



More on Economics & Investing
Trevor Stark
3 years ago
Economics is complete nonsense.
Mainstream economics haven't noticed.

What come to mind when I say the word "economics"?
Probably GDP, unemployment, and inflation.
If you've ever watched the news or listened to an economist, they'll use data like these to defend a political goal.
The issue is that these statistics are total bunk.
I'm being provocative, but I mean it:
The economy is not measured by GDP.
How many people are unemployed is not counted in the unemployment rate.
Inflation is not measured by the CPI.
All orthodox economists' major economic statistics are either wrong or falsified.
Government institutions create all these stats. The administration wants to reassure citizens the economy is doing well.
GDP does not reflect economic expansion.
GDP measures a country's economic size and growth. It’s calculated by the BEA, a government agency.
The US has the world's largest (self-reported) GDP, growing 2-3% annually.
If GDP rises, the economy is healthy, say economists.
Why is the GDP flawed?
GDP measures a country's yearly spending.
The government may adjust this to make the economy look good.
GDP = C + G + I + NX
C = Consumer Spending
G = Government Spending
I = Investments (Equipment, inventories, housing, etc.)
NX = Exports minus Imports
GDP is a country's annual spending.
The government can print money to boost GDP. The government has a motive to increase and manage GDP.
Because government expenditure is part of GDP, printing money and spending it on anything will raise GDP.
They've done this. Since 1950, US government spending has grown 8% annually, faster than GDP.
In 2022, government spending accounted for 44% of GDP. It's the highest since WWII. In 1790-1910, it was 3% of GDP.
Who cares?
The economy isn't only spending. Focus on citizens' purchasing power or quality of life.
Since GDP just measures spending, the government can print money to boost GDP.
Even if Americans are poorer than last year, economists can say GDP is up and everything is fine.
How many people are unemployed is not counted in the unemployment rate.
The unemployment rate measures a country's labor market. If unemployment is high, people aren't doing well economically.
The BLS estimates the (self-reported) unemployment rate as 3-4%.
Why is the unemployment rate so high?
The US government surveys 100k persons to measure unemployment. They extrapolate this data for the country.
They come into 3 categories:
Employed
People with jobs are employed … duh.
Unemployed
People who are “jobless, looking for a job, and available for work” are unemployed
Not in the labor force
The “labor force” is the employed + the unemployed.
The unemployment rate is the percentage of unemployed workers.
Problem is unemployed definition. You must actively seek work to be considered unemployed.
You're no longer unemployed if you haven't interviewed in 4 weeks.
This shit makes no goddamn sense.
Why does this matter?
You can't interview if there are no positions available. You're no longer unemployed after 4 weeks.
In 1994, the BLS redefined "unemployed" to exclude discouraged workers.
If you haven't interviewed in 4 weeks, you're no longer counted in the unemployment rate.
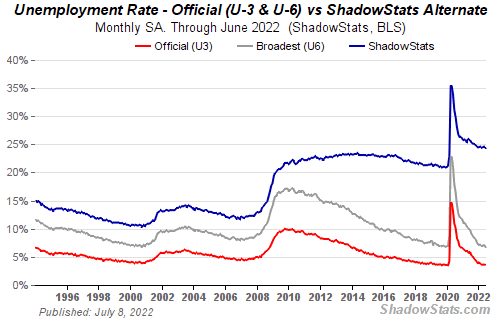
If unemployment were measured by total unemployed, it would be 25%.
Because the government wants to keep the unemployment rate low, they modify the definition.
If every US resident was unemployed and had no job interviews, economists would declare 0% unemployment. Excellent!
Inflation is not measured by the CPI.
The BLS measures CPI. This month was the highest since 1981.
CPI measures the cost of a basket of products across time. Food, energy, shelter, and clothes are included.
A 9.1% CPI means the basket of items is 9.1% more expensive.
What is the CPI problem?
Here's a more detailed explanation of CPI's flaws.
In summary, CPI is manipulated to be understated.
Housing costs are understated to manipulate CPI. Housing accounts for 33% of the CPI because it's the biggest expense for most people.
This signifies it's the biggest CPI weight.
Rather than using actual house prices, the Bureau of Labor Statistics essentially makes shit up. You can read more about the process here.
Surprise! It’s bullshit
The BLS stated Shelter's price rose 5.5% this month.
House prices are up 11-21%. (Source 1, Source 2, Source 3)
Rents are up 14-26%. (Source 1, Source 2)
Why is this important?
If CPI included housing prices, it would be 12-15 percent this month, not 9.1 percent.
9% inflation is nuts. Your money's value halves every 7 years at 9% inflation.
Worse is 15% inflation. Your money halves every 4 years at 15% inflation.
If everyone realized they needed to double their wage every 4-5 years to stay wealthy, there would be riots.
Inflation drains our money's value so the government can keep printing it.
The Solution
Most individuals know the existing system doesn't work, but can't explain why.
People work hard yet lag behind. The government lies about the economy's data.
In reality:
GDP has been down since 2008
25% of Americans are unemployed
Inflation is actually 15%
People might join together to vote out kleptocratic politicians if they knew the reality.
Having reliable economic data is the first step.
People can't understand the situation without sufficient information. Instead of immigrants or billionaires, people would blame liar politicians.
Here’s the vision:
A decentralized, transparent, and global dashboard that tracks economic data like GDP, unemployment, and inflation for every country on Earth.
Government incentives influence economic statistics.
ShadowStats has already started this effort, but the calculations must be transparent, decentralized, and global to be effective.
If interested, email me at trevorstark02@gmail.com.
Here are some links to further your research:

