

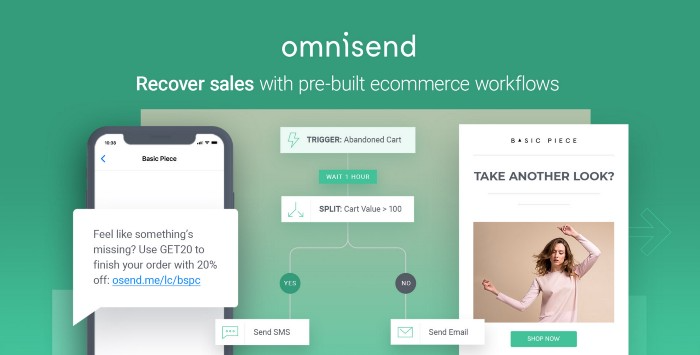
More on Productivity

Leonardo Castorina
3 years ago
How to Use Obsidian to Boost Research Productivity
Tools for managing your PhD projects, reading lists, notes, and inspiration.
As a researcher, you have to know everything. But knowledge is useless if it cannot be accessed quickly. An easy-to-use method of archiving information makes taking notes effortless and enjoyable.
As a PhD student in Artificial Intelligence, I use Obsidian (https://obsidian.md) to manage my knowledge.
The article has three parts:
- What is a note, how to organize notes, tags, folders, and links? This section is tool-agnostic, so you can use most of these ideas with any note-taking app.
- Instructions for using Obsidian, managing notes, reading lists, and useful plugins. This section demonstrates how I use Obsidian, my preferred knowledge management tool.
- Workflows: How to use Zotero to take notes from papers, manage multiple projects' notes, create MOCs with Dataview, and more. This section explains how to use Obsidian to solve common scientific problems and manage/maintain your knowledge effectively.
This list is not perfect or complete, but it is my current solution to problems I've encountered during my PhD. Please leave additional comments or contact me if you have any feedback. I'll try to update this article.
Throughout the article, I'll refer to your digital library as your "Obsidian Vault" or "Zettelkasten".
Other useful resources are listed at the end of the article.
1. Philosophy: Taking and organizing notes
Carl Sagan: “To make an apple pie from scratch, you must first create the universe.”
Before diving into Obsidian, let's establish a Personal Knowledge Management System and a Zettelkasten. You can skip to Section 2 if you already know these terms.
Niklas Luhmann, a prolific sociologist who wrote 400 papers and 70 books, inspired this section and much of Zettelkasten. Zettelkasten means “slip box” (or library in this article). His Zettlekasten had around 90000 physical notes, which can be found here.
There are now many tools available to help with this process. Obsidian's website has a good introduction section: https://publish.obsidian.md/hub/
Notes
We'll start with "What is a note?" Although it may seem trivial, the answer depends on the topic or your note-taking style. The idea is that a note is as “atomic” (i.e. You should read the note and get the idea right away.
The resolution of your notes depends on their detail. Deep Learning, for example, could be a general description of Neural Networks, with a few notes on the various architectures (eg. Recurrent Neural Networks, Convolutional Neural Networks etc..).
Limiting length and detail is a good rule of thumb. If you need more detail in a specific section of this note, break it up into smaller notes. Deep Learning now has three notes:
- Deep Learning
- Recurrent Neural Networks
- Convolutional Neural Networks
Repeat this step as needed until you achieve the desired granularity. You might want to put these notes in a “Neural Networks” folder because they are all about the same thing. But there's a better way:
#Tags and [[Links]] over /Folders/
The main issue with folders is that they are not flexible and assume that all notes in the folder belong to a single category. This makes it difficult to make connections between topics.
Deep Learning has been used to predict protein structure (AlphaFold) and classify images (ImageNet). Imagine a folder structure like this:
- /Proteins/
- Protein Folding
- /Deep Learning/
- /Proteins/
Your notes about Protein Folding and Convolutional Neural Networks will be separate, and you won't be able to find them in the same folder.
This can be solved in several ways. The most common one is to use tags rather than folders. A note can be grouped with multiple topics this way. Obsidian tags can also be nested (have subtags).
You can also link two notes together. You can build your “Knowledge Graph” in Obsidian and other note-taking apps like Obsidian.
