



More on Leadership

Looi Qin En
3 years ago
I polled 52 product managers to find out what qualities make a great Product Manager
Great technology opens up an universe of possibilities.
Need a friend? WhatsApp, Telegram, Slack, etc.
Traveling? AirBnB, Expedia, Google Flights, etc.
Money transfer? Use digital banking, e-wallet, or crypto applications
Products inspire us. How do we become great?
I asked product managers in my network:
What does it take to be a great product manager?
52 product managers from 40+ prominent IT businesses in Southeast Asia responded passionately. Many of the PMs I've worked with have built fantastic products, from unicorns (Lazada, Tokopedia, Ovo) to incumbents (Google, PayPal, Experian, WarnerMedia) to growing (etaily, Nium, Shipper).
TL;DR:
Soft talents are more important than hard skills. Technical expertise was hardly ever stressed by product managers, and empathy was mentioned more than ten times. Janani from Xendit expertly recorded the moment. A superb PM must comprehend that their empathy for the feelings of their users must surpass all logic and data.
Constant attention to the needs of the user. Many people concur that the closer a PM gets to their customer/user, the more likely it is that the conclusion will be better. There were almost 30 references to customers and users. Focusing on customers has the advantage because it is hard to overshoot, as Rajesh from Lazada puts it best.
Setting priorities is invaluable. Prioritization is essential because there are so many problems that a PM must deal with every day. My favorite quotation on this is from Rakuten user Yee Jie. Viki, A competent product manager extinguishes fires. A good product manager lets things burn and then prioritizes.
This summary isn't enough to capture what excellent PMs claim it requires. Read below!

What qualities make a successful product manager?
Themed quotes are alphabetized by author.
Embrace your user/customer
Aeriel Dela Paz, Rainmaking Venture Architect, ex-GCash Product Head
Great PMs know what customers need even when they don’t say it directly. It’s about reading between the lines and going through the numbers to address that need.
Anders Nordahl, OrkestraSCS's Product Manager
Understanding the vision of your customer is as important as to get the customer to buy your vision
Angel Mendoza, MetaverseGo's Product Head
Most people think that to be a great product manager, you must have technical know-how. It’s textbook and I do think it is helpful to some extent, but for me the secret sauce is EMPATHY — the ability to see and feel things from someone else’s perspective. You can’t create a solution without deeply understanding the problem.
Senior Product Manager, Tokopedia
Focus on delivering value and helping people (consumer as well as colleague) and everything else will follow
Darren Lau, Deloitte Digital's Head of Customer Experience
Start with the users, and work backwards. Don’t have a solution looking for a problem
Darryl Tan, Grab Product Manager
I would say that a great product manager is able to identify the crucial problems to solve through strong user empathy and synthesis of insights
Diego Perdana, Kitalulus Senior Product Manager
I think to be a great product manager you need to be obsessed with customer problems and most important is solve the right problem with the right solution
Senior Product Manager, AirAsia
Lot of common sense + Customer Obsession. The most important role of a Product manager is to bring clarity of a solution. Your product is good if it solves customer problems. Your product is great if it solves an eco-system problem and disrupts the business in a positive way.
Edward Xie, Mastercard Managing Consultant, ex-Shopee Product Manager
Perfect your product, but be prepared to compromise for right users
AVP Product, Shipper
For me, a great product manager need to be rational enough to find the business opportunities while obsessing the customers.
Janani Gopalakrishnan is a senior product manager of a stealth firm.
While as a good PM it’s important to be data-driven, to be a great PM one needs to understand that their empathy for their users’ emotions must exceed all logic and data. Great PMs also make these product discussions thrive within the team by intently listening to all the members thoughts and influence the team’s skin in the game positively.
Director, Product Management, Indeed
Great product managers put their users first. They discover problems that matter most to their users and inspire their team to find creative solutions.
Grab's Senior Product Manager Lakshay Kalra
Product management is all about finding and solving most important user problems
Quipper's Mega Puji Saraswati
First of all, always remember the value of “user first” to solve what user really needs (the main problem) for guidance to arrange the task priority and develop new ideas. Second, ownership. Treat the product as your “2nd baby”, and the team as your “2nd family”. Third, maintain a good communication, both horizontally and vertically. But on top of those, always remember to have a work — life balance, and know exactly the priority in life :)
Senior Product Manager, Prosa.AI Miswanto Miswanto
A great Product Manager is someone who can be the link between customer needs with the readiness and flexibility of the team. So that it can provide, build, and produce a product that is useful and helps the community to carry out their daily activities. And He/She can improve product quality ongoing basis or continuous to help provide solutions for users or our customer.
Lead Product Manager, Tokopedia, Oriza Wahyu Utami
Be a great listener, be curious and be determined. every great product manager have the ability to listen the pain points and understand the problems, they are always curious on the users feedback, and they also very determined to look for the solutions that benefited users and the business.