Sofien Kaabar, CFA
3 years ago
How to Make a Trading Heatmap
Python Heatmap Technical Indicator

Heatmaps provide an instant overview. They can be used with correlations or to predict reactions or confirm the trend in trading. This article covers RSI heatmap creation.
The Market System
Market regime:
Bullish trend: The market tends to make higher highs, which indicates that the overall trend is upward.
Sideways: The market tends to fluctuate while staying within predetermined zones.
Bearish trend: The market has the propensity to make lower lows, indicating that the overall trend is downward.
Most tools detect the trend, but we cannot predict the next state. The best way to solve this problem is to assume the current state will continue and trade any reactions, preferably in the trend.
If the EURUSD is above its moving average and making higher highs, a trend-following strategy would be to wait for dips before buying and assuming the bullish trend will continue.
Indicator of Relative Strength
J. Welles Wilder Jr. introduced the RSI, a popular and versatile technical indicator. Used as a contrarian indicator to exploit extreme reactions. Calculating the default RSI usually involves these steps:
Determine the difference between the closing prices from the prior ones.
Distinguish between the positive and negative net changes.
Create a smoothed moving average for both the absolute values of the positive net changes and the negative net changes.
Take the difference between the smoothed positive and negative changes. The Relative Strength RS will be the name we use to describe this calculation.
To obtain the RSI, use the normalization formula shown below for each time step.
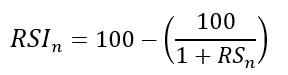
The 13-period RSI and black GBPUSD hourly values are shown above. RSI bounces near 25 and pauses around 75. Python requires a four-column OHLC array for RSI coding.
import numpy as np
def add_column(data, times):
for i in range(1, times + 1):
new = np.zeros((len(data), 1), dtype = float)
data = np.append(data, new, axis = 1)
return data
def delete_column(data, index, times):
for i in range(1, times + 1):
data = np.delete(data, index, axis = 1)
return data
def delete_row(data, number):
data = data[number:, ]
return data
def ma(data, lookback, close, position):
data = add_column(data, 1)
for i in range(len(data)):
try:
data[i, position] = (data[i - lookback + 1:i + 1, close].mean())
except IndexError:
pass
data = delete_row(data, lookback)
return data
def smoothed_ma(data, alpha, lookback, close, position):
lookback = (2 * lookback) - 1
alpha = alpha / (lookback + 1.0)
beta = 1 - alpha
data = ma(data, lookback, close, position)
data[lookback + 1, position] = (data[lookback + 1, close] * alpha) + (data[lookback, position] * beta)
for i in range(lookback + 2, len(data)):
try:
data[i, position] = (data[i, close] * alpha) + (data[i - 1, position] * beta)
except IndexError:
pass
return data
def rsi(data, lookback, close, position):
data = add_column(data, 5)