My Knowledge Graph. Green: Biology, Red: Machine Learning, Yellow: Autoencoders, Blue: Graphs, Brown: Tags.
My Knowledge Graph and the note “Backrpropagation” and its links.
Backpropagation note and all its links
Why use Folders?
Folders help organize your vault as it grows. The main suggestion is to have few folders that "weakly" collect groups of notes or better yet, notes from different sources.
Among my Zettelkasten folders are:
My Zettelkasten's 5 folders
They usually gather data from various sources:
MOC: Map of Contents for the Zettelkasten.
Projects: Contains one note for each side-project of my PhD where I log my progress and ideas. Notes are linked to these.
Bio and ML: These two are the main content of my Zettelkasten and could theoretically be combined.
Papers: All my scientific paper notes go here. A bibliography links the notes. Zotero .bib file
Books: I make a note for each book I read, which I then split into multiple notes.
Keeping images separate from other files can help keep your main folders clean.
I will elaborate on these in the Workflow Section.
My general recommendation is to use tags and links instead of folders.
Maps of Content (MOC)
Making Tables of Contents is a good solution (MOCs).
These are notes that "signposts" your Zettelkasten library, directing you to the right type of notes. It can link to other notes based on common tags. This is usually done with a title, then your notes related to that title. As an example:
An example of a Machine Learning MOC generated with Dataview.
As shown above, my Machine Learning MOC begins with the basics. Then it's on to Variational Auto-Encoders. Not only does this save time, but it also saves scrolling through the tag search section.
So I keep MOCs at the top of my library so I can quickly find information and see my library. These MOCs are generated automatically using an Obsidian Plugin called Dataview (https://github.com/blacksmithgu/obsidian-dataview).
Ideally, MOCs could be expanded to include more information about the notes, their status, and what's left to do. In the absence of this, Dataview does a fantastic job at creating a good structure for your notes.
In the absence of this, Dataview does a fantastic job at creating a good structure for your notes.
2. Tools: Knowing Obsidian
Obsidian is my preferred tool because it is free, all notes are stored in Markdown format, and each panel can be dragged and dropped. You can get it here: https://obsidian.md/
Obsidian interface.
Obsidian is highly customizable, so here is my preferred interface:
The theme is customized from https://github.com/colineckert/obsidian-things
Alternatively, each panel can be collapsed, moved, or removed as desired. To open a panel later, click on the vertical "..." (bottom left of the note panel).
My interface is organized as follows:
How my Obsidian Interface is organized.
Folders/Search:
This is where I keep all relevant folders. I usually use the MOC note to navigate, but sometimes I use the search button to find a note.
Tags:
I use nested tags and look into each one to find specific notes to link.
cMenu:
Easy-to-use menu plugin cMenu (https://github.com/chetachiezikeuzor/cMenu-Plugin)
Global Graph:
The global graph shows all your notes (linked and unlinked). Linked notes will appear closer together. Zoom in to read each note's title. It's a bit overwhelming at first, but as your library grows, you get used to the positions and start thinking of new connections between notes.
Local Graph:
Your current note will be shown in relation to other linked notes in your library. When needed, you can quickly jump to another link and back to the current note.
Links:
Finally, an outline panel and the plugin Obsidian Power Search (https://github.com/aviral-batra/obsidian-power-search) allow me to search my vault by highlighting text.
Start using the tool and worry about panel positioning later. I encourage you to find the best use-case for your library.
Plugins
An additional benefit of using Obsidian is the large plugin library. I use several (Calendar, Citations, Dataview, Templater, Admonition):
Obsidian Calendar Plugin: https://github.com/liamcain
It organizes your notes on a calendar. This is ideal for meeting notes or keeping a journal.
Calendar addon from hans/obsidian-citation-plugin
Obsidian Citation Plugin: https://github.com/hans/
Allows you to cite papers from a.bib file. You can also customize your notes (eg. Title, Authors, Abstract etc..)
Plugin citation from hans/obsidian-citation-plugin
Obsidian Dataview: https://github.com/blacksmithgu/
A powerful plugin that allows you to query your library as a database and generate content automatically. See the MOC section for an example.
Allows you to create notes with specific templates like dates, tags, and headings.