99 Group CPO Rajesh Sangati
The advantage of focusing on customers: it’s impossible to overshoot
Ray Jang, founder of Scenius, formerly of ByteDance
The difference between good and great product managers is that great product managers are willing to go the unsexy and unglamorous extra mile by rolling up their sleeves and ironing out all minutiae details of the product such that when the user uses the product, they can’t help but say “This was made for me.”
BCG Digital Ventures' Sid Narayanan
Great product managers ensure that what gets built and shipped is at the intersection of what creates value for the customer and for the business that’s building the product…often times, especially in today’s highly liquid funding environment, the unit economics, aka ensuring that what gets shipped creates value for the business and is sustainable, gets overlooked
Stephanie Brownlee, BCG Digital Ventures Product Manager
There is software in the world that does more harm than good to people and society. Great Product Managers build products that solve problems not create problems
Experiment constantly
Delivery Hero's Abhishek Muralidharan
Embracing your failure is the key to become a great Product Manager
DeliveryHero's Anuraag Burman
Product Managers should be thick skinned to deal with criticism and the stomach to take risk and face failures.
DataSpark Product Head Apurva Lawale
Great product managers enjoy the creative process with their team to deliver intuitive user experiences to benefit users.
Dexter Zhuang, Xendit Product Manager
The key to creating winning products is building what customers want as quickly as you can — testing and learning along the way.
PayPal's Jay Ko
To me, great product managers always remain relentlessly curious. They are empathetic leaders and problem solvers that glean customer insights into building impactful products
Home Credit Philippines' Jedd Flores
Great Product Managers are the best dreamers; they think of what can be possible for the customers, for the company and the positive impact that it will have in the industry that they’re part of
Set priorities first, foremost, foremost.
HBO Go Product Manager Akshay Ishwar
Good product managers strive to balance the signal to noise ratio, Great product managers know when to turn the dials for each up exactly
Zuellig Pharma's Guojie Su
Have the courage to say no. Managing egos and request is never easy and rejecting them makes it harder but necessary to deliver the best value for the customers.
Ninja Van's John Prawira
(1) PMs should be able to ruthlessly prioritize. In order to be effective, PMs should anchor their product development process with their north stars (success metrics) and always communicate with a purpose. (2) User-first when validating assumptions. PMs should validate assumptions early and often to manage risk when leading initiatives with a focus on generating the highest impact to solving a particular user pain-point. We can’t expect a product/feature launch to be perfect (there might be bugs or we might not achieve our success metric — which is where iteration comes in), but we should try our best to optimize on user-experience earlier on.
Nium Product Manager Keika Sugiyama
I’d say a great PM holds the ability to balance ruthlessness and empathy at the same time. It’s easier said than done for sure!
ShopBack product manager Li Cai
Great product managers are like great Directors of movies. They do not create great products/movies by themselves. They deliver it by Defining, Prioritising, Energising the team to deliver what customers love.
Quincus' Michael Lim
A great product manager, keeps a pulse on the company’s big picture, identifies key problems, and discerns its rightful prioritization, is able to switch between the macro perspective to micro specifics, and communicates concisely with humility that influences naturally for execution
Mathieu François-Barseghian, SVP, Citi Ventures
“You ship your org chart”. This is Conway’s Law short version (1967!): the fundamental socio-technical driver behind innovation successes (Netflix) and failures (your typical bank). The hype behind micro-services is just another reflection of Conway’s Law
Mastercard's Regional Product Manager Nikhil Moorthy
A great PM should always look to build products which are scalable & viable , always keep the end consumer journey in mind. Keeping things simple & having a MVP based approach helps roll out products faster. One has to test & learn & then accordingly enhance / adapt, these are key to success
Rendy Andi, Tokopedia Product Manager
Articulate a clear vision and the path to get there, Create a process that delivers the best results and Be serious about customers.
Senior Product Manager, DANA Indonesia
Own the problem, not the solution — Great PMs are outstanding problem preventers. Great PMs are discerning about which problems to prevent, which problems to solve, and which problems not to solve
Tat Leong Seah, LionsBot International Senior UX Engineer, ex-ViSenze Product Manager
Prioritize outcomes for your users, not outputs of your system” or more succinctly “be agile in delivering value; not features”
Senior Product Manager, Rakuten Viki
A good product manager puts out fires. A great product manager lets fires burn and prioritize from there
acquire fundamental soft skills
Oracle NetSuite's Astrid April Dominguez
Personally, i believe that it takes grit, empathy, and optimistic mindset to become a great PM
Ovo Lead Product Manager Boy Al Idrus
Contrary to popular beliefs, being a great product manager doesn’t have anything to do with technicals, it sure plays a part but most important weapons are: understanding pain points of users, project management, sympathy in leadership and business critical skills; these 4 aspects would definitely help you to become a great product manager.
