





More on Productivity

Jano le Roux
3 years ago
My Top 11 Tools For Building A Modern Startup, With A Free Plan
The best free tools are probably unknown to you.
Modern startups are easy to build.
Start with free tools.
Let’s go.
Web development — Webflow
Code-free HTML, CSS, and JS.
Webflow isn't like Squarespace, Wix, or Shopify.
It's a super-fast no-code tool for professionals to construct complex, highly-responsive websites and landing pages.
Webflow can help you add animations like those on Apple's website to your own site.
I made the jump from WordPress a few years ago and it changed my life.
No damn plugins. No damn errors. No damn updates.
The best, you can get started on Webflow for free.
Data tracking — Airtable
Spreadsheet wings.
Airtable combines spreadsheet flexibility with database power without code.
Airtable is modern.
Airtable has modularity.
Scaling Airtable is simple.
Airtable, one of the most adaptable solutions on this list, is perfect for client data management.
Clients choose customized service packages. Airtable consolidates data so you can automate procedures like invoice management and focus on your strengths.
Airtable connects with so many tools that rarely creates headaches. Airtable scales when you do.
Airtable's flexibility makes it a potential backend database.
Design — Figma
Better, faster, easier user interface design.
Figma rocks!
It’s fast.
It's free.
It's adaptable
First, design in Figma.
Iterate.
Export development assets.
Figma lets you add more team members as your company grows to work on each iteration simultaneously.
Figma is web-based, so you don't need a powerful PC or Mac to start.
Task management — Trello
Unclock jobs.
Tacky and terrifying task management products abound. Trello isn’t.
Those that follow Marie Kondo will appreciate Trello.
Everything is clean.
Nothing is complicated.
Everything has a place.
Compared to other task management solutions, Trello is limited. And that’s good. Too many buttons lead to too many decisions lead to too many hours wasted.
Trello is a must for teamwork.
Domain email — Zoho
Free domain email hosting.
Professional email is essential for startups. People relied on monthly payments for too long. Nope.
Zoho offers 5 free professional emails.
It doesn't have Google's UI, but it works.
VPN — Proton VPN
Fast Swiss VPN protects your data and privacy.
Proton VPN is secure.
Proton doesn't record any data.
Proton is based in Switzerland.
Swiss privacy regulation is among the most strict in the world, therefore user data are protected. Switzerland isn't a 14 eye country.
Journalists and activists trust Proton to secure their identities while accessing and sharing information authoritarian governments don't want them to access.
Web host — Netlify
Free fast web hosting.
Netlify is a scalable platform that combines your favorite tools and APIs to develop high-performance sites, stores, and apps through GitHub.
Serverless functions and environment variables preserve API keys.
Netlify's free tier is unmissable.
100GB of free monthly bandwidth.
Free 125k serverless operations per website each month.
Database — MongoDB
Create a fast, scalable database.
MongoDB is for small and large databases. It's a fast and inexpensive database.
Free for the first million reads.
Then, for each million reads, you must pay $0.10.
MongoDB's free plan has:
Encryption from end to end
Continual authentication
field-level client-side encryption
If you have a large database, you can easily connect MongoDB to Webflow to bypass CMS limits.
Automation — Zapier
Time-saving tip: automate repetitive chores.
Zapier simplifies life.
Zapier syncs and connects your favorite apps to do impossibly awesome things.
If your online store is connected to Zapier, a customer's purchase can trigger a number of automated actions, such as:
The customer is being added to an email chain.
Put the information in your Airtable.
Send a pre-programmed postcard to the customer.
Alexa, set the color of your smart lights to purple.
Zapier scales when you do.
Email & SMS marketing — Omnisend
Email and SMS marketing campaigns.
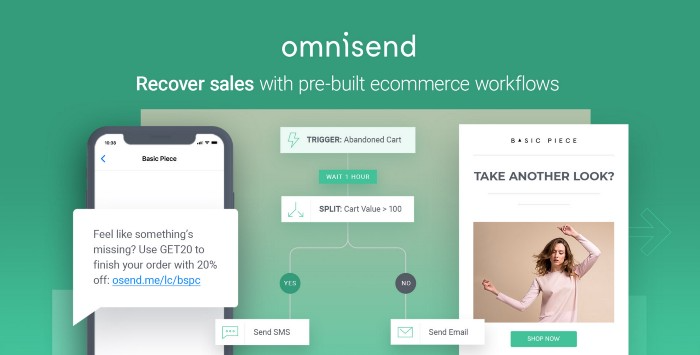
This is an excellent Mailchimp option for magical emails. Omnisend's processes simplify email automation.
I love the interface's cleanliness.
Omnisend's free tier includes web push notifications.
Send up to:
500 emails per month
60 maximum SMSs
500 Web Push Maximum
Forms and surveys — Tally
Create flexible forms that people enjoy.
Typeform is clean but restricting. Sometimes you need to add many questions. Tally's needed sometimes.
Tally is flexible and cheaper than Typeform.
99% of Tally's features are free and unrestricted, including:
Unlimited forms
Countless submissions
Collect payments
File upload
Tally lets you examine what individuals contributed to forms before submitting them to see where they get stuck.
Airtable and Zapier connectors automate things further. If you pay, you can apply custom CSS to fit your brand.
See.
Free tools are the greatest.
Let's use them to launch a startup.