for i in range(len(data)):
data[i, position] = data[i, close] - data[i - 1, close]
for i in range(len(data)):
if data[i, position] > 0:
data[i, position + 1] = data[i, position]
elif data[i, position] < 0:
data[i, position + 2] = abs(data[i, position])
data = smoothed_ma(data, 2, lookback, position + 1, position + 3)
data = smoothed_ma(data, 2, lookback, position + 2, position + 4)
data[:, position + 5] = data[:, position + 3] / data[:, position + 4]
data[:, position + 6] = (100 - (100 / (1 + data[:, position + 5])))
data = delete_column(data, position, 6)
data = delete_row(data, lookback)
return dataMake sure to focus on the concepts and not the code. You can find the codes of most of my strategies in my books. The most important thing is to comprehend the techniques and strategies.
My weekly market sentiment report uses complex and simple models to understand the current positioning and predict the future direction of several major markets. Check out the report here:
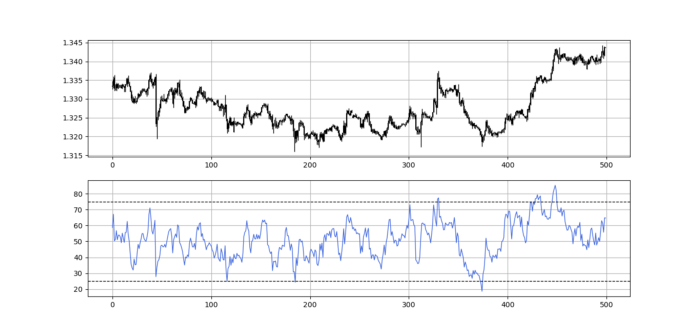
Using the Heatmap to Find the Trend
RSI trend detection is easy but useless. Bullish and bearish regimes are in effect when the RSI is above or below 50, respectively. Tracing a vertical colored line creates the conditions below. How:
When the RSI is higher than 50, a green vertical line is drawn.
When the RSI is lower than 50, a red vertical line is drawn.
Zooming out yields a basic heatmap, as shown below.
Plot code:
def indicator_plot(data, second_panel, window = 250):
fig, ax = plt.subplots(2, figsize = (10, 5))
sample = data[-window:, ]
for i in range(len(sample)):
ax[0].vlines(x = i, ymin = sample[i, 2], ymax = sample[i, 1], color = 'black', linewidth = 1)
if sample[i, 3] > sample[i, 0]:
ax[0].vlines(x = i, ymin = sample[i, 0], ymax = sample[i, 3], color = 'black', linewidth = 1.5)
if sample[i, 3] < sample[i, 0]:
ax[0].vlines(x = i, ymin = sample[i, 3], ymax = sample[i, 0], color = 'black', linewidth = 1.5)
if sample[i, 3] == sample[i, 0]:
ax[0].vlines(x = i, ymin = sample[i, 3], ymax = sample[i, 0], color = 'black', linewidth = 1.5)
ax[0].grid()
for i in range(len(sample)):
if sample[i, second_panel] > 50:
ax[1].vlines(x = i, ymin = 0, ymax = 100, color = 'green', linewidth = 1.5)
if sample[i, second_panel] < 50:
ax[1].vlines(x = i, ymin = 0, ymax = 100, color = 'red', linewidth = 1.5)
ax[1].grid()
indicator_plot(my_data, 4, window = 500)
Call RSI on your OHLC array's fifth column. 4. Adjusting lookback parameters reduces lag and false signals. Other indicators and conditions are possible.
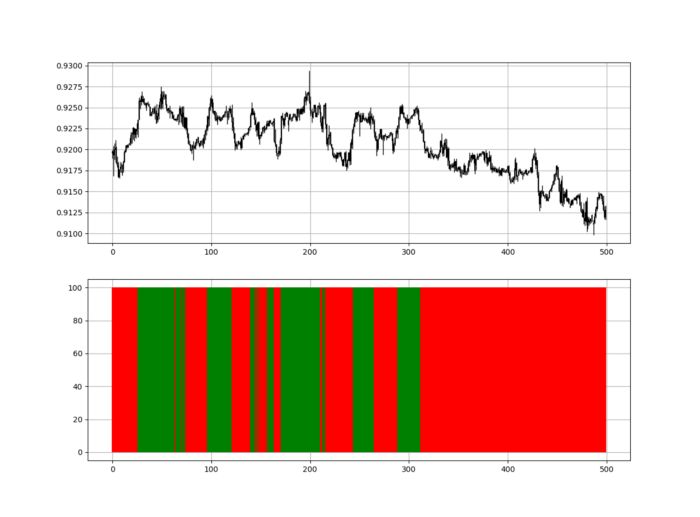
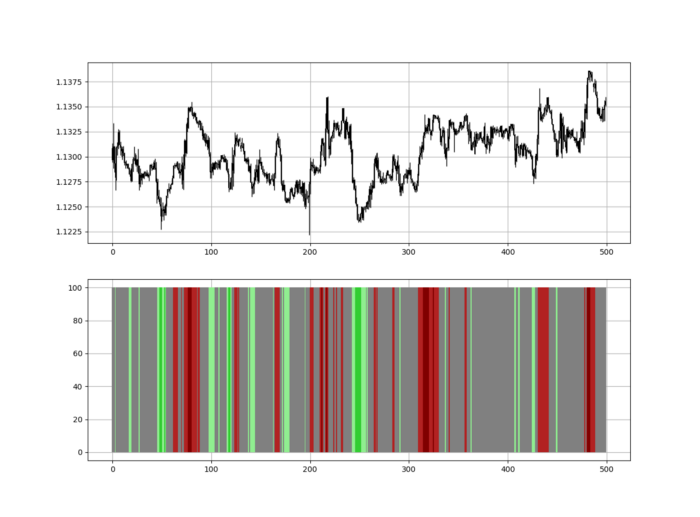
Another suggestion is to develop an RSI Heatmap for Extreme Conditions.
Contrarian indicator RSI. The following rules apply:
Whenever the RSI is approaching the upper values, the color approaches red.
The color tends toward green whenever the RSI is getting close to the lower values.
Zooming out yields a basic heatmap, as shown below.
Plot code:
import matplotlib.pyplot as plt
