and hydrogen are still modest components of the picture. Interestingly, they see nuclear almost fading. Active transport advocates like me may have something to say about the massive $4b in electrified transport. If we focus on walkable 15-minute cities, we may need fewer electric automobiles. Though we need more electric trains and buses.
Albert Cheung of BNEF emphasizes the challenge. This week's figures promise short-term job creation and medium-term energy security, but more investment is needed to reach net zero in the long run.
I expect the BNEF Energy Transition Investment Trends report to show clean tech investment outpacing fossil fuels investment every year. Finally saying that is amazing. It's insufficient. The planet must maintain its electric (not gas) pedal. In response to the research, Christina Karapataki, VC at Breakthrough Energy Ventures, a clean tech investment firm, tweeted: Clean energy investment needs to average more than 3x this level, for the remainder of this decade, to get on track for BNEFs Net Zero Scenario. Go!

Edward Williams
3 years ago
I currently manage 4 profitable online companies. I find all the generic advice and garbage courses very frustrating. The only advice you need is this.

This is for young entrepreneurs, especially in tech.
People give useless success advice on TikTok and Reddit. Early risers, bookworms, etc. Entrepreneurship courses. Work hard and hustle.
False. These aren't successful traits.
I mean, organization is good. As someone who founded several businesses and now works at a VC firm, I find these tips to be clichés.
Based on founding four successful businesses and working with other successful firms, here's my best actionable advice:
1. Choose a sector or a niche and become an expert in it.
This is more generic than my next tip, but it's a must-do that's often overlooked. Become an expert in the industry or niche you want to enter. Discover everything.
Buy (future) competitors' products. Understand consumers' pain points. Market-test. Target keyword combos. Learn technical details.
The most successful businesses I've worked with were all formed by 9-5 employees. They knew the industry's pain points. They started a business targeting these pain points.
2. Choose a niche or industry crossroads to target.
How do you choose an industry or niche? What if your industry is too competitive?
List your skills and hobbies. Randomness is fine. Find an intersection between two interests or skills.
Say you build websites well. You like cars.
Web design is a *very* competitive industry. Cars and web design?
Instead of web design, target car dealers and mechanics. Build a few fake demo auto mechanic websites, then cold call shops with poor websites. Verticalize.
I've noticed a pattern:
Person works in a particular industry for a corporation.
Person gains expertise in the relevant industry.
Person quits their job and launches a small business to address a problem that their former employer was unwilling to address.
I originally posted this on Reddit and it seemed to have taken off so I decided to share it with you all.
Focus on the product. When someone buys from you, you convince them the product's value exceeds the price. It's not fair and favors the buyer.
Creating a superior product or service will win. Narrowing this helps you outcompete others.
You may be their only (lucky) option.

CyberPunkMetalHead
3 years ago
Why Bitcoin NFTs Are Incomprehensible yet Likely Here to Stay

