




More on Productivity

Mickey Mellen
2 years ago
Shifting from Obsidian to Tana?

I relocated my notes database from Roam Research to Obsidian earlier this year expecting to stay there for a long. Obsidian is a terrific tool, and I explained my move in that post.
Moving everything to Tana faster than intended. Tana? Why?
Tana is just another note-taking app, but it does it differently. Three note-taking apps existed before Tana:
simple note-taking programs like Apple Notes and Google Keep.
Roam Research and Obsidian are two graph-style applications that assisted connect your notes.
You can create effective tables and charts with data-focused tools like Notion and Airtable.
Tana is the first great software I've encountered that combines graph and data notes. Google Keep will certainly remain my rapid notes app of preference. This Shu Omi video gives a good overview:
Tana handles everything I did in Obsidian with books, people, and blog entries, plus more. I can find book quotes, log my workouts, and connect my thoughts more easily. It should make writing blog entries notes easier, so we'll see.
Tana is now invite-only, but if you're interested, visit their site and sign up. As Shu noted in the video above, the product hasn't been published yet but seems quite polished.
Whether I stay with Tana or not, I'm excited to see where these apps are going and how they can benefit us all.

The woman
3 years ago
I received a $2k bribe to replace another developer in an interview
I can't believe they’d even think it works!

Developers are usually interviewed before being hired, right? Every organization wants candidates who meet their needs. But they also want to avoid fraud.
There are cheaters in every field. Only two come to mind for the hiring process:
Lying on a resume.
Cheating on an online test.
Recently, I observed another one. One of my coworkers invited me to replace another developer during an online interview! I was astonished, but it’s not new.
The specifics
My ex-colleague recently texted me. No one from your former office will ever approach you after a year unless they need something.
Which was the case. My coworker said his wife needed help as a programmer. I was glad someone asked for my help, but I'm still a junior programmer.
Then he informed me his wife was selected for a fantastic job interview. He said he could help her with the online test, but he needed someone to help with the online interview.
Okay, I guess. Preparing for an online interview is beneficial. But then he said she didn't need to be ready. She needed someone to take her place.
I told him it wouldn't work. Every remote online interview I've ever seen required an open camera.
What followed surprised me. She'd ask to turn off the camera, he said.
I asked why.
He told me if an applicant is unwell, the interviewer may consider an off-camera interview. His wife will say she's sick and prefers no camera.
The plan left me speechless. I declined politely. He insisted and promised $2k if she got the job.
I felt insulted and told him if he persisted, I'd inform his office. I was furious. Later, I apologized and told him to stop.
I'm not sure what they did after that
I'm not sure if they found someone or listened to me. They probably didn't. How would she do the job if she even got it?
It's an internship, he said. With great pay, though. What should an intern do?
I suggested she do the interview alone. Even if she failed, she'd gain confidence and valuable experience.
Conclusion
Many interviewees cheat. My profession is vital to me, thus I'd rather improve my abilities and apply honestly. It's part of my identity.
Am I truthful? Most professionals are not. They fabricate their CVs. Often.
When you support interview cheating, you encourage more cheating! When someone cheats, another qualified candidate may not obtain the job.
One day, that could be you or me.

