


More on Productivity

Jari Roomer
3 years ago
Three Simple Daily Practices That Will Immediately Double Your Output
Most productive people are habitual.

Early in the day, do important tasks.
In his best-selling book Eat That Frog, Brian Tracy advised starting the day with your hardest, most important activity.
Most individuals work best in the morning. Energy and willpower peak then.
Mornings are also ideal for memory, focus, and problem-solving.
Thus, the morning is ideal for your hardest chores.
It makes sense to do these things during your peak performance hours.
Additionally, your morning sets the tone for the day. According to Brian Tracy, the first hour of the workday steers the remainder.
After doing your most critical chores, you may feel accomplished, confident, and motivated for the remainder of the day, which boosts productivity.
Develop Your Essentialism
In Essentialism, Greg McKeown claims that trying to be everything to everyone leads to mediocrity and tiredness.
You'll either burn out, be spread too thin, or compromise your ideals.
Greg McKeown advises Essentialism:
Clarify what’s truly important in your life and eliminate the rest.
Eliminating non-essential duties, activities, and commitments frees up time and energy for what matters most.
According to Greg McKeown, Essentialists live by design, not default.
You'll be happier and more productive if you follow your essentials.
Follow these three steps to live more essentialist.
Prioritize Your Tasks First
What matters most clarifies what matters less. List your most significant aims and values.
The clearer your priorities, the more you can focus on them.
On Essentialism, McKeown wrote, The ultimate form of effectiveness is the ability to deliberately invest our time and energy in the few things that matter most.
#2: Set Your Priorities in Order
Prioritize your priorities, not simply know them.
“If you don’t prioritize your life, someone else will.” — Greg McKeown
Planning each day and allocating enough time for your priorities is the best method to become more purposeful.
#3: Practice saying "no"
If a request or demand conflicts with your aims or principles, you must learn to say no.
Saying no frees up space for our priorities.
Place Sleep Above All Else
Many believe they must forego sleep to be more productive. This is false.
A productive day starts with a good night's sleep.
Matthew Walker (Why We Sleep) says:
“Getting a good night’s sleep can improve cognitive performance, creativity, and overall productivity.”
Sleep helps us learn, remember, and repair.
Unfortunately, 35% of people don't receive the recommended 79 hours of sleep per night.
Sleep deprivation can cause:
increased risk of diabetes, heart disease, stroke, and obesity
Depression, stress, and anxiety risk are all on the rise.
decrease in general contentment
decline in cognitive function
To live an ideal, productive, and healthy life, you must prioritize sleep.
Follow these six sleep optimization strategies to obtain enough sleep:
Establish a nightly ritual to relax and prepare for sleep.
Avoid using screens an hour before bed because the blue light they emit disrupts the generation of melatonin, a necessary hormone for sleep.
Maintain a regular sleep schedule to control your body's biological clock (and optimizes melatonin production)
Create a peaceful, dark, and cool sleeping environment.
Limit your intake of sweets and caffeine (especially in the hours leading up to bedtime)
Regular exercise (but not right before you go to bed, because your body temperature will be too high)
Sleep is one of the best ways to boost productivity.
Sleep is crucial, says Matthew Walker. It's the key to good health and longevity.

Mickey Mellen
3 years ago
Shifting from Obsidian to Tana?

I relocated my notes database from Roam Research to Obsidian earlier this year expecting to stay there for a long. Obsidian is a terrific tool, and I explained my move in that post.
Moving everything to Tana faster than intended. Tana? Why?
Tana is just another note-taking app, but it does it differently. Three note-taking apps existed before Tana:
simple note-taking programs like Apple Notes and Google Keep.
Roam Research and Obsidian are two graph-style applications that assisted connect your notes.
You can create effective tables and charts with data-focused tools like Notion and Airtable.
Tana is the first great software I've encountered that combines graph and data notes. Google Keep will certainly remain my rapid notes app of preference. This Shu Omi video gives a good overview:
Tana handles everything I did in Obsidian with books, people, and blog entries, plus more. I can find book quotes, log my workouts, and connect my thoughts more easily. It should make writing blog entries notes easier, so we'll see.
Tana is now invite-only, but if you're interested, visit their site and sign up. As Shu noted in the video above, the product hasn't been published yet but seems quite polished.
Whether I stay with Tana or not, I'm excited to see where these apps are going and how they can benefit us all.