I'm trying to understand why Bitcoin NFTs aren't ready.
Ordinals, a new Bitcoin protocol, has been controversial. NFTs can be added to Bitcoin transactions using the protocol. They are not tokens or fungible. Bitcoin NFTs are transaction metadata. Yes. They're not owned.
In January, the Ordinals protocol allowed data like photos to be directly encoded onto sats, the smallest units of Bitcoin worth 0.00000001 BTC, on the Bitcoin blockchain. Ordinals does not need a sidechain or token like other techniques. The Ordinals protocol has encoded JPEG photos, digital art, new profile picture (PFP) projects, and even 1993 DOOM onto the Bitcoin network.
Ordinals inscriptions are permanent digital artifacts preserved on the Bitcoin blockchain. It differs from Ethereum, Solana, and Stacks NFT technologies that allow smart contract creators to change information. Ordinals store the whole image or content on the blockchain, not just a link to an external server, unlike centralized databases, which can change the linked image, description, category, or contract identifier.
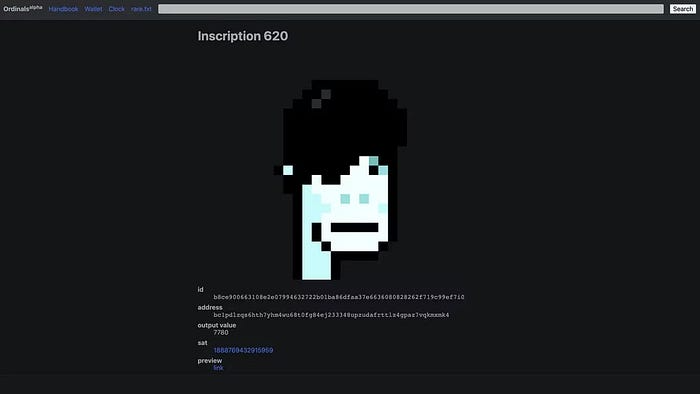
So far, more than 50,000 ordinals have been produced on the Bitcoin blockchain, and some of them have already been sold for astronomical amounts. The Ethereum-based CryptoPunks NFT collection spawned Ordinal Punk. Inscription 620 sold for 9.5 BTC, or $218,000, the most.
Segwit and Taproot, two important Bitcoin blockchain updates, enabled this. These protocols store transaction metadata, unlike Ethereum, where the NFT is the token. Bitcoin's NFT is a sat's transaction details.
What effects do ordinary values and NFTs have on the Bitcoin blockchain?
Ordinals will likely have long-term effects on the Bitcoin Ecosystem since they store, transact, and compute more data.
Charges Ordinals introduce scalability challenges. The Bitcoin network has limited transaction throughput and increased fees during peak demand. NFTs could make network transactions harder and more expensive. Ordinals currently occupy over 50% of block space, according to Glassnode.
One of the protocols that supported Ordinals Taproot has also seen a huge uptick:
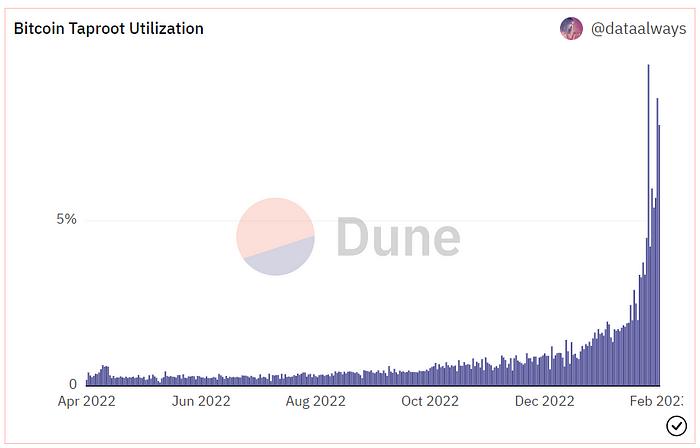
Taproot use increases block size and transaction costs.

This could cause network congestion but also support more L2s with Ordinals-specific use cases. Dune info here.
Storage Needs The Bitcoin blockchain would need to store more data to store NFT data directly. Since ordinals were introduced, blocksize has tripled from 0.7mb to over 2.2mb, which could increase storage costs and make it harder for nodes to join the network.
Use Case Diversity On the other hand, NFTs on the Bitcoin blockchain could broaden Bitcoin's use cases beyond storage and payment. This could expand Bitcoin's user base. This is two-sided. Bitcoin was designed to be trustless, decentralized, peer-to-peer money.
Chain to permanently store NFTs as ordinals will change everything.
Popularity rise This new use case will boost Bitcoin appeal, according to some. This argument fails since Bitcoin is the most popular cryptocurrency. Popularity doesn't require a new use case. Cryptocurrency adoption boosts Bitcoin. It need not compete with Ethereum or provide extra benefits to crypto investors. If there was a need for another chain that supports NFTs (there isn't), why would anyone choose the slowest and most expensive network? It appears contradictory and unproductive.
Nonetheless, holding an NFT on the Bitcoin blockchain is more secure than any other blockchain, but this has little utility.
Bitcoin NFTs are undoubtedly controversial. NFTs are strange and perhaps harmful to Bitcoin's mission. If Bitcoin NFTs are here to stay, I hope a sidechain or rollup solution will take over and leave the base chain alone.