Templater. Obsidian Admonition: https://github.com/valentine195/obsidian-admonition
Blocks allow you to organize your notes.
Plugin warning. Obsidian Admonition (valentine195)
There are many more, but this list should get you started.
3. Workflows: Cool stuff
Here are a few of my workflows for using obsidian for scientific research. This is a list of resources I've found useful for my use-cases. I'll outline and describe them briefly so you can skim them quickly.
3.1 Using Templates to Structure Notes
3.2 Free Note Syncing (Laptop, Phone, Tablet)
3.3 Zotero/Mendeley/JabRef -> Obsidian — Managing Reading Lists
3.4 Projects and Lab Books
3.5 Private Encrypted Diary
3.1 Using Templates to Structure Notes
Plugins: Templater and Dataview (optional).
To take effective notes, you must first make adding new notes as easy as possible. Templates can save you time and give your notes a consistent structure. As an example:
An example of a note using a template.
### [[YOUR MOC]]
# Note Title of your note
**Tags**::
**Links**::
The top line links to your knowledge base's Map of Content (MOC) (see previous sections). After the title, I add tags (and a link between the note and the tag) and links to related notes.
To quickly identify all notes that need to be expanded, I add the tag “#todo”. In the “TODO:” section, I list the tasks within the note.
The rest are notes on the topic.
Templater can help you create these templates. For new books, I use the following template:
### [[Books MOC]]
# Title
**Author**::
**Date::
**Tags::
**Links::
A book template example.
Using a simple query, I can hook Dataview to it.
dataview
table author as Author, date as “Date Finished”, tags as “Tags”, grade as “Grade”
from “4. Books”
SORT grade DESCENDING
using Dataview to query templates.
3.2 Free Note Syncing (Laptop, Phone, Tablet)
No plugins used.
One of my favorite features of Obsidian is the library's self-contained and portable format. Your folder contains everything (plugins included).
Ordinary folders and documents are available as well. There is also a “.obsidian” folder. This contains all your plugins and settings, so you can use it on other devices.
So you can use Google Drive, iCloud, or Dropbox for free as long as you sync your folder (note: your folder should be in your Cloud Folder).
For my iOS and macOS work, I prefer iCloud. You can also use the paid service Obsidian Sync.
3.3 Obsidian — Managing Reading Lists and Notes in Zotero/Mendeley/JabRef
Plugins: Quotes (required).
3.3 Zotero/Mendeley/JabRef -> Obsidian — Taking Notes and Managing Reading Lists of Scientific Papers
My preferred reference manager is Zotero, but this workflow should work with any reference manager that produces a .bib file. This file is exported to my cloud folder so I can access it from any platform.
My Zotero library is tagged as follows:
My reference manager's tags
For readings, I usually search for the tags “!!!” and “To-Read” and select a paper. Annotate the paper next (either on PDF using GoodNotes or on physical paper).
Then I make a paper page using a template in the Citations plugin settings:
An example of my citations template.
Create a new note, open the command list with CMD/CTRL + P, and find the Citations “Insert literature note content in the current pane” to see this lovely view.
Citation generated by the article https://doi.org/10.1101/2022.01.24.22269144
You can then convert your notes to digital. I found that transcribing helped me retain information better.
3.4 Projects and Lab Books
Plugins: Tweaker (required).
PhD students offering advice on thesis writing are common (read as regret). I started asking them what they would have done differently or earlier.
“Deep stuff Leo,” one person said. So my main issue is basic organization, losing track of my tasks and the reasons for them.
As a result, I'd go on other experiments that didn't make sense, and have to reverse engineer my logic for thesis writing. - PhD student now wise Postdoc
Time management requires planning. Keeping track of multiple projects and lab books is difficult during a PhD. How I deal with it:
- One folder for all my projects
- One file for each project
I use a template to create each project
### [[Projects MOC]]
# <% tp.file.title %>
**Tags**::
**Links**::
**URL**::
**Project Description**::## Notes:
### <% tp.file.last_modified_date(“dddd Do MMMM YYYY”) %>
#### Done:
#### TODO:
#### Notes
You can insert a template into a new note with CMD + P and looking for the Templater option.