Ellane W
3 years ago
The Last To-Do List Template I'll Ever Need, Years in the Making
The holy grail of plain text task management is finally within reach

Plain text task management? Are you serious?? Dedicated task managers exist for a reason, you know. Sheesh.
—Oh, I know. Believe me, I know! But hear me out.
I've managed projects and tasks in plain text for more than four years. Since reorganizing my to-do list, plain text task management is within reach.
Data completely yours? One billion percent. Beef it up with coding? Be my guest.
Enter: The List
The answer? A list. That’s it!
Write down tasks. Obsidian, Notenik, Drafts, or iA Writer are good plain text note-taking apps.
List too long? Of course, it is! A large list tells you what to do. Feel the itch and friction. Then fix it.
But I want to be able to distinguish between work and personal life! List two things.
However, I need to know what should be completed first. Put those items at the top.
However, some things keep coming up, and I need to be reminded of them! Put those in your calendar and make an alarm for them.
But since individual X hasn't completed task Y, I can't proceed with this. Create a Waiting section on your list by dividing it.
But I must know what I'm supposed to be doing right now! Read your list(s). Check your calendar. Think critically.
Before I begin a new one, I remind myself that "Listory Never Repeats."
There’s no such thing as too many lists if all are needed. There is such a thing as too many lists if you make them before they’re needed. Before they complain that their previous room was small or too crowded or needed a new light.
A list that feels too long has a voice; it’s telling you what to do next.
I use one Master List. It's a control panel that tells me what to focus on short-term. If something doesn't need semi-immediate attention, it goes on my Backlog list.
Todd Lewandowski's DWTS (Done, Waiting, Top 3, Soon) performance deserves praise. His DWTS to-do list structure has transformed my plain-text task management. I didn't realize it was upside down.
This is my take on it:
D = Done
Move finished items here. If they pile up, clear them out every week or month. I have a Done Archive folder.
W = Waiting
Things seething in the background, awaiting action. Stir them occasionally so they don't burn.
T = Top 3
Three priorities. Personal comes first, then work. There will always be a top 3 (no more than 5) in every category. Projects, not chores, usually.
S = Soon
This part is action-oriented. It's for anything you can accomplish to finish one of the Top 3. This collection includes thoughts and project lists. The sole requirement is that they should be short-term goals.
Some of you have probably concluded this isn't for you. Please read Todd's piece before throwing out the baby. Often. You shouldn't miss a newborn.
As much as Dancing With The Stars helps me recall this method, I may try switching their order. TSWD; Drilling Tunnel Seismic? Serenity After Task?
Master List Showcase
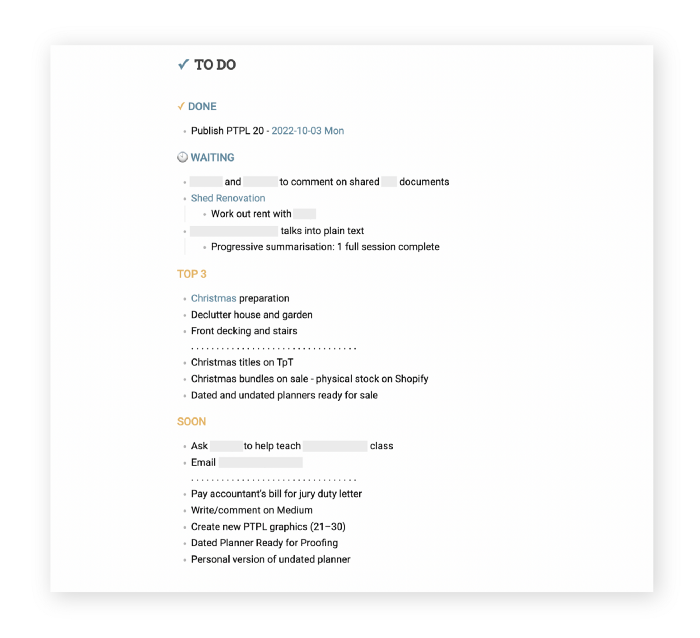
My Master List lives alone in its own file, but sometimes appears in other places. It's included in my Weekly List template. Here's a (soon-to-be-updated) demo vault of my Obsidian planning setup to download for free.
Here's the code behind my weekly screenshot:
## [[Master List - 2022|✓]] TO DO
![[Master List - 2022]]FYI, I use the Minimal Theme in Obsidian, with a few tweaks.
You may note I'm utilizing a checkmark as a link. For me, that's easier than locating the proper spot to click on the embed.
Blue headings for Done and Waiting are links. Done links to the Done Archive page and Waiting to a general waiting page.
Read my full article here.
You might also like

Jerry Keszka
3 years ago
10 Crazy Useful Free Websites No One Told You About But You Needed
The internet is a massive information resource. With so much stuff, it's easy to forget about useful websites. Here are five essential websites you may not have known about.