PwC Product Manager Eric Koh
Product managers need to be courageous to be successful. Courage is required to dive deep, solving big problems at its root and also to think far and dream big to achieve bold visions for your product
Ninja Van's Product Director
In my opinion the two most important ingredients to become a successful product manager is: 1. Strong critical thinking 2. Strong passion for the work. As product managers, we typically need to solve very complex problems where the answers are often very ambiguous. The work is tough and at times can be really frustrating. The 2 ingredients I mentioned earlier will be critical towards helping you to slowly discover the solution that may become a game changer.
PayPal's Lead Product Manager
A great PM has an eye of a designer, the brain of an engineer and the tongue of a diplomat
Product Manager Irene Chan
A great Product Manager is able to think like a CEO of the company. Visionary with Agile Execution in mind
Isabella Yamin, Rakuten Viki Product Manager
There is no one model of being a great product person but what I’ve observed from people I’ve had the privilege working with is an overflowing passion for the user problem, sprinkled with a knack for data and negotiation
Google product manager Jachin Cheng
Great product managers start with abundant intellectual curiosity and grow into a classic T-shape. Horizontally: generalists who range widely, communicate fluidly and collaborate easily cross-functionally, connect unexpected dots, and have the pulse both internally and externally across users, stakeholders, and ecosystem players. Vertically: deep product craftsmanship comes from connecting relentless user obsession with storytelling, business strategy with detailed features and execution, inspiring leadership with risk mitigation, and applying the most relevant tools to solving the right problems.
Jene Lim, Experian's Product Manager
3 Cs and 3 Rs. Critical thinking , Customer empathy, Creativity. Resourcefulness, Resilience, Results orientation.
Nirenj George, Envision Digital's Security Product Manager
A great product manager is someone who can lead, collaborate and influence different stakeholders around the product vision, and should be able to execute the product strategy based on customer insights, as well as take ownership of the product roadmap to create a greater impact on customers.
Grab's Lead Product Manager
Product Management is a multi-dimensional role that looks very different across each product team so each product manager has different challenges to deal with but what I have found common among great product managers is ability to create leverage through their efforts to drive outsized impacts for their products. This leverage is built using data with intuition, building consensus with stakeholders, empowering their teams and focussed efforts on needle moving work.
NCS Product Manager Umar Masagos
To be a great product manager, one must master both the science and art of Product Management. On one hand, you need have a strong understanding of the tools, metrics and data you need to drive your product. On the other hand, you need an in-depth understanding of your organization, your target market and target users, which is often the more challenging aspect to master.
M1 product manager Wei Jiao Keong
A great product manager is multi-faceted. First, you need to have the ability to see the bigger picture, yet have a keen eye for detail. Secondly, you are empathetic and is able to deliver products with exceptional user experience while being analytical enough to achieve business outcomes. Lastly, you are highly resourceful and independent yet comfortable working cross-functionally.
Yudha Utomo, ex-Senior Product Manager, Tokopedia
A great Product Manager is essentially an effective note-taker. In order to achieve the product goals, It is PM’s job to ensure objective has been clearly conveyed, efforts are assessed, and tasks are properly tracked and managed. PM can do this by having top-notch documentation skills.

Sean Bloomfield
3 years ago
How Jeff Bezos wins meetings over

We've all been there: You propose a suggestion to your team at a meeting, and most people appear on board, but a handful or small minority aren't. How can we achieve collective buy-in when we need to go forward but don't know how to deal with some team members' perceived intransigence?
Steps:
Investigate the divergent opinions: Begin by sincerely attempting to comprehend the viewpoint of your disagreeing coworkers. Maybe it makes sense to switch horses in the middle of the race. Have you completely overlooked a blind spot, such as a political concern that could arise as an unexpected result of proceeding? This is crucial to ensure that the person or people feel heard as well as to advance the goals of the team. Sometimes all individuals need is a little affirmation before they fully accept your point of view.
It says a lot about you as a leader to be someone who always lets the perceived greatest idea win, regardless of the originating channel, if after studying and evaluating you see the necessity to align with the divergent position.
If, after investigation and assessment, you determine that you must adhere to the original strategy, we go to Step 2.
2. Disagree and Commit: Jeff Bezos, CEO of Amazon, has had this experience, and Julie Zhuo describes how he handles it in her book The Making of a Manager.
It's OK to disagree when the team is moving in the right direction, but it's not OK to accidentally or purposefully damage the team's efforts because you disagree. Let the team know your opinion, but then help them achieve company goals even if they disagree. Unknown. You could be wrong in today's ever-changing environment.
So next time you have a team member who seems to be dissenting and you've tried the previous tactics, you may ask the individual in the meeting I understand you but I don't want us to leave without you on board I need your permission to commit to this approach would you give us your commitment?

Solomon Ayanlakin
3 years ago
Metrics for product management and being a good leader
Never design a product without explicit metrics and tracking tools.
Imagine driving cross-country without a dashboard. How do you know your school zone speed? Low gas? Without a dashboard, you can't monitor your car. You can't improve what you don't measure, as Peter Drucker said. Product managers must constantly enhance their understanding of their users, how they use their product, and how to improve it for optimum value. Customers will only pay if they consistently acquire value from your product.