I then keep adding new days with another template:
### <% tp.file.last_modified_date("dddd Do MMMM YYYY") %>
#### Done:
#### TODO:
#### Notes:
This way you can keep adding days to your project and update with reasonings and things you still have to do and have done. An example below:
Example of project note with timestamped notes.
3.5 Private Encrypted Diary
This is one of my favorite Obsidian uses.
Mini Diary's interface has long frustrated me. After the author archived the project, I looked for a replacement. I had two demands:
- It had to be private, and nobody had to be able to read the entries.
- Cloud syncing was required for editing on multiple devices.
Then I learned about encrypting the Obsidian folder. Then decrypt and open the folder with Obsidian. Sync the folder as usual.
Use CryptoMator (https://cryptomator.org/). Create an encrypted folder in Cryptomator for your Obsidian vault, set a password, and let it do the rest.
If you need a step-by-step video guide, here it is:
Conclusion
So, I hope this was helpful!
In the first section of the article, we discussed notes and note-taking techniques. We discussed when to use tags and links over folders and when to break up larger notes.
Then we learned about Obsidian, its interface, and some useful plugins like Citations for citing papers and Templater for creating note templates.
Finally, we discussed workflows and how to use Zotero to take notes from scientific papers, as well as managing Lab Books and Private Encrypted Diaries.
Thanks for reading and commenting :)
Read original post here

Jari Roomer
2 years ago
Three Simple Daily Practices That Will Immediately Double Your Output
Most productive people are habitual.

Early in the day, do important tasks.
In his best-selling book Eat That Frog, Brian Tracy advised starting the day with your hardest, most important activity.
Most individuals work best in the morning. Energy and willpower peak then.
Mornings are also ideal for memory, focus, and problem-solving.
Thus, the morning is ideal for your hardest chores.
It makes sense to do these things during your peak performance hours.
Additionally, your morning sets the tone for the day. According to Brian Tracy, the first hour of the workday steers the remainder.
After doing your most critical chores, you may feel accomplished, confident, and motivated for the remainder of the day, which boosts productivity.
Develop Your Essentialism
In Essentialism, Greg McKeown claims that trying to be everything to everyone leads to mediocrity and tiredness.
You'll either burn out, be spread too thin, or compromise your ideals.
Greg McKeown advises Essentialism:
Clarify what’s truly important in your life and eliminate the rest.
Eliminating non-essential duties, activities, and commitments frees up time and energy for what matters most.
According to Greg McKeown, Essentialists live by design, not default.
You'll be happier and more productive if you follow your essentials.
Follow these three steps to live more essentialist.
Prioritize Your Tasks First
What matters most clarifies what matters less. List your most significant aims and values.
The clearer your priorities, the more you can focus on them.
On Essentialism, McKeown wrote, The ultimate form of effectiveness is the ability to deliberately invest our time and energy in the few things that matter most.
#2: Set Your Priorities in Order
Prioritize your priorities, not simply know them.
“If you don’t prioritize your life, someone else will.” — Greg McKeown
Planning each day and allocating enough time for your priorities is the best method to become more purposeful.
#3: Practice saying "no"
If a request or demand conflicts with your aims or principles, you must learn to say no.
Saying no frees up space for our priorities.
Place Sleep Above All Else
Many believe they must forego sleep to be more productive. This is false.
A productive day starts with a good night's sleep.
Matthew Walker (Why We Sleep) says:
“Getting a good night’s sleep can improve cognitive performance, creativity, and overall productivity.”
Sleep helps us learn, remember, and repair.
Unfortunately, 35% of people don't receive the recommended 79 hours of sleep per night.
Sleep deprivation can cause:
increased risk of diabetes, heart disease, stroke, and obesity
Depression, stress, and anxiety risk are all on the rise.
decrease in general contentment
decline in cognitive function
To live an ideal, productive, and healthy life, you must prioritize sleep.
Follow these six sleep optimization strategies to obtain enough sleep:
Establish a nightly ritual to relax and prepare for sleep.
Avoid using screens an hour before bed because the blue light they emit disrupts the generation of melatonin, a necessary hormone for sleep.
Maintain a regular sleep schedule to control your body's biological clock (and optimizes melatonin production)
Create a peaceful, dark, and cool sleeping environment.
