



More on Productivity

Pen Magnet
3 years ago
Why Google Staff Doesn't Work

Sundar Pichai unveiled Simplicity Sprint at Google's latest all-hands conference.
To boost employee efficiency.
Not surprising. Few envisioned Google declaring a productivity drive.
Sunder Pichai's speech:
“There are real concerns that our productivity as a whole is not where it needs to be for the head count we have. Help me create a culture that is more mission-focused, more focused on our products, more customer focused. We should think about how we can minimize distractions and really raise the bar on both product excellence and productivity.”
The primary driver driving Google's efficiency push is:
Google's efficiency push follows 13% quarterly revenue increase. Last year in the same quarter, it was 62%.
Market newcomers may argue that the previous year's figure was fuelled by post-Covid reopening and growing consumer spending. Investors aren't convinced. A promising company like Google can't afford to drop so quickly.
Google’s quarterly revenue growth stood at 13%, against 62% in last year same quarter.
Google isn't alone. In my recent essay regarding 2025 programmers, I warned about the economic downturn's effects on FAAMG's workforce. Facebook had suspended hiring, and Microsoft had promised hefty bonuses for loyal staff.
In the same article, I predicted Google's troubles. Online advertising, especially the way Google and Facebook sell it using user data, is over.
FAAMG and 2nd rung IT companies could be the first to fall without Post-COVID revival and uncertain global geopolitics.
Google has hardly ever discussed effectiveness:
Apparently openly.
Amazon treats its employees like robots, even in software positions. It has significant turnover and a terrible reputation as a result. Because of this, it rarely loses money due to staff productivity.
Amazon trumps Google. In reality, it treats its employees poorly.
Google was the founding father of the modern-day open culture.
Larry and Sergey Google founded the IT industry's Open Culture. Silicon Valley called Google's internal democracy and transparency near anarchy. Management rarely slammed decisions on employees. Surveys and internal polls ensured everyone knew the company's direction and had a vote.
20% project allotment (weekly free time to build own project) was Google's open-secret innovation component.
After Larry and Sergey's exit in 2019, this is Google's first profitability hurdle. Only Google insiders can answer these questions.
Would Google's investors compel the company's management to adopt an Amazon-style culture where the developers are treated like circus performers?
If so, would Google follow suit?
If so, how does Google go about doing it?
Before discussing Google's likely plan, let's examine programming productivity.
What determines a programmer's productivity is simple:
How would we answer Google's questions?
As a programmer, I'm more concerned about Simplicity Sprint's aftermath than its economic catalysts.
Large organizations don't care much about quarterly and annual productivity metrics. They have 10-year product-launch plans. If something seems horrible today, it's likely due to someone's lousy judgment 5 years ago who is no longer in the blame game.
Deconstruct our main question.
How exactly do you change the culture of the firm so that productivity increases?
How can you accomplish that without affecting your capacity to profit? There are countless ways to increase output without decreasing profit.
How can you accomplish this with little to no effect on employee motivation? (While not all employers care about it, in this case we are discussing the father of the open company culture.)
How do you do it for a 10-developer IT firm that is losing money versus a 1,70,000-developer organization with a trillion-dollar valuation?
When implementing a large-scale organizational change, success must be carefully measured.
The fastest way to do something is to do it right, no matter how long it takes.
You require clearly-defined group/team/role segregation and solid pass/fail matrices to:
You can give performers rewards.
Ones that are average can be inspired to improve
Underachievers may receive assistance or, in the worst-case scenario, rehabilitation
As a 20-year programmer, I associate productivity with greatness.
Doing something well, no matter how long it takes, is the fastest way to do it.
Let's discuss a programmer's productivity.
Why productivity is a strange term in programming:
Productivity is work per unit of time.
Money=time This is an economic proverb. More hours worked, more pay. Longer projects cost more.
As a buyer, you desire a quick supply. As a business owner, you want employees who perform at full capacity, creating more products to transport and boosting your profits.
All economic matrices encourage production because of our obsession with it. Productivity is the only organic way a nation may increase its GDP.
Time is money — is not just a proverb, but an economical fact.
Applying the same productivity theory to programming gets problematic. An automating computer. Its capacity depends on the software its master writes.
Today, a sophisticated program can process a billion records in a few hours. Creating one takes a competent coder and the necessary infrastructure. Learning, designing, coding, testing, and iterations take time.
Programming productivity isn't linear, unlike manufacturing and maintenance.
Average programmers produce code every day yet miss deadlines. Expert programmers go days without coding. End of sprint, they often surprise themselves by delivering fully working solutions.
Reversing the programming duties has no effect. Experts aren't needed for productivity.
These patterns remind me of an XKCD comic.
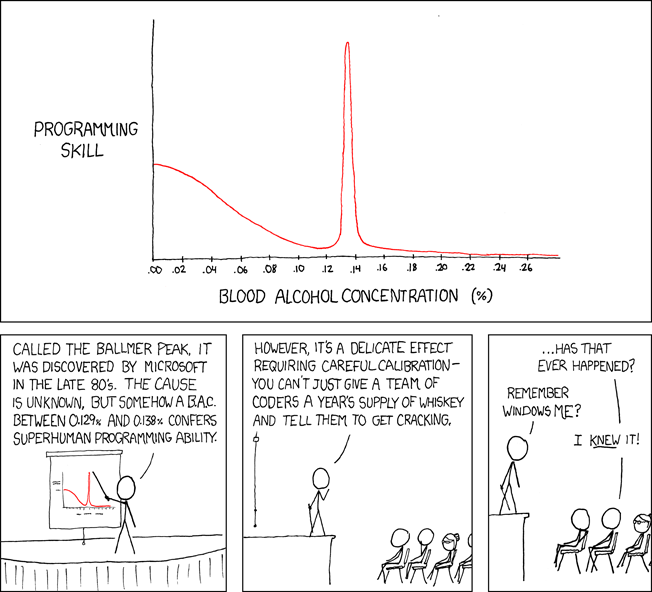
Programming productivity depends on two factors:
The capacity of the programmer and his or her command of the principles of computer science
His or her productive bursts, how often they occur, and how long they last as they engineer the answer
