


Farhad Malik
Farhad Malik
2 years ago
How This Python Script Makes Me Money Every Day
Starting a passive income stream with data science and programming
My website is fresh. But how do I monetize it?
Creating a passive-income website is difficult. Advertise first. But what useful are ads without traffic?
Let’s Generate Traffic And Put Our Programming Skills To Use
SEO boosts traffic (Search Engine Optimisation). Traffic generation is complex. Keywords matter more than text, URL, photos, etc.
My Python skills helped here. I wanted to find relevant, Google-trending keywords (tags) for my topic.
First The Code
I wrote the script below here.
import re
from string import punctuation
import nltk
from nltk import TreebankWordTokenizer, sent_tokenize
from nltk.corpus import stopwords
class KeywordsGenerator:
def __init__(self, pytrends):
self._pytrends = pytrends
def generate_tags(self, file_path, top_words=30):
file_text = self._get_file_contents(file_path)
clean_text = self._remove_noise(file_text)
top_words = self._get_top_words(clean_text, top_words)
suggestions = []
for top_word in top_words:
suggestions.extend(self.get_suggestions(top_word))
suggestions.extend(top_words)
tags = self._clean_tokens(suggestions)
return ",".join(list(set(tags)))
def _remove_noise(self, text):
#1. Convert Text To Lowercase and remove numbers
lower_case_text = str.lower(text)
just_text = re.sub(r'\d+', '', lower_case_text)
#2. Tokenise Paragraphs To words
list = sent_tokenize(just_text)
tokenizer = TreebankWordTokenizer()
tokens = tokenizer.tokenize(just_text)
#3. Clean text
clean = self._clean_tokens(tokens)
return clean
def _clean_tokens(self, tokens):
clean_words = [w for w in tokens if w not in punctuation]
stopwords_to_remove = stopwords.words('english')
clean = [w for w in clean_words if w not in stopwords_to_remove and not w.isnumeric()]
return clean
def get_suggestions(self, keyword):
print(f'Searching pytrends for {keyword}')
result = []
self._pytrends.build_payload([keyword], cat=0, timeframe='today 12-m')
data = self._pytrends.related_queries()[keyword]['top']
if data is None or data.values is None:
return result
result.extend([x[0] for x in data.values.tolist()][:2])
return result
def _get_file_contents(self, file_path):
return open(file_path, "r", encoding='utf-8',errors='ignore').read()
def _get_top_words(self, words, top):
counts = dict()
for word in words:
if word in counts:
counts[word] += 1
else:
counts[word] = 1
return list({k: v for k, v in sorted(counts.items(), key=lambda item: item[1])}.keys())[:top]
if __name__ == "1__main__":
from pytrends.request import TrendReq
nltk.download('punkt')
nltk.download('stopwords')
pytrends = TrendReq(hl='en-GB', tz=360)
tags = KeywordsGenerator(pytrends)\
.generate_tags('text_file.txt')
print(tags)Then The Dependencies
This script requires:
nltk==3.7
pytrends==4.8.0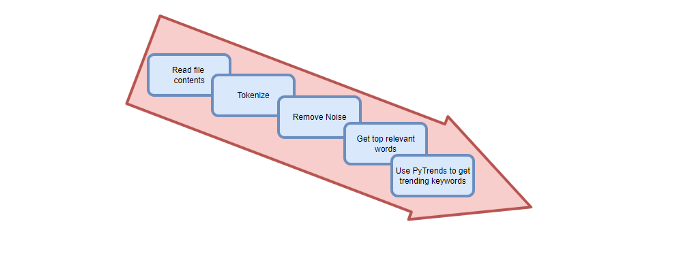
Analysis of the Script
I copy and paste my article into text file.txt, and the code returns the keywords as a comma-separated string.
To achieve this:
A class I made is called KeywordsGenerator.
This class has a function:
generate_tagsThe function
generate_tagsperforms the following tasks:
retrieves text file contents
uses NLP to clean the text by tokenizing sentences into words, removing punctuation, and other elements.
identifies the most frequent words that are relevant.
The
pytrendsAPI is then used to retrieve related phrases that are trending for each word from Google.finally adds a comma to the end of the word list.
4. I then use the keywords and paste them into the SEO area of my website.
These terms are trending on Google and relevant to my topic. My site's rankings and traffic have improved since I added new keywords. This little script puts our knowledge to work. I shared the script in case anyone faces similar issues.
I hope it helps readers sell their work.