Pen Magnet
3 years ago
Why Google Staff Doesn't Work

Sundar Pichai unveiled Simplicity Sprint at Google's latest all-hands conference.
To boost employee efficiency.
Not surprising. Few envisioned Google declaring a productivity drive.
Sunder Pichai's speech:
“There are real concerns that our productivity as a whole is not where it needs to be for the head count we have. Help me create a culture that is more mission-focused, more focused on our products, more customer focused. We should think about how we can minimize distractions and really raise the bar on both product excellence and productivity.”
The primary driver driving Google's efficiency push is:
Google's efficiency push follows 13% quarterly revenue increase. Last year in the same quarter, it was 62%.
Market newcomers may argue that the previous year's figure was fuelled by post-Covid reopening and growing consumer spending. Investors aren't convinced. A promising company like Google can't afford to drop so quickly.
Google’s quarterly revenue growth stood at 13%, against 62% in last year same quarter.
Google isn't alone. In my recent essay regarding 2025 programmers, I warned about the economic downturn's effects on FAAMG's workforce. Facebook had suspended hiring, and Microsoft had promised hefty bonuses for loyal staff.
In the same article, I predicted Google's troubles. Online advertising, especially the way Google and Facebook sell it using user data, is over.
FAAMG and 2nd rung IT companies could be the first to fall without Post-COVID revival and uncertain global geopolitics.
Google has hardly ever discussed effectiveness:
Apparently openly.
Amazon treats its employees like robots, even in software positions. It has significant turnover and a terrible reputation as a result. Because of this, it rarely loses money due to staff productivity.
Amazon trumps Google. In reality, it treats its employees poorly.
Google was the founding father of the modern-day open culture.
Larry and Sergey Google founded the IT industry's Open Culture. Silicon Valley called Google's internal democracy and transparency near anarchy. Management rarely slammed decisions on employees. Surveys and internal polls ensured everyone knew the company's direction and had a vote.
20% project allotment (weekly free time to build own project) was Google's open-secret innovation component.
After Larry and Sergey's exit in 2019, this is Google's first profitability hurdle. Only Google insiders can answer these questions.
Would Google's investors compel the company's management to adopt an Amazon-style culture where the developers are treated like circus performers?
If so, would Google follow suit?
If so, how does Google go about doing it?
Before discussing Google's likely plan, let's examine programming productivity.
What determines a programmer's productivity is simple:
How would we answer Google's questions?
As a programmer, I'm more concerned about Simplicity Sprint's aftermath than its economic catalysts.
Large organizations don't care much about quarterly and annual productivity metrics. They have 10-year product-launch plans. If something seems horrible today, it's likely due to someone's lousy judgment 5 years ago who is no longer in the blame game.
Deconstruct our main question.
How exactly do you change the culture of the firm so that productivity increases?
How can you accomplish that without affecting your capacity to profit? There are countless ways to increase output without decreasing profit.
How can you accomplish this with little to no effect on employee motivation? (While not all employers care about it, in this case we are discussing the father of the open company culture.)
How do you do it for a 10-developer IT firm that is losing money versus a 1,70,000-developer organization with a trillion-dollar valuation?
When implementing a large-scale organizational change, success must be carefully measured.
The fastest way to do something is to do it right, no matter how long it takes.
You require clearly-defined group/team/role segregation and solid pass/fail matrices to:
You can give performers rewards.
Ones that are average can be inspired to improve
Underachievers may receive assistance or, in the worst-case scenario, rehabilitation
As a 20-year programmer, I associate productivity with greatness.
Doing something well, no matter how long it takes, is the fastest way to do it.
Let's discuss a programmer's productivity.
Why productivity is a strange term in programming:
Productivity is work per unit of time.
Money=time This is an economic proverb. More hours worked, more pay. Longer projects cost more.
As a buyer, you desire a quick supply. As a business owner, you want employees who perform at full capacity, creating more products to transport and boosting your profits.
All economic matrices encourage production because of our obsession with it. Productivity is the only organic way a nation may increase its GDP.
Time is money — is not just a proverb, but an economical fact.
Applying the same productivity theory to programming gets problematic. An automating computer. Its capacity depends on the software its master writes.