At some point, productivity measurement becomes Schrödinger’s cat.
Product companies measure productivity using use cases, classes, functions, or LOCs (lines of code). In days of data-rich source control systems, programmers' merge requests and/or commits are the most preferred yardstick. Companies assess productivity by tickets closed.
Every organization eventually has trouble measuring productivity. Finer measurements create more chaos. Every measure compares apples to oranges (or worse, apples with aircraft.) On top of the measuring overhead, the endeavor causes tremendous and unnecessary stress on teams, lowering their productivity and defeating its purpose.
Macro productivity measurements make sense. Amazon's factory-era management has done it, but at great cost.
Google can pull it off if it wants to.
What Google meant in reality when it said that employee productivity has decreased:
When Google considers its employees unproductive, it doesn't mean they don't complete enough work in the allotted period.
They can't multiply their work's influence over time.
Programmers who produce excellent modules or products are unsure on how to use them.
The best data scientists are unable to add the proper parameters in their models.
Despite having a great product backlog, managers struggle to recruit resources with the necessary skills.
Product designers who frequently develop and A/B test newer designs are unaware of why measures are inaccurate or whether they have already reached the saturation point.
Most ignorant: All of the aforementioned positions are aware of what to do with their deliverables, but neither their supervisors nor Google itself have given them sufficient authority.
So, Google employees aren't productive.
How to fix it?
Business analysis: White suits introducing novel items can interact with customers from all regions. Track analytics events proactively, especially the infrequent ones.
SOLID, DRY, TEST, and AUTOMATION: Do less + reuse. Use boilerplate code creation. If something already exists, don't implement it yourself.
Build features-building capabilities: N features are created by average programmers in N hours. An endless number of features can be built by average programmers thanks to the fact that expert programmers can produce 1 capability in N hours.
Work on projects that will have a positive impact: Use the same algorithm to search for images on YouTube rather than the Mars surface.
Avoid tasks that can only be measured in terms of time linearity at all costs (if a task can be completed in N minutes, then M copies of the same task would cost M*N minutes).
In conclusion:
Software development isn't linear. Why should the makers be measured?
Notation for The Big O
I'm discussing a new way to quantify programmer productivity. (It applies to other professions, but that's another subject)
The Big O notation expresses the paradigm (the algorithmic performance concept programmers rot to ace their Google interview)
Google (or any large corporation) can do this.
Sort organizational roles into categories and specify their impact vs. time objectives. A CXO role's time vs. effect function, for instance, has a complexity of O(log N), meaning that if a CEO raises his or her work time by 8x, the result only increases by 3x.
Plot the influence of each employee over time using the X and Y axes, respectively.
Add a multiplier for Y-axis values to the productivity equation to make business objectives matter. (Example values: Support = 5, Utility = 7, and Innovation = 10).
Compare employee scores in comparable categories (developers vs. devs, CXOs vs. CXOs, etc.) and reward or help employees based on whether they are ahead of or behind the pack.
After measuring every employee's inventiveness, it's straightforward to help underachievers and praise achievers.
Example of a Big(O) Category:
If I ran Google (God forbid, its worst days are far off), here's how I'd classify it. You can categorize Google employees whichever you choose.
The Google interview truth:
O(1) < O(log n) < O(n) < O(n log n) < O(n^x) where all logarithmic bases are < n.
O(1): Customer service workers' hours have no impact on firm profitability or customer pleasure.
CXOs Most of their time is spent on travel, strategic meetings, parties, and/or meetings with minimal floor-level influence. They're good at launching new products but bad at pivoting without disaster. Their directions are being followed.
Devops, UX designers, testers Agile projects revolve around deployment. DevOps controls the levers. Their automation secures results in subsequent cycles.
UX/UI Designers must still prototype UI elements despite improved design tools.
All test cases are proportional to use cases/functional units, hence testers' work is O(N).
Architects Their effort improves code quality. Their right/wrong interference affects product quality and rollout decisions even after the design is set.
Core Developers Only core developers can write code and own requirements. When people understand and own their labor, the output improves dramatically. A single character error can spread undetected throughout the SDLC and cost millions.
Core devs introduce/eliminate 1000x bugs, refactoring attempts, and regression. Following our earlier hypothesis.
The fastest way to do something is to do it right, no matter how long it takes.
Conclusion:
Google is at the liberal extreme of the employee-handling spectrum
Microsoft faced an existential crisis after 2000. It didn't choose Amazon's data-driven people management to revitalize itself.
Instead, it entrusted developers. It welcomed emerging technologies and opened up to open source, something it previously opposed.
Google is too lax in its employee-handling practices. With that foundation, it can only follow Amazon, no matter how carefully.
Any attempt to redefine people's measurements will affect the organization emotionally.
The more Google compares apples to apples, the higher its chances for future rebirth.