Jon Brosio
3 years ago
Every time I use this 6-part email sequence, I almost always make four figures.
(And you can have it for free)

Master email to sell anything.
Most novice creators don't know how to begin.
Many use online templates. These are usually fluff-filled and niche-specific.
They're robotic and "salesy."
I've attended 3 courses, read 10 books, and sent 600,000 emails in the past five years.
Outcome?
This *proven* email sequence assures me a month's salary every time I send it.
What you will discover in this article is that:
A full 6-part email sales cycle
The essential elements you must incorporate
placeholders and text-filled images
(Applies to any niche)
This can be a product introduction, holiday, or welcome sequence. This works for email-saleable products.
Let's start
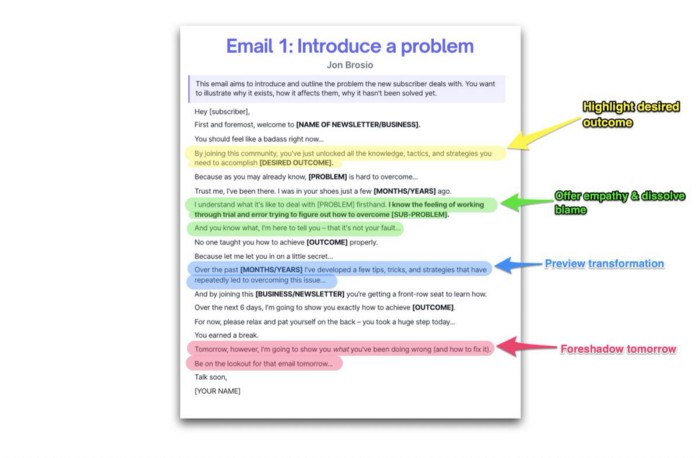
Email 1: Describe your issue
This email is crucial.
How to? We introduce a subscriber or prospect's problem. Later, we'll frame our offer as the solution.
Label the:
Problem
Why it still hasn't been fixed
Resulting implications for the customer
This puts our new subscriber in solve mode and queues our offer:
Email 2: Amplify the consequences
We're still causing problems.
We've created the problem, but now we must employ emotion and storytelling to make it real. We also want to forecast life if nothing changes.
Let's feel:
What occurs if it is not resolved?
Why is it crucial to fix it immediately?
Tell a tale of a person who was in their position. To emphasize the effects, use a true account of another person (or of yourself):

Email 3: Share a transformation story
Selling stories.
Whether in an email, landing page, article, or video. Humanize stories. They give information meaning.
This is where "issue" becomes "solution."
Let's reveal:
A tale of success
A new existence and result
tools and tactics employed
Start by transforming yourself.

Email 4: Prove with testimonials
No one buys what you say.
Emotionally stirred people buy and act. They believe in the product. They feel that if they buy, it will work.
Social proof shows prospects that your solution will help them.
Add:
Earlier and Later
Testimonials
Reviews
Proof this deal works:

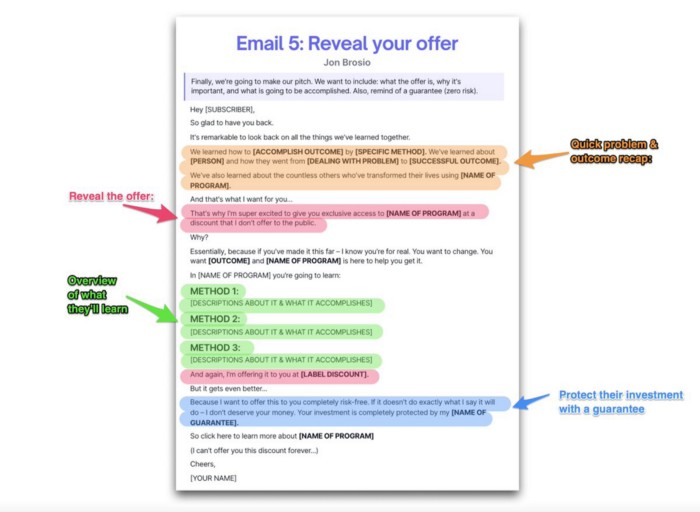
Email 5: Reveal your offer
It's showtime.
This is it. Until now, describing the offer and offering links to a landing page have been sparse in the email pictures.
We've been tense. Gaining steam. Building suspense. Email 5 reveals all.
In this email:
a description of the deal
A word about a promise
recapitulation of the transformation
and make a reference to the urgency Everything should be spelled out clearly:
Email no. 6: Instill urgency
When there are stakes, humans act.
Creating and marketing with haste raises the stakes. Urgency makes a prospect act because they'll miss out or gain immensely.
Urgency converts. Use:
short time
Screening
Scarcity
Urgency and conversions. Limited-time offers are easy.
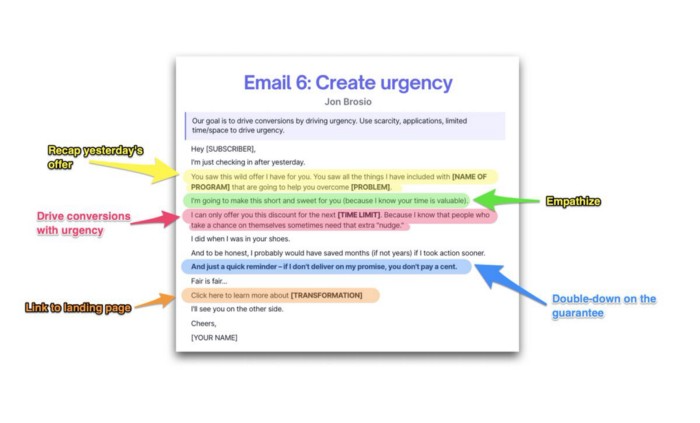
TL;DR
Use this proven 6-part email sequence (that turns subscribers into profit):
Introduce a problem
Amplify it with emotions
Share transformation story
Prove it works with testimonials
Value-stack and present your offer
Drive urgency and entice the purchase