I’m Solomon Ayanlakin. I’m a product manager at CredPal, a financial business that offers credit cards and Buy Now Pay Later services. Before falling into product management (like most PMs lol), I self-trained as a data analyst, using Alex the Analyst's YouTube playlists and DannyMas' virtual data internship. This article aims to help product managers, owners, and CXOs understand product metrics, give a methodology for creating them, and execute product experiments to enhance them.
☝🏽Introduction
Product metrics assist companies track product performance from the user's perspective. Metrics help firms decide what to construct (feature priority), how to build it, and the outcome's success or failure. To give the best value to new and existing users, track product metrics.
Why should a product manager monitor metrics?
to assist your users in having a "aha" moment
To inform you of which features are frequently used by users and which are not
To assess the effectiveness of a product feature
To aid in enhancing client onboarding and retention
To assist you in identifying areas throughout the user journey where customers are satisfied or dissatisfied
to determine the percentage of returning users and determine the reasons for their return
📈 What Metrics Ought a Product Manager to Monitor?
What indicators should a product manager watch to monitor product health? The metrics to follow change based on the industry, business stage (early, growth, late), consumer needs, and company goals. A startup should focus more on conversion, activation, and active user engagement than revenue growth and retention. The company hasn't found product-market fit or discovered what features drive customer value.
Depending on your use case, company goals, or business stage, here are some important product metric buckets:
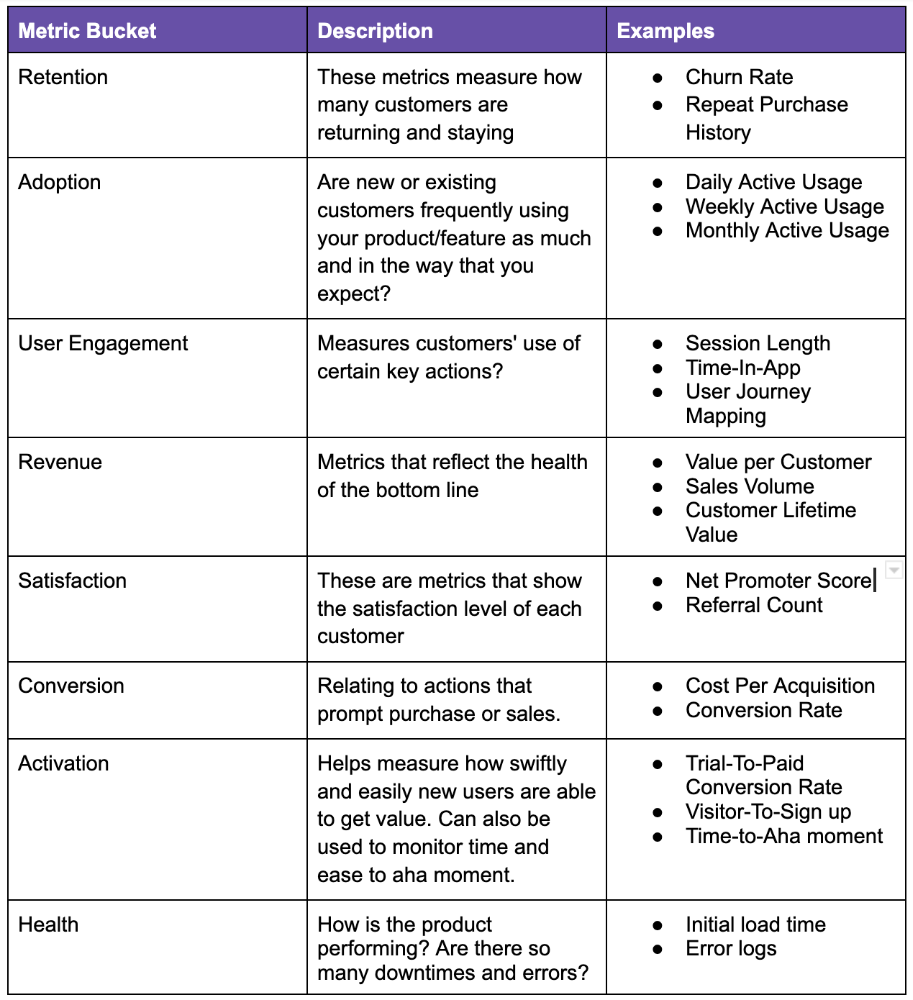
All measurements shouldn't be used simultaneously. It depends on your business goals and what value means for your users, then selecting what metrics to track to see if they get it.
Some KPIs are more beneficial to track, independent of industry or customer type. To prevent recording vanity metrics, product managers must clearly specify the types of metrics they should track. Here's how to segment metrics:
The North Star Metric, also known as the Focus Metric, is the indicator and aid in keeping track of the top value you provide to users.
Primary/Level 1 Metrics: These metrics should either add to the north star metric or be used to determine whether it is moving in the appropriate direction. They are metrics that support the north star metric.