Jumanne Rajabu Mtambalike
3 years ago
10 Years of Trying to Manage Time and Improve My Productivity.
I've spent the last 10 years of my career mastering time management. I've tried different approaches and followed multiple people and sources. My knowledge is summarized.
Great people, including entrepreneurs, master time management. I learned time management in college. I was studying Computer Science and Finance and leading Tanzanian students in Bangalore, India. I had 24 hours per day to do this and enjoy campus. I graduated and received several awards. I've learned to maximize my time. These tips and tools help me finish quickly.
Eisenhower-Box
I don't remember when I read the article. James Clear, one of my favorite bloggers, introduced me to the Eisenhower Box, which I've used for years. Eliminate waste to master time management. By grouping your activities by importance and urgency, the tool helps you prioritize what matters and drop what doesn't. If it's urgent, do it. Delegate if it's urgent but not necessary. If it's important but not urgent, reschedule it; otherwise, drop it. I integrated the tool with Trello to manage my daily tasks. Since 2007, I've done this.

James Clear's article mentions Eisenhower Box.
Essentialism rules
Greg McKeown's book Essentialism introduced me to disciplined pursuit of less. I once wrote about this. I wasn't sure what my career's real opportunities and distractions were. A non-essentialist thinks everything is essential; you want to be everything to everyone, and your life lacks satisfaction. Poor time management starts it all. Reading and applying this book will change your life.