Deon Ashleigh
3 years ago
You can dominate your daily productivity with these 9 little-known Google Calendar tips.
Calendars are great unpaid employees.
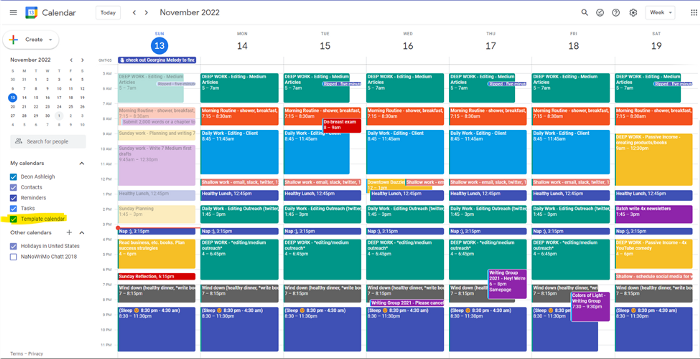
After using Notion to organize my next three months' goals, my days were a mess.
I grew very chaotic afterward. I was overwhelmed, unsure of what to do, and wasting time attempting to plan the day after it had started.
Imagine if our skeletons were on the outside. Doesn’t work.
The goals were too big; I needed to break them into smaller chunks. But how?
Enters Google Calendar
RescueTime’s recommendations took me seven hours to make a daily planner. This epic narrative begins with a sheet of paper and concludes with a daily calendar that helps me focus and achieve more goals. Ain’t nobody got time for “what’s next?” all day.
Onward!
Return to the Paleolithic Era
Plan in writing.
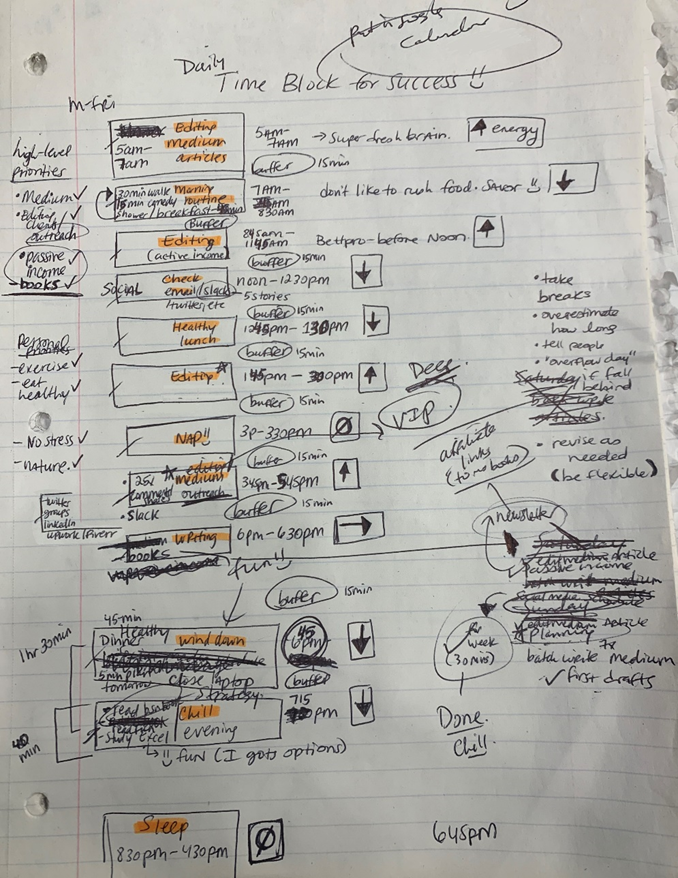
Not on the list, but it helped me plan my day. Physical writing boosts creativity and recall.
Find My Heart
i.e. prioritize
RescueTime suggested I prioritize before planning. Personal and business goals were proposed.
My top priorities are to exercise, eat healthily, spend time in nature, and avoid stress.
Priorities include writing and publishing Medium articles, conducting more freelance editing and Medium outreach, and writing/editing sci-fi books.
These eight things will help me feel accomplished every day.
Make a baby calendar.
Create daily calendar templates.
Make family, pleasure, etc. calendars.
Google Calendar instructions:
Other calendars
Press the “+” button
Create a new calendar
Create recurring events for each day
My calendar, without the template:
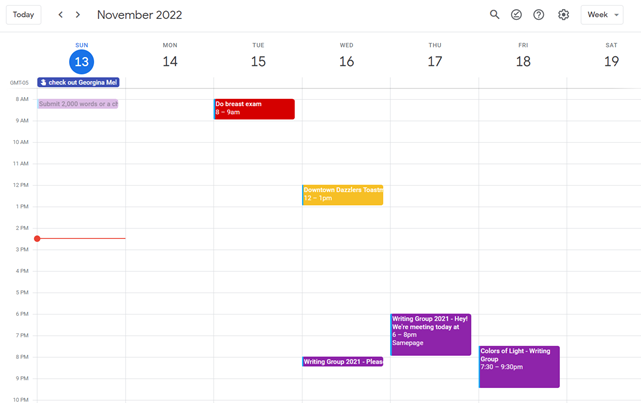
Empty, so I can fill it with vital tasks.
With the template:
My daily skeleton corresponds with my priorities. I've been overwhelmed for years because I lack daily, weekly, monthly, and yearly structure.
Google Calendars helps me reach my goals and focus my energy.
Get your colored pencils ready
Time-block color-coding.
Color labeling lets me quickly see what's happening. Maybe you are too.
Google Calendar instructions:
Determine which colors correspond to each time block.
When establishing new events, select a color.
Save
My calendar is color-coded as follows:
Yellow — passive income or other future-related activities
Red — important activities, like my monthly breast exam
Flamingo — shallow work, like emails, Twitter, etc.
Blue — all my favorite activities, like walking, watching comedy, napping, and sleeping. Oh, and eating.
Green — money-related events required for this adulting thing
Purple — writing-related stuff
Associating a time block with a color helps me stay focused. Less distractions mean faster work.
Open My Email
aka receive a daily email from Google Calendar.
Google Calendar sends a daily email feed of your calendars. I sent myself the template calendar in this email.
Google Calendar instructions:
Access settings
Select the calendar that you want to send (left side)
Go down the page to see more alerts
Under the daily agenda area, click Email.