Limit your intake of sweets and caffeine (especially in the hours leading up to bedtime)
Regular exercise (but not right before you go to bed, because your body temperature will be too high)
Sleep is one of the best ways to boost productivity.
Sleep is crucial, says Matthew Walker. It's the key to good health and longevity.

Jano le Roux
3 years ago
Never Heard Of: The Apple Of Email Marketing Tools
Unlimited everything for $19 monthly!?
Even with pretty words, no one wants to read an ugly email.
Not Gen Z
Not Millennials
Not Gen X
Not Boomers
I am a minimalist.
I like Mozart. I like avos. I love Apple.
When I hear seamlessly, effortlessly, or Apple's new adverb fluidly, my toes curl.
No email marketing tool gave me that feeling.
As a marketing consultant helping high-growth brands create marketing that doesn't feel like marketing, I've worked with every email marketing platform imaginable, including that naughty monkey and the expensive platform whose sales teams don't stop calling.
Most email marketing platforms are flawed.
They are overpriced.
They use dreadful templates.
They employ a poor visual designer.
The user experience there is awful.
Too many useless buttons are present. (Similar to the TV remote!)
I may have finally found the perfect email marketing tool. It creates strong flows. It helps me focus on storytelling.
It’s called Flodesk.
It’s effortless. It’s seamless. It’s fluid.
Here’s why it excites me.
Unlimited everything for $19 per month
Sends unlimited. Emails unlimited. Signups unlimited.
Most email platforms penalize success.
Pay for performance?
$87 for 10k contacts
$605 for 100K contacts
$1,300+ for 200K contacts
In the 1990s, this made sense, but not now. It reminds me of when ISPs capped internet usage at 5 GB per month.
Flodesk made unlimited email for a low price a reality. Affordable, attractive email marketing isn't just for big companies.
Flodesk doesn't penalize you for growing your list. Price stays the same as lists grow.
Flodesk plans cost $38 per month, but I'll give you a 30-day trial for $19.
Amazingly strong flows
Foster different people's flows.
Email marketing isn't one-size-fits-all.
Different times require different emails.
People don't open emails because they're irrelevant, in my experience. A colder audience needs a nurturing sequence.
Flodesk automates your email funnels so top-funnel prospects fall in love with your brand and values before mid- and bottom-funnel email flows nudge them to take action.
I wish I could save more custom audience fields to further customize the experience.
Dynamic editor
Easy. Effortless.
Flodesk's editor is Apple-like.
You understand how it works almost instantly.
Like many Apple products, it's intentionally limited. No distractions. You can focus on emotional email writing.
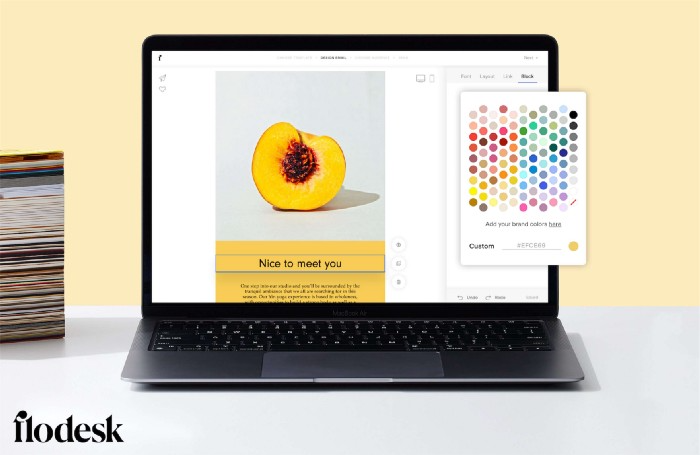
Flodesk's inability to add inline HTML to emails is my biggest issue with larger projects. I wish I could upload HTML emails.
Simple sign-up procedures
Dream up joining.
I like how easy it is to create conversion-focused landing pages. Linkly lets you easily create 5 landing pages and A/B test messaging.