These measures serve as leading indications for your north star and Level 2 metrics. You ought to have been aware of certain problems with your L2 measurements prior to the North star metric modifications.
North Star Metric
This is the key metric. A good north star metric measures customer value. It emphasizes your product's longevity. Many organizations fail to grow because they confuse north star measures with other indicators. A good focus metric should touch all company teams and be tracked forever. If a company gives its customers outstanding value, growth and success are inevitable. How do we measure this value?
A north star metric has these benefits:
Customer Obsession: It promotes a culture of customer value throughout the entire organization.
Consensus: Everyone can quickly understand where the business is at and can promptly make improvements, according to consensus.
Growth: It provides a tool to measure the company's long-term success. Do you think your company will last for a long time?
How can I pick a reliable North Star Metric?
Some fear a single metric. Ensure product leaders can objectively determine a north star metric. Your company's focus metric should meet certain conditions. Here are a few:
A good focus metric should reflect value and, as such, should be closely related to the point at which customers obtain the desired value from your product. For instance, the quick delivery to your home is a value proposition of UberEats. The value received from a delivery would be a suitable focal metric to use. While counting orders is alluring, the quantity of successfully completed positive review orders would make a superior north star statistic. This is due to the fact that a client who placed an order but received a defective or erratic delivery is not benefiting from Uber Eats. By tracking core value gain, which is the number of purchases that resulted in satisfied customers, we are able to track not only the total number of orders placed during a specific time period but also the core value proposition.
Focus metrics need to be quantifiable; they shouldn't only be feelings or states; they need to be actionable. A smart place to start is by counting how many times an activity has been completed.
A great focus metric is one that can be measured within predetermined time limits; otherwise, you are not measuring at all. The company can improve that measure more quickly by having time-bound focus metrics. Measuring and accounting for progress over set time periods is the only method to determine whether or not you are moving in the right path. You can then evaluate your metrics for today and yesterday. It's generally not a good idea to use a year as a time frame. Ideally, depending on the nature of your organization and the measure you are focusing on, you want to take into account on a daily, weekly, or monthly basis.
Everyone in the firm has the potential to affect it: A short glance at the well-known AAARRR funnel, also known as the Pirate Metrics, reveals that various teams inside the organization have an impact on the funnel. Ideally, the NSM should be impacted if changes are made to one portion of the funnel. Consider how the growth team in your firm is enhancing customer retention. This would have a good effect on the north star indicator because at this stage, a repeat client is probably being satisfied on a regular basis. Additionally, if the opposite were true and a client churned, it would have a negative effect on the focus metric.
It ought to be connected to the business's long-term success: The direction of sustainability would be indicated by a good north star metric. A company's lifeblood is product demand and revenue, so it's critical that your NSM points in the direction of sustainability. If UberEats can effectively increase the monthly total of happy client orders, it will remain in operation indefinitely.
Many product teams make the mistake of focusing on revenue. When the bottom line is emphasized, a company's goal moves from giving value to extracting money from customers. A happy consumer will stay and pay for your service. Customer lifetime value always exceeds initial daily, monthly, or weekly revenue.
Great North Star Metrics Examples

🥇 Basic/L1 Metrics:
The NSM is broad and focuses on providing value for users, while the primary metric is product/feature focused and utilized to drive the focus metric or signal its health. The primary statistic is team-specific, whereas the north star metric is company-wide. For UberEats' NSM, the marketing team may measure the amount of quality food vendors who sign up using email marketing. With quality vendors, more orders will be satisfied. Shorter feedback loops and unambiguous team assignments make L1 metrics more actionable and significant in the immediate term.
🥈 Supporting L2 metrics:
These are supporting metrics to the L1 and focus metrics. Location, demographics, or features are examples of L1 metrics. UberEats' supporting metrics might be the number of sales emails sent to food vendors, the number of opens, and the click-through rate. Secondary metrics are low-level and evident, and they relate into primary and north star measurements. UberEats needs a high email open rate to attract high-quality food vendors. L2 is a leading sign for L1.