Get in Touch With Your Red Bull Wings — Naturally
aka audit your energy levels.
My daily planner has arrows. These indicate how much energy each activity requires or how much I have.
Rightward arrow denotes medium energy.
I do my Medium and professional editing in the morning because it's energy-intensive.
Niharikaa Sodhi recommends morning Medium editing.
I’m a morning person. As long as I go to bed at a reasonable time, 5 a.m. is super wild GO-TIME. It’s like the world was just born, and I marvel at its wonderfulness.
Freelance editing lets me do what I want. An afternoon snooze will help me finish on time.
Ditch Schedule View
aka focus on the weekly view.
RescueTime advocated utilizing the weekly view of Google Calendar, so I switched.
When you launch the phone app or desktop calendar, a red line shows where you are in the day.
I'll follow the red line's instructions. My digital supervisor is easy to follow.
In the image above, it's almost 3 p.m., therefore the red line implies it's time to snooze.
I won't forget this block ;).
Reduce the Lighting
aka dim previous days.
This is another Google Calendar feature I didn't know about. Once the allotted time passes, the time block dims. This keeps me present.
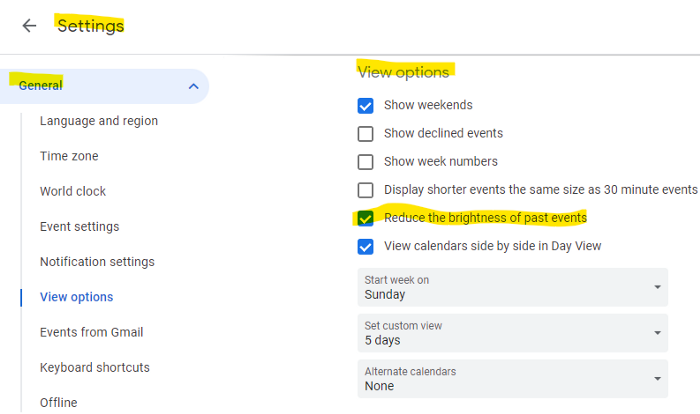
Google Calendar instructions:
Access settings
remaining general
To view choices, click.
Check Diminish the glare of the past.
Bonus
Two additional RescueTimes hacks:
Maintain a space between tasks
I left 15 minutes between each time block to transition smoothly. This relates to my goal of less stress. If I set strict start and end times, I'll be stressed.
With a buffer, I can breathe, stroll around, and start the following time block fresh.
Find a time is related to the buffer.
This option allows you conclude small meetings five minutes early and longer ones ten. Before the next meeting, relax or go wild.
Decide on a backup day.
This productivity technique is amazing.
Spend this excess day catching up on work. It helps reduce tension and clutter.
That's all I can say about Google Calendar's functionality.
You might also like

Web3Lunch
3 years ago
An employee of OpenSea might get a 40-year prison sentence for insider trading using NFTs.