def indicator_plot(data, second_panel, window = 250):
fig, ax = plt.subplots(2, figsize = (10, 5))
sample = data[-window:, ]
for i in range(len(sample)):
ax[0].vlines(x = i, ymin = sample[i, 2], ymax = sample[i, 1], color = 'black', linewidth = 1)
if sample[i, 3] > sample[i, 0]:
ax[0].vlines(x = i, ymin = sample[i, 0], ymax = sample[i, 3], color = 'black', linewidth = 1.5)
if sample[i, 3] < sample[i, 0]:
ax[0].vlines(x = i, ymin = sample[i, 3], ymax = sample[i, 0], color = 'black', linewidth = 1.5)
if sample[i, 3] == sample[i, 0]:
ax[0].vlines(x = i, ymin = sample[i, 3], ymax = sample[i, 0], color = 'black', linewidth = 1.5)
ax[0].grid()
for i in range(len(sample)):
if sample[i, second_panel] > 90:
ax[1].vlines(x = i, ymin = 0, ymax = 100, color = 'red', linewidth = 1.5)
if sample[i, second_panel] > 80 and sample[i, second_panel] < 90:
ax[1].vlines(x = i, ymin = 0, ymax = 100, color = 'darkred', linewidth = 1.5)
if sample[i, second_panel] > 70 and sample[i, second_panel] < 80:
ax[1].vlines(x = i, ymin = 0, ymax = 100, color = 'maroon', linewidth = 1.5)
if sample[i, second_panel] > 60 and sample[i, second_panel] < 70:
ax[1].vlines(x = i, ymin = 0, ymax = 100, color = 'firebrick', linewidth = 1.5)
if sample[i, second_panel] > 50 and sample[i, second_panel] < 60:
ax[1].vlines(x = i, ymin = 0, ymax = 100, color = 'grey', linewidth = 1.5)
if sample[i, second_panel] > 40 and sample[i, second_panel] < 50:
ax[1].vlines(x = i, ymin = 0, ymax = 100, color = 'grey', linewidth = 1.5)
if sample[i, second_panel] > 30 and sample[i, second_panel] < 40:
ax[1].vlines(x = i, ymin = 0, ymax = 100, color = 'lightgreen', linewidth = 1.5)
if sample[i, second_panel] > 20 and sample[i, second_panel] < 30:
ax[1].vlines(x = i, ymin = 0, ymax = 100, color = 'limegreen', linewidth = 1.5)
if sample[i, second_panel] > 10 and sample[i, second_panel] < 20:
ax[1].vlines(x = i, ymin = 0, ymax = 100, color = 'seagreen', linewidth = 1.5)
if sample[i, second_panel] > 0 and sample[i, second_panel] < 10:
ax[1].vlines(x = i, ymin = 0, ymax = 100, color = 'green', linewidth = 1.5)
ax[1].grid()
indicator_plot(my_data, 4, window = 500)
Dark green and red areas indicate imminent bullish and bearish reactions, respectively. RSI around 50 is grey.
Summary
To conclude, my goal is to contribute to objective technical analysis, which promotes more transparent methods and strategies that must be back-tested before implementation.
Technical analysis will lose its reputation as subjective and unscientific.
When you find a trading strategy or technique, follow these steps:
Put emotions aside and adopt a critical mindset.
Test it in the past under conditions and simulations taken from real life.
Try optimizing it and performing a forward test if you find any potential.
Transaction costs and any slippage simulation should always be included in your tests.
Risk management and position sizing should always be considered in your tests.
After checking the above, monitor the strategy because market dynamics may change and make it unprofitable.