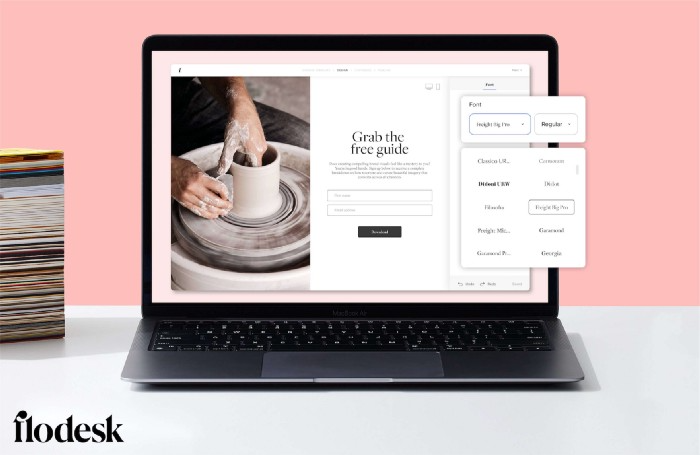
I like that you can use signup forms to ask people what they're interested in so they get relevant emails instead of mindless mass emails nobody opens.
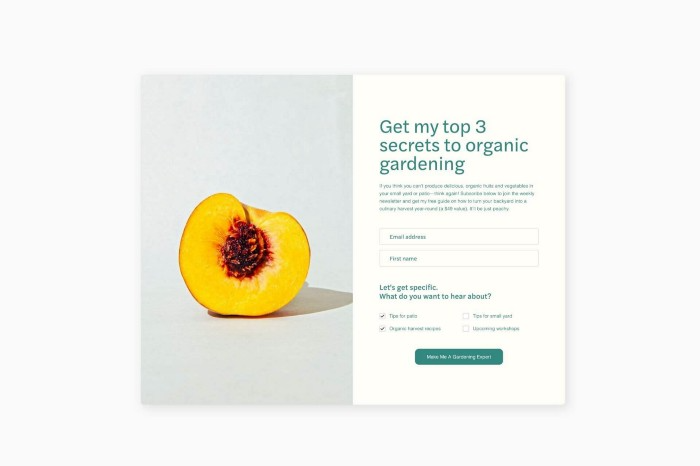
I love how easy it is to embed in-line on a website.
Wonderful designer templates
Beautiful, connecting emails.
Flodesk has calm email templates. My designer's eye felt at rest when I received plain text emails with big impacts.
As a typography nerd, I love Flodesk's handpicked designer fonts. It gives emails a designer feel that is hard to replicate on other platforms without coding and custom font licenses.
Small adjustments can have a big impact
Details matter.
Flodesk remembers your brand colors. Flodesk automatically adds your logo and social handles to emails after signup.
Flodesk uses Zapier. This lets you send emails based on a user's action.
A bad live chat can trigger a series of emails to win back a customer.
Flodesk isn't for everyone.
Flodesk is great for Apple users like me.
You might also like

Alison Randel
3 years ago
Raising the Bar on Your 1:1s

Managers spend much time in 1:1s. Most team members meet with supervisors regularly. 1:1s can help create relationships and tackle tough topics. Few appreciate the 1:1 format's potential. Most of the time, that potential is spent on small talk, surface-level updates, and ranting (Ugh, the marketing team isn’t stepping up the way I want them to).
What if you used that time to have deeper conversations and important insights? What if change was easy?
This post introduces a new 1:1 format to help you dive deeper, faster, and develop genuine relationships without losing impact.
A 1:1 is a chat, you would assume. Why use structure to talk to a coworker? Go! I know how to talk to people. I can write. I've always written. Also, This article was edited by Zoe.
Before you discard something, ask yourself if there's a good reason not to try anything new. Is the 1:1 only a talk, or do you want extra benefits? Try the steps below to discover more.
I. Reflection (5 minutes)
Context-free, broad comments waste time and are useless. Instead, give team members 5 minutes to write these 3 prompts.
What's effective?
What is decent but could be improved?
What is broken or missing?
Why these? They encourage people to be honest about all their experiences. Answering these questions helps people realize something isn't working. These prompts let people consider what's working.
Why take notes? Because you get more in less time. Will you feel awkward sitting quietly while your coworker writes? Probably. Persevere. Multi-task. Take a break from your afternoon meeting marathon. Any awkwardness will pay off.