1. Companies.tools
Companies.tools are what successful startups employ. This website offers a curated selection of design, research, coding, support, and feedback resources. Ct has the latest app development platform and greatest client feedback method.
2. Excel Formula Bot
Excel Formula Bot can help if you forget a formula. Formula Bot uses AI to convert text instructions into Excel formulas, so you don't have to remember them.
Just tell the Bot what to do, and it will do it. Excel Formula Bot can calculate sales tax and vacation days. When you're stuck, let the Bot help.
3.TypeLit
TypeLit helps you improve your typing abilities while reading great literature.
TypeLit.io lets you type any book or dozens of preset classics. TypeLit provides real-time feedback on accuracy and speed.
Goals and progress can be tracked. Why not improve your typing and learn great literature with TypeLit?
4. Calm Schedule
Finding a meeting time that works for everyone is difficult. Personal and business calendars might be difficult to coordinate.
Synchronize your two calendars to save time and avoid problems. You may avoid searching through many calendars for conflicts and keep your personal information secret. Having one source of truth for personal and work occasions will help you never miss another appointment.
https://calmcalendar.com/
5. myNoise
myNoise makes the outside world quieter. myNoise is the right noise for a noisy office or busy street.
If you can't locate the right noise, make it. MyNoise unlocks the world. Shut out distractions. Thank your ears.
6. Synthesia
Professional videos require directors, filmmakers, editors, and animators. Now, thanks to AI, you can generate high-quality videos without video editing experience.
AI avatars are crucial. You can design a personalized avatar using a web-based software like synthesia.io. Our avatars can lip-sync in over 60 languages, so you can make worldwide videos. There's an AI avatar for every video goal.
Not free. Amazing service, though.
7. Cleaning-up-images
Have you shot a wonderful photo just to notice something in the background? You may have a beautiful headshot but wish to erase an imperfection.
Cleanup.pictures removes undesirable objects from photos. Our algorithms will eliminate the selected object.
Cleanup.pictures can help you obtain the ideal shot every time. Next time you take images, let Cleanup.pictures fix any flaws.
8. PDF24 Tools
Editing a PDF can be a pain. Most of us don't know Adobe Acrobat's functionalities. Why buy something you'll rarely use? Better options exist.
PDF24 is an online PDF editor that's free and subscription-free. Rotate, merge, split, compress, and convert PDFs in your browser. PDF24 makes document signing easy.
Upload your document, sign it (or generate a digital signature), and download it. It's easy and free. PDF24 is a free alternative to pricey PDF editing software.
9. Class Central
Finding online classes is much easier. Class Central has classes from Harvard, Stanford, Coursera, Udemy, and Google, Amazon, etc. in one spot.
Whether you want to acquire a new skill or increase your knowledge, you'll find something. New courses bring variety.
10. Rome2rio
Foreign travel offers countless transport alternatives. How do you get from A to B? It’s easy!
Rome2rio will show you the best method to get there, including which mode of transport is ideal.
Plane
Car
Train
Bus
Ferry
Driving
Shared bikes
Walking
Do you know any free, useful websites?

Francesca Furchtgott
3 years ago
Giving customers what they want or betraying the values of the brand?
A J.Crew collaboration for fashion label Eveliina Vintage is not a paradox; it is a solution.