Essential vs non-essential
Life Calendar
Most of us make corporate calendars. Peter Njonjo, founder of Twiga Foods, said he manages time by putting life activities in his core calendars. It includes family retreats, weddings, and other events. He joked that his wife always complained to him to avoid becoming a calendar item. It's key. "Time Masters" manages life's four burners, not just work and corporate life. There's no "work-life balance"; it's life.

Health, Family, Work, and Friends.
The Brutal No
In a culture where people want to look good, saying "NO" to a favor request seems rude. In reality, the crime is breaking a promise. "Time Masters" have mastered "NO". More "YES" means less time, and more "NO" means more time for tasks and priorities. Brutal No doesn't mean being mean to your coworkers; it means explaining kindly and professionally that you have other priorities.
To-Do vs. MITs
Most people are productive with a routine to-do list. You can't be effective by just checking boxes on a To-do list. When was the last time you completed all of your daily tasks? Never. You must replace the to-do list with Most Important Tasks (MITs). MITs allow you to focus on the most important tasks on your list. You feel progress and accomplishment when you finish these tasks. MITs don't include ad-hoc emails, meetings, etc.
Journal Mapped
Most people don't journal or plan their day in the developing South. I've learned to plan my day in my journal over time. I have multiple sections on one page: MITs (things I want to accomplish that day), Other Activities (stuff I can postpone), Life (health, faith, and family issues), and Pop-Ups (things that just pop up). I leave the next page blank for notes. I reflected on the blocks to identify areas to improve the next day. You will have bad days, but at least you'll realize it was due to poor time management.
Buy time/delegate
Time or money? When you make enough money, you lose time to make more. The smart buy "Time." I resisted buying other people's time for years. I regret not hiring an assistant sooner. Learn to buy time from others and pay for time-consuming tasks. Sometimes you think you're saving money by doing things yourself, but you're actually losing money.
This post is a summary. See the full post here.

Darshak Rana
3 years ago
17 Google Secrets 99 Percent of People Don't Know
What can't Google do?
Seriously, nothing! Google rocks.
Google is a major player in online tools and services. We use it for everything, from research to entertainment.
Did I say entertain yourself?
Yes, with so many features and options, it can be difficult to fully utilize Google.
#1. Drive Google Mad
You can make Google's homepage dance if you want to be silly.
Just type “Google Gravity” into Google.com. Then select I'm lucky.
See the page unstick before your eyes!
#2 Play With Google Image
Google isn't just for work.
Then have fun with it!
You can play games right in your search results. When you need a break, google “Solitaire” or “Tic Tac Toe”.
#3. Do a Barrel Roll
Need a little more excitement in your life? Want to see Google dance?
Type “Do a barrel roll” into the Google search bar.
Then relax and watch your screen do a 360.
#4 No Internet? No issue!
This is a fun trick to use when you have no internet.
If your browser shows a “No Internet” page, simply press Space.
Boom!
We have dinosaurs! Now use arrow keys to save your pixelated T-Rex from extinction.
#5 Google Can Help
Play this Google coin flip game to see if you're lucky.
Enter “Flip a coin” into the search engine.
You'll see a coin flipping animation. If you get heads or tails, click it.
#6. Think with Google
My favorite Google find so far is the “Think with Google” website.
Think with Google is a website that offers marketing insights, research, and case studies.
I highly recommend it to entrepreneurs, small business owners, and anyone interested in online marketing.
#7. Google Can Read Images!
This is a cool Google trick that few know about.
You can search for images by keyword or upload your own by clicking the camera icon on Google Images.
Google will then show you all of its similar images.
Caution: You should be fine with your uploaded images being public.
#8. Modify the Google Logo!
Clicking on the “I'm Feeling Lucky” button on Google.com takes you to a random Google Doodle.
Each year, Google creates a Doodle to commemorate holidays, anniversaries, and other occasions.
#9. What is my IP?
Simply type “What is my IP” into Google to find out.
Your IP address will appear on the results page.
#10. Send a Self-Destructing Email With Gmail,
Create a new message in Gmail. Find an icon that resembles a lock and a clock near the SEND button. That's where the Confidential Mode is.
By clicking it, you can set an expiration date for your email. Expiring emails are automatically deleted from both your and the recipient's inbox.
#11. Blink, Google Blink!
This is a unique Google trick.
Type “blink HTML” into Google. The words “blink HTML” will appear and then disappear.
The text is displayed for a split second before being deleted.
To make this work, Google reads the HTML code and executes the “blink” command.
#12. The Answer To Everything
This is for all Douglas Adams fans.
The answer to life, the universe, and everything is 42, according to Google.
An allusion to Douglas Adams' Hitchhiker's Guide to the Galaxy, in which Ford Prefect seeks to understand life, the universe, and everything.
#13. Google in 1998
It's a blast!
Type “Google in 1998” into Google. "I'm feeling lucky"
You'll be taken to an old-school Google homepage.
It's a nostalgic trip for long-time Google users.
#14. Scholarships and Internships
Google can help you find college funding!
Type “scholarships” or “internships” into Google.
The number of results will surprise you.
#15. OK, Google. Dice!
To roll a die, simply type “Roll a die” into Google.
On the results page is a virtual dice that you can click to roll.
#16. Google has secret codes!
Hit the nine squares on the right side of your Google homepage to go to My Account. Then Personal Info.
You can add your favorite language to the “General preferences for the web” tab.
#17. Google Terminal
You can feel like a true hacker.
Just type “Google Terminal” into Google.com. "I'm feeling lucky"
Voila~!
You'll be taken to an old-school computer terminal-style page.
You can then type commands to see what happens.
Have you tried any of these activities? Tell me in the comments.
Read full article here
You might also like