What happens? After a few minutes of light conversation, create a template like the one given here and have team members fill in their replies. You can pre-share the template (with the caveat that this isn’t meant to take much prep time). Do this with your coworker: Answer the prompts. Everyone can benefit from pondering and obtaining guidance.
This step's output.

Part II: Talk (10-20 minutes)
Most individuals can explain what they see but not what's behind an answer. You don't like a meeting. Why not? Marketing partnership is difficult. What makes working with them difficult? I don't recommend slandering coworkers. Consider how your meetings, decisions, and priorities make work harder. The excellent stuff too. You want to know what's humming so you can reproduce the magic.
First, recognize some facts.
Real power dynamics exist. To encourage individuals to be honest, you must provide a safe environment and extend clear invites. Even then, it may take a few 1:1s for someone to feel secure enough to go there in person. It is part of your responsibility to admit that it is normal.
Curiosity and self-disclosure are crucial. Most leaders have received training to present themselves as the authorities. However, you will both benefit more from the dialogue if you can be open and honest about your personal experience, ask questions out of real curiosity, and acknowledge the pertinent sacrifices you're making as a leader.
Honesty without bias is difficult and important. Due to concern for the feelings of others, people frequently hold back. Or if they do point anything out, they do so in a critical manner. The key is to be open and unapologetic about what you observe while not presuming that your viewpoint is correct and that of the other person is incorrect.
Let's go into some prompts (based on genuine conversations):
“What do you notice across your answers?”
“What about the way you/we/they do X, Y, or Z is working well?”
“ Will you say more about item X in ‘What’s not working?’”
“I’m surprised there isn’t anything about Z. Why is that?”
“All of us tend to play some role in maintaining certain patterns. How might you/we be playing a role in this pattern persisting?”
“How might the way we meet, make decisions, or collaborate play a role in what’s currently happening?”
Consider the preceding example. What about the Monday meeting isn't working? Why? or What about the way we work with marketing makes collaboration harder? Remember to share your honest observations!
Third section: observe patterns (10-15 minutes)
Leaders desire to empower their people but don't know how. We also have many preconceptions about what empowerment means to us and how it works. The next phase in this 1:1 format will assist you and your team member comprehend team power and empowerment. This understanding can help you support and shift your team member's behavior, especially where you disagree.
How to? After discussing the stated responses, ask each team member what they can control, influence, and not control. Mark their replies. You can do the same, adding colors where you disagree.
This step's output.

Next, consider the color constellation. Discuss these questions:
Is one color much more prevalent than the other? Why, if so?
Are the colors for the "what's working," "what's fine," and "what's not working" categories clearly distinct? Why, if so?
Do you have any disagreements? If yes, specifically where does your viewpoint differ? What activities do you object to? (Remember, there is no right or wrong in this. Give explicit details and ask questions with curiosity.)
Example: Based on the colors, you can ask, Is the marketing meeting's quality beyond your control? Were our marketing partners consulted? Are there any parts of team decisions we can control? We can't control people, but have we explored another decision-making method? How can we collaborate and generate governance-related information to reduce work, even if the requirement for prep can't be eliminated?
Consider the top one or two topics for this conversation. No 1:1 can cover everything, and that's OK. Focus on the present.
Part IV: Determine the next step (5 minutes)
Last, examine what this conversation means for you and your team member. It's easy to think we know the next moves when we don't.
Like what? You and your teammate answer these questions.
What does this signify moving ahead for me? What can I do to change this? Make requests, for instance, and see how people respond before thinking they won't be responsive.
What demands do I have on other people or my partners? What should I do first? E.g. Make a suggestion to marketing that we hold a monthly retrospective so we can address problems and exchange input more frequently. Include it on the meeting's agenda for next Monday.
Close the 1:1 by sharing what you noticed about the chat. Observations? Learn anything?
Yourself, you, and the 1:1
As a leader, you either reinforce or disrupt habits. Try this template if you desire greater ownership, empowerment, or creativity. Consider how you affect surrounding dynamics. How can you expect others to try something new in high-stakes scenarios, like meetings with cross-functional partners or senior stakeholders, if you won't? How can you expect deep thought and relationship if you don't encourage it in 1:1s? What pattern could this new format disrupt or reinforce?
Fight reluctance. First attempts won't be ideal, and that's OK. You'll only learn by trying.