The space had better days. Those greenish spikes...oh wow, haven't felt that in ages. Cryptocurrencies and NFTs have lost popularity. Google agrees. Both are declining.
As seen below, crypto interest spiked in May because of the Luna fall. NFT interest is similar to early October last year.
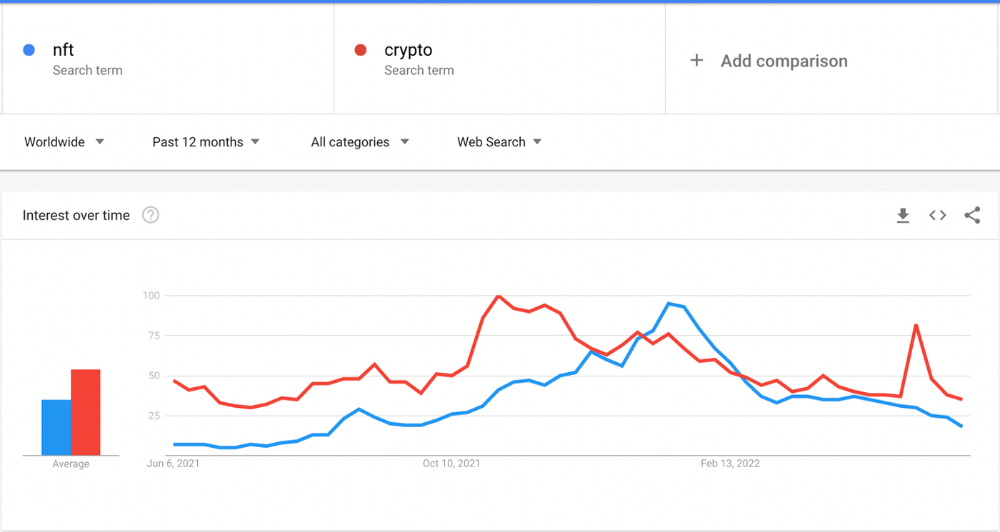
This makes me think NFTs are mostly hype and FOMO. No art or community. I've seen enough initiatives to know that communities stick around if they're profitable. Once it starts falling, they move on to the next project. The space has no long-term investments. Flip everything.
OpenSea trading volume has stayed steady for months. May's volume is 1.8 million ETH ($3.3 billion).
Despite this, I think NFTs and crypto will stick around. In bad markets, builders gain most.
Only 4k developers are active on Ethereum blockchain. It's low. A great chance for the space enthusiasts.
An employee of OpenSea might get a 40-year prison sentence for insider trading using NFTs.
Nathaniel Chastian, an OpenSea employee, traded on insider knowledge. He'll serve 40 years for that.
Here's what happened if you're unfamiliar.
OpenSea is a secondary NFT marketplace. Their homepage featured remarkable drops. Whatever gets featured there, NFT prices will rise 5x.
Chastian was at OpenSea. He chose forthcoming NFTs for OpenSeas' webpage.
Using anonymous digital currency wallets and OpenSea accounts, he would buy NFTs before promoting them on the homepage, showcase them, and then sell them for at least 25 times the price he paid.
From June through September 2021, this happened. Later caught, fired. He's charged with wire fraud and money laundering, each carrying a 20-year maximum penalty.
Although web3 space is all about decentralization, a step like this is welcomed since it restores faith in the area. We hope to see more similar examples soon.
Here's the press release.

Understanding smart contracts
@cantino.eth has a Twitter thread on smart contracts. Must-read. Also, he appears educated about the space, so follow him.


xuanling11
3 years ago
Reddit NFT Achievement

Reddit's NFT market is alive and well.
NFT owners outnumber OpenSea on Reddit.
Reddit NFTs flip in OpenSea in days:
Fast-selling.
NFT sales will make Reddit's current communities more engaged.
I don't think NFTs will affect existing groups, but they will build hype for people to acquire them.
The first season of Collectibles is unique, but many missed the first season.
Second-season NFTs are less likely to be sold for a higher price than first-season ones.
If you use Reddit, it's fun to own NFTs.

Nick
3 years ago
This Is How Much Quora Paid Me For 23 Million Content Views
You’ll be surprised; I sure was