Desiree Peralta
3 years ago
How to Use the 2023 Recession to Grow Your Wealth Exponentially
This season's three best money moves.

“Millionaires are made in recessions.” — Time Capital
We're in a serious downturn, whether or not we're in a recession.
97% of business owners are decreasing costs by more than 10%, and all markets are down 30%.
If you know what you're doing and analyze the markets correctly, this is your chance to become a millionaire.
In any recession, there are always excellent possibilities to seize. Real estate, crypto, stocks, enterprises, etc.
What you do with your money could influence your future riches.
This article analyzes the three key markets, their circumstances for 2023, and how to profit from them.
Ways to make money on the stock market.
If you're conservative like me, you should invest in an index fund. Most of these funds are down 10-30% of ATH:
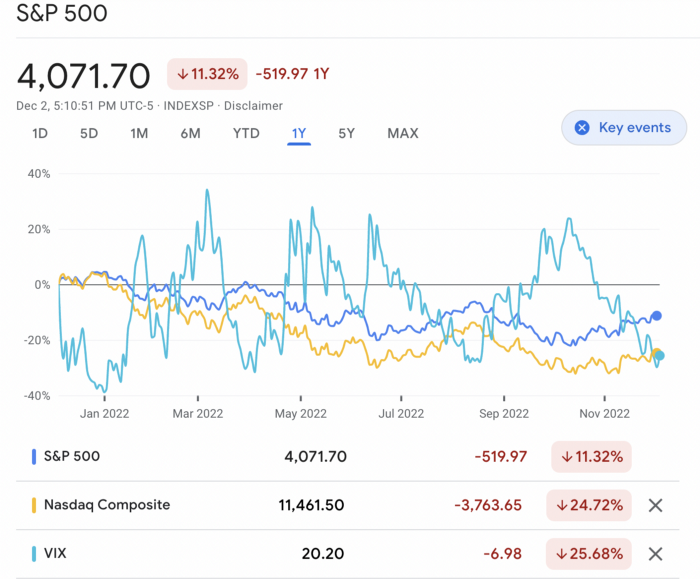
In earlier recessions, most money index funds lost 20%. After this downturn, they grew and passed the ATH in subsequent months.
Now is the greatest moment to invest in index funds to grow your money in a low-risk approach and make 20%.
If you want to be risky but wise, pick companies that will get better next year but are struggling now.
Even while we can't be 100% confident of a company's future performance, we know some are strong and will have a fantastic year.
Microsoft (down 22%), JPMorgan Chase (15.6%), Amazon (45%), and Disney (33.8%).
These firms give dividends, so you can earn passively while you wait.
So I consider that a good strategy to make wealth in the current stock market is to create two portfolios: one based on index funds to earn 10% to 20% profit when the corrections end, and the other based on individual stocks of popular and strong companies to earn 20%-30% return and dividends while you wait.
How to profit from the downturn in the real estate industry.
With rising mortgage rates, it's the worst moment to buy a home if you don't want to be eaten by banks. In the U.S., interest rates are double what they were three years ago, so buying now looks foolish.
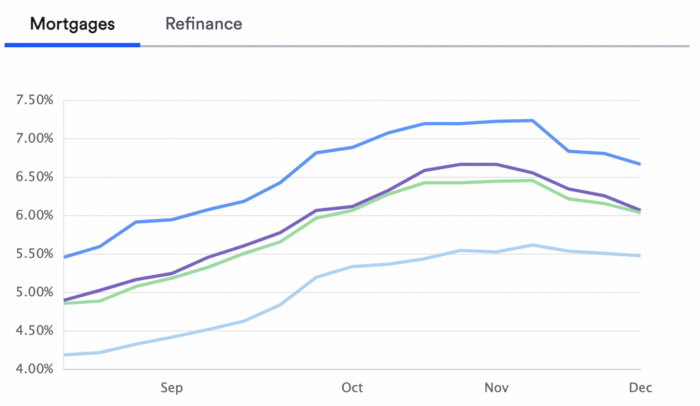
Due to these rates, property prices are falling, but that won't last long since individuals will take advantage.
According to historical data, now is the ideal moment to buy a house for the next five years and perhaps forever.
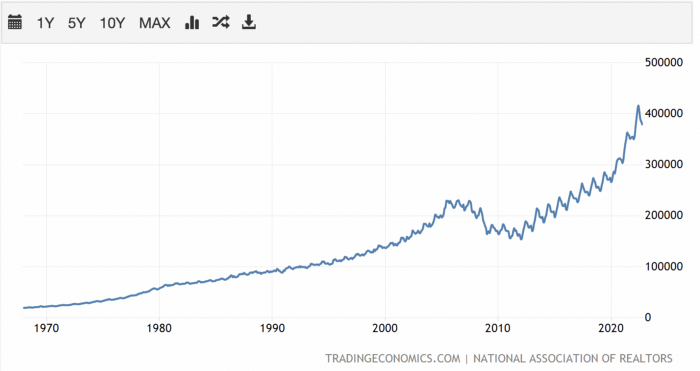
If you can buy a house, do it. You can refinance the interest at a lower rate with acceptable credit, but not the house price.
Take advantage of the housing market prices now because you won't find a decent deal when rates normalize.
How to profit from the cryptocurrency market.
This is the riskiest market to tackle right now, but it could offer the most opportunities if done appropriately.
The most powerful cryptocurrencies are down more than 60% from last year: $68,990 for BTC and $4,865 for ETH.
If you focus on those two coins, you can make 30%-60% without waiting for them to return to their ATH, and they're low enough to be a solid investment.
I don't encourage trying other altcoins because the crypto market is in crisis and you can lose everything if you're greedy.
Still, the main Cryptos are a good investment provided you store them in an external wallet and follow financial gurus' security advice.
Last thoughts
We can't anticipate a recession until it ends. We can't forecast a market or asset's lowest point, therefore waiting makes little sense.
If you want to develop your wealth, assess the money prospects on all the marketplaces and initiate long-term trades.
Many millionaires are made during recessions because they don't fear negative figures and use them to scale their money.
You might also like

Nitin Sharma
3 years ago
The result of my side-hustle blog post with ChatGPT is remarkable.
It's free now.