Nik Nicholas
3 years ago
A simple go-to-market formula

“Poor distribution, not poor goods, is the main reason for failure” — Peter Thiel.
Here's an easy way to conceptualize "go-to-market" for your distribution plan.
One equation captures the concept:
Distribution = Ecosystem Participants + Incentives
Draw your customers' ecosystem. Set aside your goods and consider your consumer's environment. Who do they deal with daily?
First, list each participant. You want an exhaustive list, but here are some broad categories.
In-person media services
Websites
Events\Networks
Financial education and banking
Shops
Staff
Advertisers
Twitter influencers
Draw influence arrows. Who's affected? I'm not just talking about Instagram selfie-posters. Who has access to your consumer and could promote your product if motivated?
The thicker the arrow, the stronger the relationship. Include more "influencers" if needed. Customer ecosystems are complex.
3. Incentivize ecosystem players. “Show me the incentive and I will show you the result.“, says Warren Buffet's business partner Charlie Munger.
Strong distribution strategies encourage others to promote your product to your target market by incentivizing the most prominent players. Incentives can be financial or non-financial.
Financial rewards
Usually, there's money. If you pay Facebook, they'll run your ad. Salespeople close deals for commission. Giving customers bonus credits will encourage referrals.
Most businesses underuse non-financial incentives.
Non-cash incentives
Motivate key influencers without spending money to expand quickly and cheaply. What can you give a client-connector for free?
Here are some ideas:
Are there any other features or services available?
Titles or status? Tinder paid college "ambassadors" for parties to promote its dating service.
Can I get early/free access? Facebook gave a select group of developers "exclusive" early access to their AR platform.
Are you a good host? Pharell performed at YPlan's New York launch party.
Distribution? Apple's iPod earphones are white so others can see them.
Have an interesting story? PR rewards journalists by giving them a compelling story to boost page views.
Prioritize distribution.
More time spent on distribution means more room in your product design and business plan. Once you've identified the key players in your customer's ecosystem, talk to them.
Money isn't your only resource. Creative non-monetary incentives may be more effective and scalable. Give people something useful and easy to deliver.

Tora Northman
3 years ago
Pixelmon NFTs are so bad, they are almost good!
Bored Apes prices continue to rise, HAPEBEAST launches, Invisible Friends hype continues to grow. Sadly, not all projects are as successful.
Of course, there are many factors to consider when buying an NFT. Is the project a scam? Will the reveal derail the project? Possibly, but when Pixelmon first teased its launch, it generated a lot of buzz.
With a primary sale mint price of 3 ETH ($8,100 USD), it started as an expensive project, with plenty of fans willing to invest in what was sold as a game. After it was revealed, it fell rapidly.
Why? It was overpromised and under delivered.
According to the project's creator[^1], the funds generated will be used to develop the artwork. "The Pixelmon reveal was wrong. This is what our Pixelmon look like in-game. "Despite the fud, I will not go anywhere," he wrote on Twitter. The goal remains. The funds will still be used to build our game. I will finish this project."
The project raised $70 million USD, but the NFTs buyers received were not the project's original teasers. Some call it "the worst NFT project ever," while others call it a complete scam.
But there's hope for some buyers. Kevin emerged from the ashes as the project was roasted over the fire.
A Minecraft character meets Salad Fingers - that's Kevin. He's a frog-like creature whose reveal was such a terrible NFT that it became part of history – and a meme.
If you're laughing at people paying $8K for a silly pixelated image, you might need to take it back. Precisely because of this, lucky holders who minted Kevin have been able to sell the now-memed NFT for over 8 ETH (around $24,000 USD), with some currently listed for 100 ETH.
Of course, Twitter has been awash in memes mocking those who invested in the project, because what else can you do when so many people lose money?
It's still unclear if the NFT project is a scam, but the team behind it was hired on Upwork. There's still hope for redemption, but Kevin's rise to fame appears to be the only positive outcome so far.
[^1] This is not the first time the creator (A 20-yo New Zealanders) has sought money via an online platform and had people claiming he under-delivered. He raised $74,000 on Kickstarter for a card game called Psycho Chicken. There are hundreds of comments on the Kickstarter project saying they haven't received the product and pleading for a refund or an update.