Eveliina Vintage's capsule collection debuted yesterday at J.Crew. This J.Crew partnership stopped me in my tracks.
Eveliina Vintage sells vintage goods. Eeva Musacchia founded the shop in Finland in the 1970s. It's recognized for its one-of-a-kind slip dresses from the 1930s and 1940s.
I wondered why a vintage brand would partner with a mass shop. Fast fashion against vintage shopping? Will Eveliina Vintages customers be turned off?
But Eveliina Vintages customers don't care about sustainability. They want Eveliina's Instagram look. Eveliina Vintage collaborated with J.Crew to give customers what they wanted: more Eveliina at a lower price.
Vintage: A Fashion Option That Is Eco-Conscious
Secondhand shopping is a trendy response to quick fashion. J.Crew releases hundreds of styles annually. Waste and environmental damage have been criticized. A pair of jeans requires 1,800 gallons of water. J.Crew's limited-time deals promote more purchases. J.Crew items are likely among those Americans wear 7 times before discarding.
Consumers and designers have emphasized sustainability in recent years. Stella McCartney and Eileen Fisher are popular eco-friendly brands. They've also flocked to ThredUp and similar sites.
Gap, Levis, and Allbirds have listened to consumer requests. They promote recycling, ethical sourcing, and secondhand shopping.
Secondhand shoppers feel good about reusing and recycling clothing that might have ended up in a landfill.
Eco-conscious fashionistas shop vintage. These shoppers enjoy the thrill of the hunt (that limited-edition Chanel bag!) and showing off a unique piece (nobody will have my look!). They also reduce their environmental impact.
Is Eveliina Vintage capitalizing on an aesthetic or is it a sustainable brand?
Eveliina Vintage emphasizes environmental responsibility. Vogue's Amanda Musacchia emphasized sustainability. Amanda, founder Eeva's daughter, is a company leader.
But Eveliina's press message doesn't address sustainability, unlike Instagram. Scarcity and fame rule.
Eveliina Vintages Instagram has see-through dresses and lace-trimmed slip dresses. Celebrities and influencers are often photographed in Eveliina's apparel, which has 53,000+ followers. Vogue appreciates Eveliina's style. Multiple publications discuss Alexa Chung's Eveliina dress.
Eveliina Vintage markets its one-of-a-kind goods. It teases future content, encouraging visitors to return. Scarcity drives demand and raises clothing prices. One dress is $1,600+, but most are $500-$1,000.
The catch: Eveliina can't monetize its expanding popularity due to exorbitant prices and limited quantity. Why?
Most people struggle to pay for their clothing. But Eveliina Vintage lacks those more affordable entry-level products, in contrast to other luxury labels that sell accessories or perfume.
Many people have trouble fitting into their clothing. The bodies of most women in the past were different from those for which vintage clothing was designed. Each Eveliina dress's specific measurements are mentioned alongside it. Be careful, you can fall in love with an ill-fitting dress.
No matter how many people can afford it and fit into it, there is only one item to sell. To get the item before someone else does, those people must be on the Eveliina Vintage website as soon as it becomes available.
A Way for Eveliina Vintage to Make Money (and Expand) with J.Crew Its following
Eveliina Vintages' cooperation with J.Crew makes commercial sense.
This partnership spreads Eveliina's style. Slightly better pricing The $390 outfits have multicolored slips and gauzy cotton gowns. Sizes range from 00 to 24, which is wider than vintage racks.
Eveliina Vintage customers like the combination. Excited comments flood the brand's Instagram launch post. Nobody is mocking the 50-year-old vintage brand's fast-fashion partnership.
Vintage may be a sustainable fashion trend, but that's not why Eveliina's clients love the brand. They only care about the old look.
And that is a tale as old as fashion.

Sylvain Saurel
3 years ago
A student trader from the United States made $110 million in one month and rose to prominence on Wall Street.
Genius or lucky?