Most content writers—including me—write about side hustles because they do well.
I wrote several articles on a profitable programming side hustle.
Later, I learnt about AI content-generating platforms like Jasper.ai and Copy.ai, which I thought were terrible because they required subscriptions and had bad content. Even I dislike automatic online posting.
Since ChatGPT is becoming more popular, I tried it. It's free now.
Note: I wasn’t compensated to write this piece by this tool. In other words, I don’t receive any payment from their founders. There is no affiliate link, and right now it is free to use. Also, ChatGPT can do a lot more than what I ever did.
Begin.
OpenAI account registration requires visiting the website (if you don’t have one). Just write anything into the chatbot and get a response.
First, I wrote about the top 10 2023 side businesses.
This came in seconds.
2023 is shaping up to be a year of growth and opportunity for entrepreneurs and side hustlers. With the rise of remote work and the growing gig economy, there are many income streams to consider launching in the coming year. Here are the top 10 income streams to launch in 2023:
Virtual Assistant — The demand for virtual assistants is on the rise as more businesses move online. As a virtual assistant, you can offer administrative, technical, or creative services to clients remotely.
Online Tutoring — If you have expertise in a particular subject, consider becoming an online tutor. There are many platforms that connect tutors with students looking for help with their studies.
Freelance Writing — If you have a knack for writing, consider becoming a freelance writer. You can offer your services to businesses, bloggers, and individuals looking for content for their websites or social media platforms.
Graphic Design — If you have a talent for design, consider starting a graphic design side hustle. You can create logos, banners, and other visual content for businesses and individuals.
Social Media Management — Many businesses are looking for help with managing their social media accounts. As a social media manager, you can help businesses create and execute social media strategies to reach their target audience.
Dropshipping — Dropshipping is a business model where you sell products without actually holding any inventory. You can partner with suppliers and ship the products directly to the customer on behalf of the business.
Pet Sitting — If you love animals, consider starting a pet-sitting side hustle. You can offer your services to pet owners who need someone to take care of their pets while they are away.
Home Cleaning — With busy schedules, many people are looking for help with cleaning their homes. As a home cleaning service provider, you can offer your services to help keep homes tidy and organized.
Event Planning — If you have a talent for organization and planning, consider starting an event planning side hustle. You can offer your services to help plan and execute events for businesses and individuals.
Online Teaching — With the rise of online education, there is a growing demand for online teachers. If you have expertise in a particular subject, consider becoming an online teacher and offer your services to students looking for personalized instruction.
In conclusion, 2023 is shaping up to be a great year for launching new income streams. Whether you are looking to start a virtual assistant business, become an online tutor, or offer home cleaning services, there are many opportunities to turn your skills and expertise into a profitable side hustle.
Better than most online side hustle posts, right?
Write about the top 10 programming side hustles to start in 2023.
I got this.
If you are a programmer looking to start a side hustle, 2023 is the perfect time to launch your own business. With the growing demand for software and app development, there are many opportunities for programmers to turn their skills into a profitable side hustle. Here are the top 10 programming side hustles to start in 2023:
App Development — With the rise of smartphones and tablets, there is a growing demand for app development. You can offer your services to businesses and individuals looking to create custom apps for their needs.
Website Development — Many businesses and individuals are looking for help with creating and maintaining their websites. As a website developer, you can offer your services to help design, build, and manage websites for your clients.
Software Development — If you have expertise in a particular programming language, consider starting a software development side hustle. You can offer your services to businesses and individuals looking to create custom software solutions for their needs.
Game Development — The gaming industry is thriving, and there is a growing demand for game development. If you have experience in game development, you can offer your services to businesses and individuals looking to create custom games.
Data Analysis — With the rise of big data, there is a growing demand for data analysts. As a data analyst, you can offer your services to businesses and individuals looking to make sense of their data and gain insights from it.
Machine Learning — Machine learning is a rapidly growing field, and there is a growing demand for machine learning experts. If you have experience in machine learning, you can offer your services to businesses and individuals looking to develop custom machine learning solutions.
Cloud Computing — With the rise of cloud computing, there is a growing demand for cloud experts. If you have experience in cloud computing, you can offer your services to businesses and individuals looking to migrate their applications and data to the cloud.
Blockchain Development — Blockchain technology is gaining popularity, and there is a growing demand for blockchain developers. If you have experience in blockchain development, you can offer your services to businesses and individuals looking to develop custom blockchain solutions.
Artificial Intelligence — Artificial intelligence is a rapidly growing field, and there is a growing demand for AI experts. If you have experience in artificial intelligence, you can offer your services to businesses and individuals looking to develop custom AI solutions.
Virtual Reality — Virtual reality is an exciting and emerging technology, and there is a growing demand for VR developers. If you have experience in VR development, you can offer your services to businesses and individuals looking to create custom VR experiences.
In conclusion, 2023 is a great time to start a programming side hustle. Whether you are interested in app development, website development, or machine learning, there are many opportunities for programmers to turn their skills into a profitable business.
These two blogs show that AI can simplify blog authoring.
I asked some tough programming questions, and most were suitable.
The content may occasionally not be what we want, but it will almost always be very helpful to you.
Enjoy.