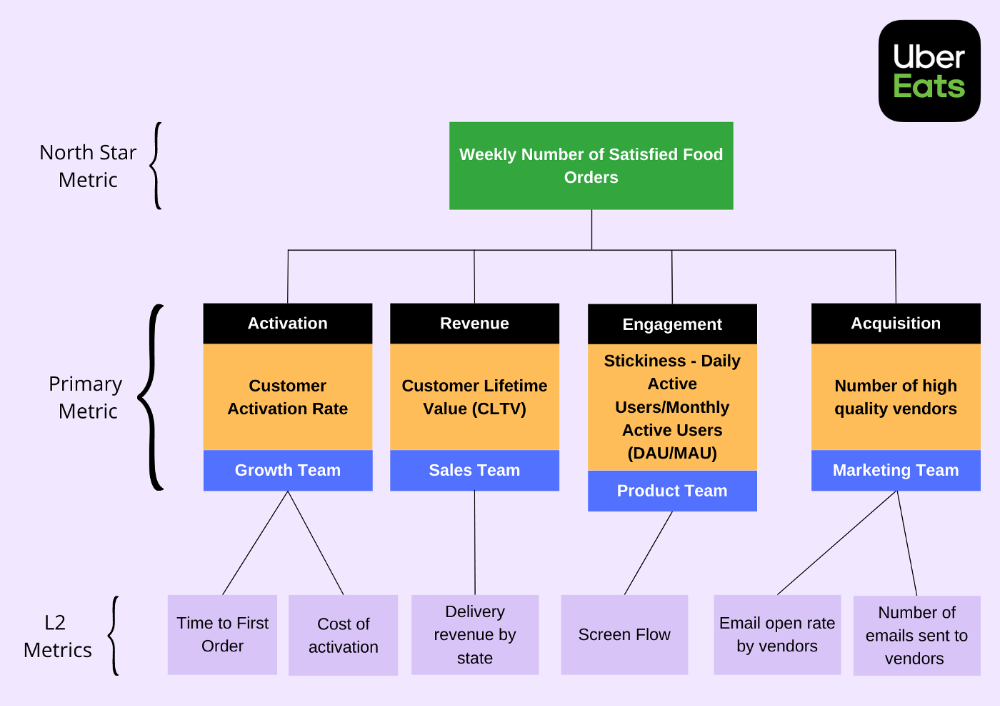
Where can I find product metrics?
How can I measure in-app usage and activity now that I know what metrics to track? Enter product analytics. Product analytics tools evaluate and improve product management parameters that indicate a product's health from a user's perspective.
Various analytics tools on the market supply product insight. From page views and user flows through A/B testing, in-app walkthroughs, and surveys. Depending on your use case and necessity, you may combine tools to see how users engage with your product. Gainsight, MixPanel, Amplitude, Google Analytics, FullStory, Heap, and Pendo are product tools.
This article isn't sponsored and doesn't market product analytics tools. When choosing an analytics tool, consider the following:
Tools for tracking your Focus, L1, and L2 measurements
Pricing
Adaptations to include external data sources and other products
Usability and the interface
Scalability
Security
An investment in the appropriate tool pays off. To choose the correct metrics to track, you must first understand your business need and what value means to your users. Metrics and analytics are crucial for any tech product's growth. It shows how your business is doing and how to best serve users.
You might also like

DC Palter
3 years ago
Is Venture Capital a Good Fit for Your Startup?
5 VC investment criteria

I reviewed 200 startup business concepts last week. Brainache.
The enterprises sold various goods and services. The concepts were achingly similar: give us money, we'll produce a product, then get more to expand. No different from daily plans and pitches.
Most of those 200 plans sounded plausible. But 10% looked venture-worthy. 90% of startups need alternatives to venture finance.
With the success of VC-backed businesses and the growth of venture funds, a common misperception is that investors would fund any decent company idea. Finding investors that believe in the firm and founders is the key to funding.
Incorrect. Venture capital needs investing in certain enterprises. If your startup doesn't match the model, as most early-stage startups don't, you can revise your business plan or locate another source of capital.
Before spending six months pitching angels and VCs, make sure your startup fits these criteria.
Likely to generate $100 million in sales
First, I check the income predictions in a pitch deck. If it doesn't display $100M, don't bother.
The math doesn't work for venture financing in smaller businesses.
Say a fund invests $1 million in a startup valued at $5 million that is later acquired for $20 million. That's a win everyone should celebrate. Most VCs don't care.
Consider a $100M fund. The fund must reach $360M in 7 years with a 20% return. Only 20-30 investments are possible. 90% of the investments will fail, hence the 23 winners must return $100M-$200M apiece. $15M isn't worth the work.
Angel investors and tiny funds use the same ideas as venture funds, but their smaller scale affects the calculations. If a company can support its growth through exit on less than $2M in angel financing, it must have $25M in revenues before large companies will consider acquiring it.
Aiming for Hypergrowth
A startup's size isn't enough. It must expand fast.
Developing a great business takes time. Complex technology must be constructed and tested, a nationwide expansion must be built, or production procedures must go from lab to pilot to factories. These can be enormous, world-changing corporations, but venture investment is difficult.
The normal 10-year venture fund life. Investments are made during first 3–4 years.. 610 years pass between investment and fund dissolution. Funds need their investments to exit within 5 years, 7 at the most, therefore add a safety margin.
Longer exit times reduce ROI. A 2-fold return in a year is excellent. Loss at 2x in 7 years.
Lastly, VCs must prove success to raise their next capital. The 2nd fund is raised from 1st fund portfolio increases. Third fund is raised using 1st fund's cash return. Fund managers must raise new money quickly to keep their jobs.
Branding or technology that is protected
No big firm will buy a startup at a high price if they can produce a competing product for less. Their development teams, consumer base, and sales and marketing channels are large. Who needs you?
Patents, specialist knowledge, or brand name are the only answers. The acquirer buys this, not the thing.