Rajesh Gupta
3 years ago
Why Is It So Difficult to Give Up Smoking?

I started smoking in 2002 at IIT BHU. Most of us thought it was enjoyable at first. I didn't realize the cost later.
In 2005, during my final semester, I lost my father. Suddenly, I felt more accountable for my mother and myself.
I quit before starting my first job in Bangalore. I didn't see any smoking friends in my hometown for 2 months before moving to Bangalore.
For the next 5-6 years, I had no regimen and smoked only when drinking.
Due to personal concerns, I started smoking again after my 2011 marriage. Now smoking was a constant guilty pleasure.
I smoked 3-4 cigarettes a day, but never in front of my family or on weekends. I used to excuse this with pride! First office ritual: smoking. Even with guilt, I couldn't stop this time because of personal concerns.
After 8-9 years, in mid 2019, a personal development program solved all my problems. I felt complete in myself. After this, I just needed one cigarette each day.
The hardest thing was leaving this final cigarette behind, even though I didn't want it.
James Clear's Atomic Habits was published last year. I'd only read 2-3 non-tech books before reading this one in August 2021. I knew everything but couldn't use it.
In April 2022, I realized the compounding effect of a bad habit thanks to my subconscious mind. 1 cigarette per day (excluding weekends) equals 240 = 24 packs per year, which is a lot. No matter how much I did, it felt negative.
Then I applied the 2nd principle of this book, identifying the trigger. I tried to identify all the major triggers of smoking. I found social drinking is one of them & If I am able to control it during that time, I can easily control it in other situations as well. Going further whenever I drank, I was pre-determined to ignore the craving at any cost. Believe me, it was very hard initially but gradually this craving started fading away even with drinks.
I've been smoke-free for 3 months. Now I know a bad habit's effects. After realizing the power of habits, I'm developing other good habits which I ignored all my life.
Matthew Royse
3 years ago
7 ways to improve public speaking
How to overcome public speaking fear and give a killer presentation