Joseph Mavericks
4 years ago
5 books my CEO read to make $30M
Offices without books are like bodies without souls.

After 10 years, my CEO sold his company for $30 million. I've shared many of his lessons on medium. You could ask him anything at his always-open office. He also said we could use his office for meetings while he was away. When I used his office for work, I was always struck by how many books he had.
Books are useful in almost every aspect of learning. Building a business, improving family relationships, learning a new language, a new skill... Books teach, guide, and structure. Whether fiction or nonfiction, books inspire, give ideas, and develop critical thinking skills.
My CEO prefers non-fiction and attends a Friday book club. This article discusses 5 books I found in his office that impacted my life/business. My CEO sold his company for $30 million, but I've built a steady business through blogging and video making.
I recall events and lessons I learned from my CEO and how they relate to each book, and I explain how I applied the book's lessons to my business and life.
Note: This post has no affiliate links.
1. The One Thing — Gary Keller

Gary Keller, a real estate agent, wanted more customers. So he and his team brainstormed ways to get more customers. They decided to write a bestseller about work and productivity. The more people who saw the book, the more customers they'd get.
Gary Keller focused on writing the best book on productivity, work, and efficiency for months. His business experience. Keller's business grew after the book's release.
The author summarizes the book in one question.
"What's the one thing that will make everything else easier or unnecessary?"
When I started my blog and business alongside my 9–5, I quickly identified my one thing: writing. My business relied on it, so it had to be great. Without writing, there was no content, traffic, or business.
My CEO focused on funding when he started his business. Even in his final years, he spent a lot of time on the phone with investors, either to get more money or to explain what he was doing with it. My CEO's top concern was money, and the other super important factors were handled by separate teams.
Product tech and design
Incredible customer support team
Excellent promotion team
Profitable sales team
My CEO didn't always focus on one thing and ignore the rest. He was on all of those teams when I started my job. He'd start his day in tech, have lunch with marketing, and then work in sales. He was in his office on the phone at night.
He eventually realized his errors. Investors told him he couldn't do everything for the company. If needed, he had to change internally. He learned to let go, mind his own business, and focus for the next four years. Then he sold for $30 million.
The bigger your project/company/idea, the more you'll need to delegate to stay laser-focused. I started something new every few months for 10 years before realizing this. So much to do makes it easy to avoid progress. Once you identify the most important aspect of your project and enlist others' help, you'll be successful.
2. Eat That Frog — Brian Tracy

The author quote sums up book's essence:
Mark Twain said that if you eat a live frog in the morning, it's probably the worst thing that will happen to you all day. Your "frog" is the biggest, most important task you're most likely to procrastinate on.
"Frog" and "One Thing" are both about focusing on what's most important. Eat That Frog recommends doing the most important task first thing in the morning.
I shared my CEO's calendar in an article 10 months ago. Like this:

CEO's average week (some information crossed out for confidentiality)
Notice anything about 8am-8:45am? Almost every day is the same (except Friday). My CEO started his day with a management check-in for 2 reasons:
Checking in with all managers is cognitively demanding, and my CEO is a morning person.
In a young startup where everyone is busy, the morning management check-in was crucial. After 10 am, you couldn't gather all managers.
When I started my blog, writing was my passion. I'm a morning person, so I woke up at 6 am and started writing by 6:30 am every day for a year. This allowed me to publish 3 articles a week for 52 weeks to build my blog and audience. After 2 years, I'm not stopping.
3. Deep Work — Cal Newport

Deep work is focusing on a cognitively demanding task without distractions (like a morning management meeting). It helps you master complex information quickly and produce better results faster. In a competitive world 10 or 20 years ago, focus wasn't a huge advantage. Smartphones, emails, and social media made focus a rare, valuable skill.
Most people can't focus anymore. Screens light up, notifications buzz, emails arrive, Instagram feeds... Many people don't realize they're interrupted because it's become part of their normal workflow.
Cal Newport mentions Bill Gates' "Think Weeks" in Deep Work.
Microsoft CEO Bill Gates would isolate himself (often in a lakeside cottage) twice a year to read and think big thoughts.
Inside Bill's Brain on Netflix shows Newport's lakeside cottage. I've always wanted a lakeside cabin to work in. My CEO bought a lakehouse after selling his company, but now he's retired.
As a company grows, you can focus less on it. In a previous section, I said investors told my CEO to get back to basics and stop micromanaging. My CEO's commitment and ability to get work done helped save the company. His deep work and new frameworks helped us survive the corona crisis (more on this later).
The ability to deep work will be a huge competitive advantage in the next century. Those who learn to work deeply will likely be successful while everyone else is glued to their screens, Bluetooth-synced to their watches, and playing Candy Crush on their tablets.
4. The 7 Habits of Highly Effective People — Stephen R. Covey