I've heard of several promising startups. It's not a decent investment if there's no exit strategy.
A company that installs EV charging stations in apartments and shopping areas is an example. It's profitable, repeatable, and big. A terrific company. Not a startup.
This building company's operations aren't secret. No technology to protect, no special information competitors can't figure out, no go-to brand name. Despite the immense possibilities, a large construction company would be better off starting their own.
Most venture businesses build products, not services. Services can be profitable but hard to safeguard.
Probable purchase at high multiple
Once a software business proves its value, acquiring it is easy. Pharma and medtech firms have given up on their own research and instead acquire startups after regulatory permission. Many startups, especially in specialized areas, have this weakness.
That doesn't mean any lucrative $25M-plus business won't be acquired. In many businesses, the venture model requires a high exit premium.
A startup invents a new glue. 3M, BASF, Henkel, and others may buy them. Adding more adhesive to their catalogs won't boost commerce. They won't compete to buy the business. They'll only buy a startup at a profitable price. The acquisition price represents a moderate EBITDA multiple.
The company's $100M revenue presumably yields $10m in profits (assuming they’ve reached profitability at all). A $30M-$50M transaction is likely. Not terrible, but not what venture investors want after investing $25M to create a plant and develop the business.
Private equity buys profitable companies for a moderate profit multiple. It's a good exit for entrepreneurs, but not for investors seeking 10x or more what PE firms pay. If a startup offers private equity as an exit, the conversation is over.
Constructed for purchase
The startup wants a high-multiple exit. Unless the company targets $1B in revenue and does an IPO, exit means acquisition.
If they're constructing the business for acquisition or themselves, founders must decide.
If you want an indefinitely-running business, I applaud you. We need more long-term founders. Most successful organizations are founded around consumer demands, not venture capital's urge to grow fast and exit. Not venture funding.
if you don't match the venture model, what to do
VC funds moonshots. The 10% that succeed are extraordinary. Not every firm is a rocketship, and launching the wrong startup into space, even with money, will explode.
But just because your startup won't make $100M in 5 years doesn't mean it's a bad business. Most successful companies don't follow this model. It's not venture capital-friendly.
Although venture capital gets the most attention due to a few spectacular triumphs (and disasters), it's not the only or even most typical option to fund a firm.
Other ways to support your startup:
Personal and family resources, such as credit cards, second mortgages, and lines of credit
bootstrapping off of sales
government funding and honors
Private equity & project financing
collaborating with a big business
Including a business partner
Before pitching angels and VCs, be sure your startup qualifies. If so, include them in your pitch.

Theresa W. Carey
4 years ago
How Payment for Order Flow (PFOF) Works
What is PFOF?
PFOF is a brokerage firm's compensation for directing orders to different parties for trade execution. The brokerage firm receives fractions of a penny per share for directing the order to a market maker.
Each optionable stock could have thousands of contracts, so market makers dominate options trades. Order flow payments average less than $0.50 per option contract.
Order Flow Payments (PFOF) Explained
The proliferation of exchanges and electronic communication networks has complicated equity and options trading (ECNs) Ironically, Bernard Madoff, the Ponzi schemer, pioneered pay-for-order-flow.
In a December 2000 study on PFOF, the SEC said, "Payment for order flow is a method of transferring trading profits from market making to brokers who route customer orders to specialists for execution."
Given the complexity of trading thousands of stocks on multiple exchanges, market making has grown. Market makers are large firms that specialize in a set of stocks and options, maintaining an inventory of shares and contracts for buyers and sellers. Market makers are paid the bid-ask spread. Spreads have narrowed since 2001, when exchanges switched to decimals. A market maker's ability to play both sides of trades is key to profitability.
Benefits, requirements
A broker receives fees from a third party for order flow, sometimes without a client's knowledge. This invites conflicts of interest and criticism. Regulation NMS from 2005 requires brokers to disclose their policies and financial relationships with market makers.
Your broker must tell you if it's paid to send your orders to specific parties. This must be done at account opening and annually. The firm must disclose whether it participates in payment-for-order-flow and, upon request, every paid order. Brokerage clients can request payment data on specific transactions, but the response takes weeks.
Order flow payments save money. Smaller brokerage firms can benefit from routing orders through market makers and getting paid. This allows brokerage firms to send their orders to another firm to be executed with other orders, reducing costs. The market maker or exchange benefits from additional share volume, so it pays brokerage firms to direct traffic.
Retail investors, who lack bargaining power, may benefit from order-filling competition. Arrangements to steer the business in one direction invite wrongdoing, which can erode investor confidence in financial markets and their players.
Pay-for-order-flow criticism
It has always been controversial. Several firms offering zero-commission trades in the late 1990s routed orders to untrustworthy market makers. During the end of fractional pricing, the smallest stock spread was $0.125. Options spreads widened. Traders found that some of their "free" trades cost them a lot because they weren't getting the best price.