"Public speaking is people's biggest fear, according to studies. Death's second. The average person is better off in the casket than delivering the eulogy." — American comedian, actor, writer, and producer Jerry Seinfeld
People fear public speaking, according to research. Public speaking can be intimidating.
Most professions require public speaking, whether to 5, 50, 500, or 5,000 people. Your career will require many presentations. In a small meeting, company update, or industry conference.
You can improve your public speaking skills. You can reduce your anxiety, improve your performance, and feel more comfortable speaking in public.
“If I returned to college, I'd focus on writing and public speaking. Effective communication is everything.” — 38th president Gerald R. Ford
You can deliver a great presentation despite your fear of public speaking. There are ways to stay calm while speaking and become a more effective public speaker.
Seven tips to improve your public speaking today. Let's help you overcome your fear (no pun intended).
Know your audience.
"You're not being judged; the audience is." — Entrepreneur, author, and speaker Seth Godin
Understand your audience before speaking publicly. Before preparing a presentation, know your audience. Learn what they care about and find useful.
Your presentation may depend on where you're speaking. A classroom is different from a company meeting.
Determine your audience before developing your main messages. Learn everything about them. Knowing your audience helps you choose the right words, information (thought leadership vs. technical), and motivational message.
2. Be Observant
Observe others' speeches to improve your own. Watching free TED Talks on education, business, science, technology, and creativity can teach you a lot about public speaking.
What worked and what didn't?
What would you change?
Their strengths
How interesting or dull was the topic?
Note their techniques to learn more. Studying the best public speakers will amaze you.
Learn how their stage presence helped them communicate and captivated their audience. Please note their pauses, humor, and pacing.
3. Practice
"A speaker should prepare based on what he wants to learn, not say." — Author, speaker, and pastor Tod Stocker
Practice makes perfect when it comes to public speaking. By repeating your presentation, you can find your comfort zone.
When you've practiced your presentation many times, you'll feel natural and confident giving it. Preparation helps overcome fear and anxiety. Review notes and important messages.
When you know the material well, you can explain it better. Your presentation preparation starts before you go on stage.
Keep a notebook or journal of ideas, quotes, and examples. More content means better audience-targeting.
4. Self-record
Videotape your speeches. Check yourself. Body language, hands, pacing, and vocabulary should be reviewed.
Best public speakers evaluate their performance to improve.
Write down what you did best, what you could improve and what you should stop doing after watching a recording of yourself. Seeing yourself can be unsettling. This is how you improve.
5. Remove text from slides
"Humans can't read and comprehend screen text while listening to a speaker. Therefore, lots of text and long, complete sentences are bad, bad, bad.” —Communications expert Garr Reynolds
Presentation slides shouldn't have too much text. 100-slide presentations bore the audience. Your slides should preview what you'll say to the audience.
Use slides to emphasize your main point visually.
If you add text, use at least 40-point font. Your slides shouldn't require squinting to read. You want people to watch you, not your slides.
6. Body language
"Body language is powerful." We had body language before speech, and 80% of a conversation is read through the body, not the words." — Dancer, writer, and broadcaster Deborah Bull
Nonverbal communication dominates. Our bodies speak louder than words. Don't fidget, rock, lean, or pace.
Relax your body to communicate clearly and without distraction through nonverbal cues. Public speaking anxiety can cause tense body language.
Maintain posture and eye contact. Don’t put your hand in your pockets, cross your arms, or stare at your notes. Make purposeful hand gestures that match what you're saying.
7. Beginning/ending Strong
Beginning and end are memorable. Your presentation must start strong and end strongly. To engage your audience, don't sound robotic.
Begin with a story, stat, or quote. Conclude with a summary of key points. Focus on how you will start and end your speech.
You should memorize your presentation's opening and closing. Memorize something naturally. Excellent presentations start and end strong because people won't remember the middle.
Bringing It All Together
Seven simple yet powerful ways to improve public speaking. Know your audience, study others, prepare and rehearse, record yourself, remove as much text as possible from slides, and start and end strong.
Follow these tips to improve your speaking and audience communication. Prepare, practice, and learn from great speakers to reduce your fear of public speaking.
"Speaking to one person or a thousand is public speaking." — Vocal coach Roger Love