It took me a while to start reading this book because it seemed like another shallow self-help bible. I kept finding this book when researching self-improvement. I tried it because it was everywhere.
Stephen Covey taught me 2 years ago to have a personal mission statement.
A 7 Habits mission statement describes the life you want to lead, the character traits you want to embody, and the impact you want to have on others. shortform.com
I've had many lunches with my CEO and talked about Vipassana meditation and Sunday forest runs, but I've never seen his mission statement. I'm sure his family is important, though. In the above calendar screenshot, you can see he always included family events (in green) so we could all see those time slots. We couldn't book him then. Although he never spent as much time with his family as he wanted, he always made sure to be on time for his kid's birthday rather than a conference call.
My CEO emphasized his company's mission. Your mission statement should answer 3 questions.
What does your company do?
How does it do it?
Why does your company do it?
As a graphic designer, I had to create mission-statement posters. My CEO hung posters in each office.
5. Measure What Matters — John Doerr

This book is about Andrew Grove's OKR strategy, developed in 1968. When he joined Google's early investors board, he introduced it to Larry Page and Sergey Brin. Google still uses OKR.
Objective Key Results
Objective: It explains your goals and desired outcome. When one goal is reached, another replaces it. OKR objectives aren't technical, measured, or numerical. They must be clear.
Key Result should be precise, technical, and measurable, unlike the Objective. It shows if the Goal is being worked on. Time-bound results are quarterly or yearly.
Our company almost sank several times. Sales goals were missed, management failed, and bad decisions were made. On a Monday, our CEO announced we'd implement OKR to revamp our processes.
This was a year before the pandemic, and I'm certain we wouldn't have sold millions or survived without this change. This book impacted the company the most, not just management but all levels. Organization and transparency improved. We reached realistic goals. Happy investors. We used the online tool Gtmhub to implement OKR across the organization.
My CEO's company went from near bankruptcy to being acquired for $30 million in 2 years after implementing OKR.
I hope you enjoyed this booklist. Here's a recap of the 5 books and the lessons I learned from each.
The 7 Habits of Highly Effective People — Stephen R. Covey
Have a mission statement that outlines your goals, character traits, and impact on others.
Deep Work — Cal Newport
Focus is a rare skill; master it. Deep workers will succeed in our hyper-connected, distracted world.
The One Thing — Gary Keller
What can you do that will make everything else easier or unnecessary? Once you've identified it, focus on it.
Eat That Frog — Brian Tracy
Identify your most important task the night before and do it first thing in the morning. You'll have a lighter day.
Measure What Matters — John Doerr
On a timeline, divide each long-term goal into chunks. Divide those slices into daily tasks (your goals). Time-bound results are quarterly or yearly. Objectives aren't measured or numbered.
Thanks for reading. Enjoy the ride!

Pat Vieljeux
3 years ago
The three-year business plan is obsolete for startups.
If asked, run.

An entrepreneur asked me about her pitch deck. A Platform as a Service (PaaS).
She told me she hadn't done her 5-year forecasts but would soon.
I said, Don't bother. I added "time-wasting."
“I've been asked”, she said.
“Who asked?”
“a VC”
“5-year forecast?”
“Yes”
“Get another VC. If he asks, it's because he doesn't understand your solution or to waste your time.”
Some VCs are lagging. They're still using steam engines.
10-years ago, 5-year forecasts were requested.
Since then, we've adopted a 3-year plan.
But It's outdated.
Max one year.
What has happened?
Revolutionary technology. NO-CODE.
Revolution's consequences?
Product viability tests are shorter. Hugely. SaaS and PaaS.
Let me explain:
Building a minimum viable product (MVP) that works only takes a few months.
1 to 2 months for practical testing.
Your company plan can be validated or rejected in 4 months as a consequence.
After validation, you can ask for VC money. Even while a prototype can generate revenue, you may not require any.
Good VCs won't ask for a 3-year business plan in that instance.
One-year, though.
If you want, establish a three-year plan, but realize that the second year will be different.
You may have changed your business model by then.
A VC isn't interested in a three-year business plan because your solution may change.
Your ability to create revenue will be key.
But also, to pivot.
They will be interested in your value proposition.
They will want to know what differentiates you from other competitors and why people will buy your product over another.
What will interest them is your resilience, your ability to bounce back.
Not to mention your mindset. The fact that you won’t get discouraged at the slightest setback.
The grit you have when facing adversity, as challenges will surely mark your journey.
The authenticity of your approach. They’ll want to know that you’re not just in it for the money, let alone to show off.
The fact that you put your guts into it and that you are passionate about it. Because entrepreneurship is a leap of faith, a leap into the void.
They’ll want to make sure you are prepared for it because it’s not going to be a walk in the park.
They’ll want to know your background and why you got into it.
They’ll also want to know your family history.
And what you’re like in real life.
So a 5-year plan…. You can bet they won’t give a damn. Like their first pair of shoes.