The SEC then studied the issue, focusing on options trades, and nearly decided to ban PFOF. The proliferation of options exchanges narrowed spreads because there was more competition for executing orders. Options market makers said their services provided liquidity. In its conclusion, the report said, "While increased multiple-listing produced immediate economic benefits to investors in the form of narrower quotes and effective spreads, these improvements have been muted with the spread of payment for order flow and internalization."
The SEC allowed payment for order flow to continue to prevent exchanges from gaining monopoly power. What would happen to trades if the practice was outlawed was also unclear. SEC requires brokers to disclose financial arrangements with market makers. Since then, the SEC has watched closely.
2020 Order Flow Payment
Rule 605 and Rule 606 show execution quality and order flow payment statistics on a broker's website. Despite being required by the SEC, these reports can be hard to find. The SEC mandated these reports in 2005, but the format and reporting requirements have changed over the years, most recently in 2018.
Brokers and market makers formed a working group with the Financial Information Forum (FIF) to standardize order execution quality reporting. Only one retail brokerage (Fidelity) and one market maker remain (Two Sigma Securities). FIF notes that the 605/606 reports "do not provide the level of information that allows a retail investor to gauge how well a broker-dealer fills a retail order compared to the NBBO (national best bid or offer’) at the time the order was received by the executing broker-dealer."
In the first quarter of 2020, Rule 606 reporting changed to require brokers to report net payments from market makers for S&P 500 and non-S&P 500 equity trades and options trades. Brokers must disclose payment rates per 100 shares by order type (market orders, marketable limit orders, non-marketable limit orders, and other orders).
Richard Repetto, Managing Director of New York-based Piper Sandler & Co., publishes a report on Rule 606 broker reports. Repetto focused on Charles Schwab, TD Ameritrade, E-TRADE, and Robinhood in Q2 2020. Repetto reported that payment for order flow was higher in the second quarter than the first due to increased trading activity, and that options paid more than equities.
Repetto says PFOF contributions rose overall. Schwab has the lowest options rates, while TD Ameritrade and Robinhood have the highest. Robinhood had the highest equity rating. Repetto assumes Robinhood's ability to charge higher PFOF reflects their order flow profitability and that they receive a fixed rate per spread (vs. a fixed rate per share by the other brokers).
Robinhood's PFOF in equities and options grew the most quarter-over-quarter of the four brokers Piper Sandler analyzed, as did their implied volumes. All four brokers saw higher PFOF rates.
TD Ameritrade took the biggest income hit when cutting trading commissions in fall 2019, and this report shows they're trying to make up the shortfall by routing orders for additional PFOF. Robinhood refuses to disclose trading statistics using the same metrics as the rest of the industry, offering only a vague explanation on their website.
Summary
Payment for order flow has become a major source of revenue as brokers offer no-commission equity (stock and ETF) orders. For retail investors, payment for order flow poses a problem because the brokerage may route orders to a market maker for its own benefit, not the investor's.
Infrequent or small-volume traders may not notice their broker's PFOF practices. Frequent traders and those who trade larger quantities should learn about their broker's order routing system to ensure they're not losing out on price improvement due to a broker prioritizing payment for order flow.
This post is a summary. Read full article here

Ash Parrish
4 years ago
Sonic Prime and indie games on Netflix
Netflix will stream Spiritfarer, Raji: An Ancient Epic, and Lucky Luna.
Netflix's Geeked Week brought a slew of announcements. The flurry of reveals for The Sandman, The Umbrella Academy season 3, One Piece, and more also included game and game-adjacent announcements.
Netflix released a teaser for Cuphead season 2 ahead of its August premiere, featuring more of Grey DeLisle's Ms. Chalice. DOTA: Dragon's Blood season 3 hits Netflix in August. Tekken, the fighting game that throws kids off cliffs, gets an anime, Tekken: Bloodline.
Netflix debuted a clip of Sonic Prime before Sonic Origins in June and Sonic Frontiers in 2022.
Castlevania: Nocturne will follow Richter Belmont.
Netflix is reviving licensed games with titles based on its shows. There's a Queen's Gambit chess game, a Shadow and Bone RPG, a La Casa de Papel heist adventure, and a Too Hot to Handle game where a pregnant woman must choose between stabbing her cheating ex or forgiving him.
Riot's rhythm platformer Hextech Mayhem debuted on Netflix last year, and now Netflix is adding games from Devolver Digital. Reigns: Three Kingdoms is a card game that lets players choose the fate of Three Kingdoms-era China by swiping left or right on cards. Spiritfarer, the "cozy game about death" from 2020, and Raji: An Ancient Epic are coming to Netflix. Poinpy, a vertical climber from the creator of Downwell, is now on Netflix.
Desta: The Memories Between is a turn-based strategy game set in dreams and memories.
Snowman's Lucky Luna will also be added soon.
With these games, Netflix is expanding beyond dinky mobile games — it plans to have 50 by the end of the year — and could be a serious platform for indies that want to expand into mobile. It takes gaming seriously.