Blogging and writing online as a side income has now been around for a significant amount of time. Nowadays, it is a continuously rising moneymaker for prospective writers, with several writing platforms existing online. At the top of the list are Medium, Vocal Media, Newsbreak, and the biggest one of them, Quora, with 300 million active users.
Quora, unlike Medium, is a question-and-answer format platform. On Medium you are permitted to write what you want, while on Quora, you answer questions on topics that you have expertise about. Quora, like Medium, now compensates its authors for the answers they provide in comparison to the previous, in which you had to be admitted to the partner program and were paid to ask questions.
Quora just recently went live with this new partner program, Quora Plus, and the way it works is that it is a subscription for $5 a month which provides you access to metered/monetized stories, in turn compensating the writers for part of that subscription for their answers.
I too on Quora have found a lot of success on the platform, gaining 23 Million Content Views, and 300,000 followers for my space, which is kind of the Quora equivalent of a Medium article. The way in which I was able to do this was entirely thanks to a hack that I uncovered to the Quora algorithm.
In this article, I plan on discussing how much money I received from 23 million content views on Quora, and I bet you’ll be shocked; I know I was.
A Brief Explanation of How I Got 23 Million Views and How You Can Do It Too
On Quora, everything in terms of obtaining views is about finding the proper question, which I only understood quite late into the game. I published my first response in 2019 but never actually wrote on Quora until the summer of 2020, and about a month into posting consistently I found out how to find the perfect question. Here’s how:
The Process
Go to your Home Page and start scrolling… While browsing, check for the following things…
Answers from people you follow or your followers.
Advertisements
These two things are the two things you want to ignore, you don’t want to answer those questions or look at the ads. You should now be left with a couple of recommended answers. To discover which recommended answer is the best to answer as well, look at these three important aspects.
Date of the answer: Was it in the past few days, preferably 2–3 days, even better, past 24 hours?
Views: Are they in the ten thousands or hundred thousands?
Upvotes: Are they in the hundreds or thousands?
Now, choose an answer to a question which you think you could answer as well that satisfies the requirements above. Once you click on it, as all answers on Quora works, it will redirect you to the page for that question, in which you will have to select once again if you should answer the question.
Amount of answers: How many responses are there to the given question? This tells you how much competition you have. My rule is beyond 25 answers, you shouldn’t answer, but you can change it anyway you’d like.
Answerers: Who did the answering for the question? If the question includes a bunch of renowned, extremely well-known people on Quora, there’s a good possibility your essay is going to get drowned out.
Views: Check for a constant quantity of high views on each answer for the question; this is what will guarantee that your answer gets a lot of views!
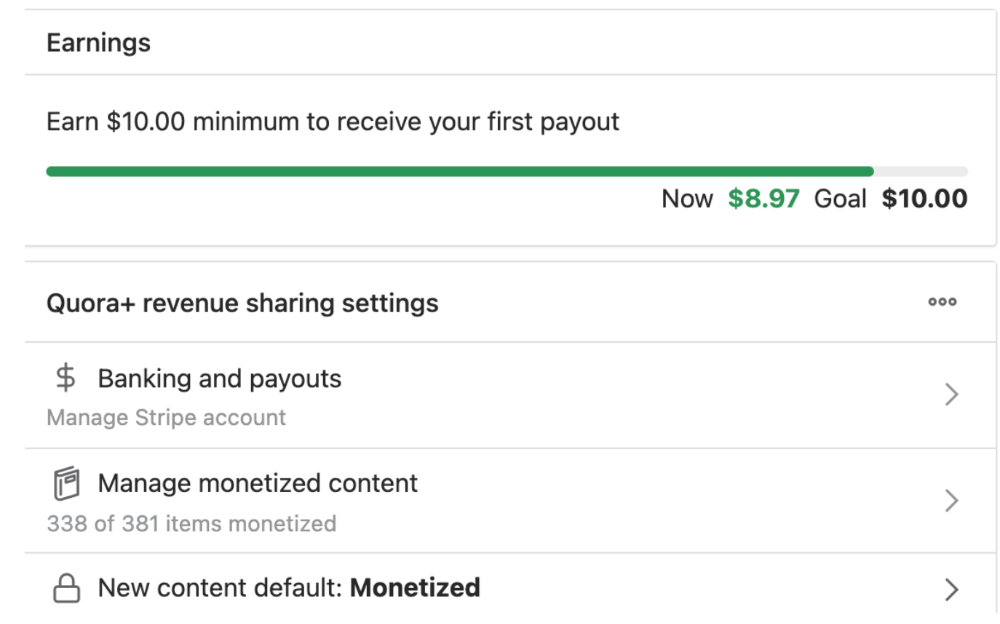
The Income Reveal! How Much I Made From 23 Million Content Views
DRUM ROLL, PLEASE!
8.97 USD. Yes, not even ten dollars, not even nine. Just eight dollars and ninety-seven cents.
Possible Reasons for My Low Earnings
Quora Plus and the answering partner program are newer than my Quora views.
Few people use Quora+, therefore revenues are low.
I haven't been writing much on Quora, so I'm only making money from old answers and a handful since Quora Plus launched.
Quora + pays poorly...
Should You Try Quora and Quora For Money?
My answer depends on your needs. I never got invited to Quora's question partner program due to my late start, but other writers have made hundreds. Due to Quora's new and competitive answering partner program, you may not make much money.
If you want a fun writing community, try Quora. Quora was fun when I only made money from my space. Quora +'s paywalls and new contributors eager to make money have made the platform less fun for me.
This article is a summary to save you time. You can read my full, more detailed article, here.