Michael Hunter, MD
3 years ago
5 Drugs That May Increase Your Risk of Dementia

While our genes can't be changed easily, you can avoid some dementia risk factors. Today we discuss dementia and five drugs that may increase risk.
Memory loss appears to come with age, but we're not talking about forgetfulness. Sometimes losing your car keys isn't an indication of dementia. Dementia impairs the capacity to think, remember, or make judgments. Dementia hinders daily tasks.
Alzheimers is the most common dementia. Dementia is not normal aging, unlike forgetfulness. Aging increases the risk of Alzheimer's and other dementias. A family history of the illness increases your risk, according to the Mayo Clinic (USA).
Given that our genes are difficult to change (I won't get into epigenetics), what are some avoidable dementia risk factors? Certain drugs may cause cognitive deterioration.
Today we look at four drugs that may cause cognitive decline.
Dementia and benzodiazepines
Benzodiazepine sedatives increase brain GABA levels. Example benzodiazepines:
Diazepam (Valium) (Valium)
Alprazolam (Xanax) (Xanax)
Clonazepam (Klonopin) (Klonopin)
Addiction and overdose are benzodiazepine risks. Yes! These medications don't raise dementia risk.
USC study: Benzodiazepines don't increase dementia risk in older adults.
Benzodiazepines can produce short- and long-term amnesia. This memory loss hinders memory formation. Extreme cases can permanently impair learning and memory. Anterograde amnesia is uncommon.
2. Statins and dementia
Statins reduce cholesterol. They prevent a cholesterol-making chemical. Examples:
Atorvastatin (Lipitor) (Lipitor)
Fluvastatin (Lescol XL) (Lescol XL)
Lovastatin (Altoprev) (Altoprev)
Pitavastatin (Livalo, Zypitamag) (Livalo, Zypitamag)
Pravastatin (Pravachol) (Pravachol)
Rosuvastatin (Crestor, Ezallor) (Crestor, Ezallor)
Simvastatin (Zocor) (Zocor)
This finding is contentious. Harvard's Brigham and Womens Hospital's Dr. Joann Manson says:
“I think that the relationship between statins and cognitive function remains controversial. There’s still not a clear conclusion whether they help to prevent dementia or Alzheimer’s disease, have neutral effects, or increase risk.”
This one's off the dementia list.
3. Dementia and anticholinergic drugs
Anticholinergic drugs treat many conditions, including urine incontinence. Drugs inhibit acetylcholine (a brain chemical that helps send messages between cells). Acetylcholine blockers cause drowsiness, disorientation, and memory loss.
First-generation antihistamines, tricyclic antidepressants, and overactive bladder antimuscarinics are common anticholinergics among the elderly.
Anticholinergic drugs may cause dementia. One study found that taking anticholinergics for three years or more increased the risk of dementia by 1.54 times compared to three months or less. After stopping the medicine, the danger may continue.
4. Drugs for Parkinson's disease and dementia
Cleveland Clinic (USA) on Parkinson's:
Parkinson's disease causes age-related brain degeneration. It causes delayed movements, tremors, and balance issues. Some are inherited, but most are unknown. There are various treatment options, but no cure.
Parkinson's medications can cause memory loss, confusion, delusions, and obsessive behaviors. The drug's effects on dopamine cause these issues.
A 2019 JAMA Internal Medicine study found powerful anticholinergic medications enhance dementia risk.
Those who took anticholinergics had a 1.5 times higher chance of dementia. Individuals taking antidepressants, antipsychotic drugs, anti-Parkinson’s drugs, overactive bladder drugs, and anti-epileptic drugs had the greatest risk of dementia.
Anticholinergic medicines can lessen Parkinson's-related tremors, but they slow cognitive ability. Anticholinergics can cause disorientation and hallucinations in those over 70.
5. Antiepileptic drugs and dementia
The risk of dementia from anti-seizure drugs varies with drugs. Levetiracetam (Keppra) improves Alzheimer's cognition.
One study linked different anti-seizure medications to dementia. Anti-epileptic medicines increased the risk of Alzheimer's disease by 1.15 times in the Finnish sample and 1.3 times in the German population. Depakote, Topamax are drugs.