From the title, you might think I'm selling advertising for a financial influencer, a dubious trading site, or a training organization to attract clients. I'm suspicious. Better safe than sorry.
But not here.
Jake Freeman, 20, made $110 million in a month, according to the Financial Times. At 18, he ran for president. He made his name in markets, not politics. Two years later, he's Wall Street's prince. Interview requests flood the prodigy.
Jake Freeman bought 5 million Bed Bath & Beyond Group shares for $5.5 in July 2022 and sold them for $27 a month later. He thought the stock might double. Since speculation died down, he sold well. The stock fell 40.5% to 11 dollars on Friday, 19 August 2022. On August 22, 2022, it fell 16% to $9.
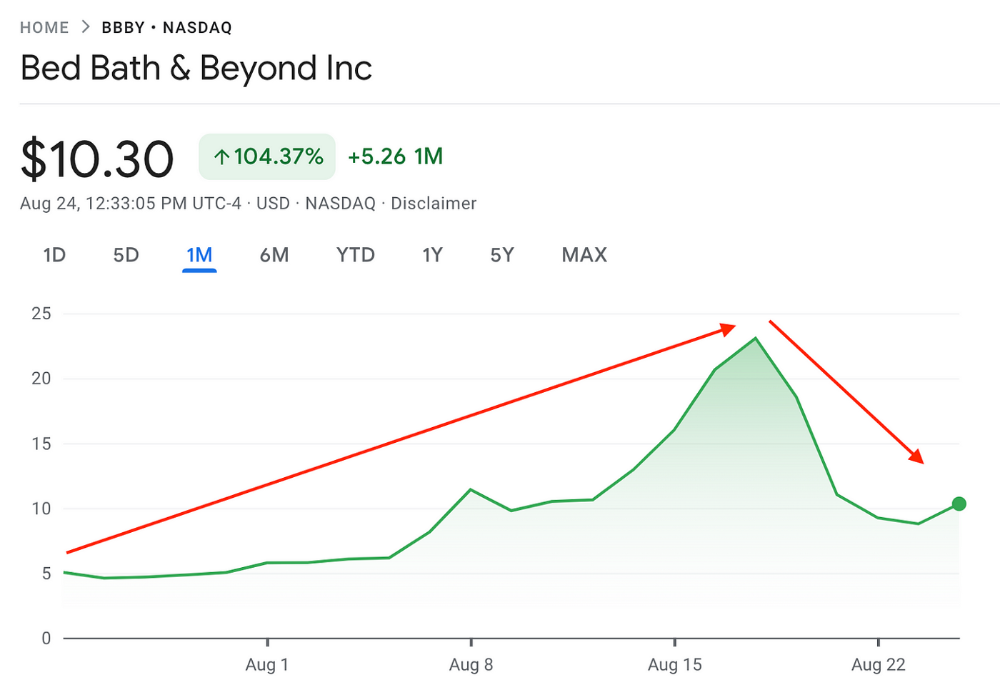
Smallholders have been buying the stock for weeks and will lose heavily if it falls further. Bed Bath & Beyond is the second most popular stock after Foot Locker, ahead of GameStop and Apple.
Jake Freeman earned $110 million thanks to a significant stock market flurry.
Online broker customers aren't the only ones with jitters. By June 2022, Ken Griffin's Citadel and Stephen Mandel's Lone Pine Capital held nearly a third of the company's capital. Did big managers sell before the stock plummeted?
Recent stock movements (derivatives) and rumors could prompt a SEC investigation.
Jake Freeman wrote to the board of directors after his investment to call for a turnaround, given the company's persistent problems and short sellers. The bathroom and kitchen products distribution group's stock soared in July 2022 due to renewed buying by private speculators, who made it one of their meme stocks with AMC and GameStop.
Second-quarter 2022 results and financial health worsened. He didn't celebrate his miraculous operation in a nightclub. He told a British newspaper, "I'm shocked." His parents dined in New York. He returned to Los Angeles to study math and economics.
Jake Freeman founded Freeman Capital Management with his savings and $25 million from family, friends, and acquaintances. They are the ones who are entitled to the $110 million he raised in one month. Will his investors pocket and withdraw all or part of their profits or will they trust the young prodigy for new stunts on Wall Street?
His operation should attract new clients. Well-known hedge funds may hire him.
Jake Freeman didn't listen to gurus or former traders. At 17, he interned at a quantitative finance and derivatives hedge fund, Volaris. At 13, he began investing with his pharmaceutical executive uncle. All countries have increased their Google searches for the young trader in the last week.
Naturally, his success has inspired resentment.
His success stirs jealousy, and he's attacked on social media. On Reddit, people who lost money on Bed Bath & Beyond, Jake Freeman's fortune, are mourning.
Several conspiracy theories circulate about him, including that he doesn't exist or is working for a Taiwanese amusement park.
If all 20 million American students had the same trading skills, they would have generated $1.46 trillion. Jake Freeman is unique. Apprentice traders' careers are often short, disillusioning, and tragic.
Two years ago, 20-year-old Robinhood client Alexander Kearns committed suicide after losing $750,000 trading options. Great traders start young. Michael Platt of BlueCrest invested in British stocks at age 12 under his grandmother's supervision and made a £30,000 fortune. Paul Tudor Jones started trading before he turned 18 with his uncle. Warren Buffett, at age 10, was discussing investments with Goldman Sachs' head. Oracle of Omaha tells all.