Today, a sophisticated program can process a billion records in a few hours. Creating one takes a competent coder and the necessary infrastructure. Learning, designing, coding, testing, and iterations take time.
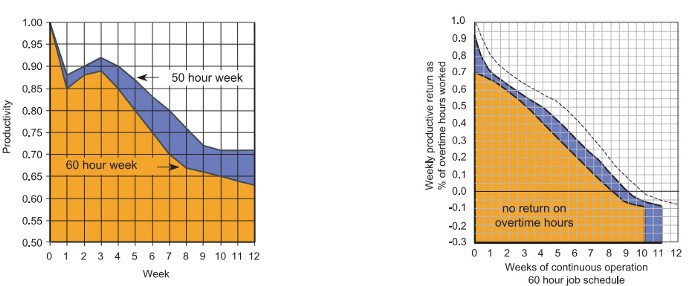
Programming productivity isn't linear, unlike manufacturing and maintenance.
Average programmers produce code every day yet miss deadlines. Expert programmers go days without coding. End of sprint, they often surprise themselves by delivering fully working solutions.
Reversing the programming duties has no effect. Experts aren't needed for productivity.
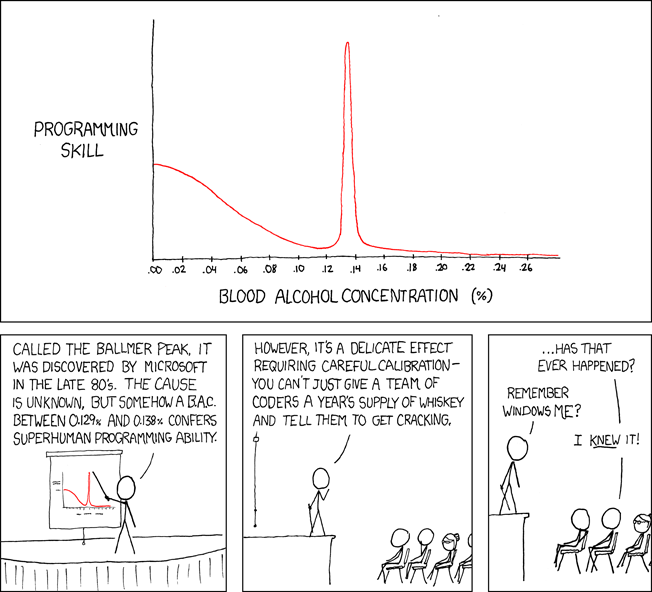
These patterns remind me of an XKCD comic.
Programming productivity depends on two factors:
The capacity of the programmer and his or her command of the principles of computer science
His or her productive bursts, how often they occur, and how long they last as they engineer the answer
At some point, productivity measurement becomes Schrödinger’s cat.
Product companies measure productivity using use cases, classes, functions, or LOCs (lines of code). In days of data-rich source control systems, programmers' merge requests and/or commits are the most preferred yardstick. Companies assess productivity by tickets closed.
Every organization eventually has trouble measuring productivity. Finer measurements create more chaos. Every measure compares apples to oranges (or worse, apples with aircraft.) On top of the measuring overhead, the endeavor causes tremendous and unnecessary stress on teams, lowering their productivity and defeating its purpose.
Macro productivity measurements make sense. Amazon's factory-era management has done it, but at great cost.
Google can pull it off if it wants to.
What Google meant in reality when it said that employee productivity has decreased:
When Google considers its employees unproductive, it doesn't mean they don't complete enough work in the allotted period.
They can't multiply their work's influence over time.
Programmers who produce excellent modules or products are unsure on how to use them.
The best data scientists are unable to add the proper parameters in their models.
Despite having a great product backlog, managers struggle to recruit resources with the necessary skills.
Product designers who frequently develop and A/B test newer designs are unaware of why measures are inaccurate or whether they have already reached the saturation point.
Most ignorant: All of the aforementioned positions are aware of what to do with their deliverables, but neither their supervisors nor Google itself have given them sufficient authority.
So, Google employees aren't productive.
How to fix it?
Business analysis: White suits introducing novel items can interact with customers from all regions. Track analytics events proactively, especially the infrequent ones.
SOLID, DRY, TEST, and AUTOMATION: Do less + reuse. Use boilerplate code creation. If something already exists, don't implement it yourself.
Build features-building capabilities: N features are created by average programmers in N hours. An endless number of features can be built by average programmers thanks to the fact that expert programmers can produce 1 capability in N hours.
Work on projects that will have a positive impact: Use the same algorithm to search for images on YouTube rather than the Mars surface.
Avoid tasks that can only be measured in terms of time linearity at all costs (if a task can be completed in N minutes, then M copies of the same task would cost M*N minutes).
In conclusion:
Software development isn't linear. Why should the makers be measured?
Notation for The Big O
I'm discussing a new way to quantify programmer productivity. (It applies to other professions, but that's another subject)
The Big O notation expresses the paradigm (the algorithmic performance concept programmers rot to ace their Google interview)
Google (or any large corporation) can do this.
Sort organizational roles into categories and specify their impact vs. time objectives. A CXO role's time vs. effect function, for instance, has a complexity of O(log N), meaning that if a CEO raises his or her work time by 8x, the result only increases by 3x.
Plot the influence of each employee over time using the X and Y axes, respectively.
Add a multiplier for Y-axis values to the productivity equation to make business objectives matter. (Example values: Support = 5, Utility = 7, and Innovation = 10).
Compare employee scores in comparable categories (developers vs. devs, CXOs vs. CXOs, etc.) and reward or help employees based on whether they are ahead of or behind the pack.
After measuring every employee's inventiveness, it's straightforward to help underachievers and praise achievers.
Example of a Big(O) Category:
If I ran Google (God forbid, its worst days are far off), here's how I'd classify it. You can categorize Google employees whichever you choose.
The Google interview truth:
O(1) < O(log n) < O(n) < O(n log n) < O(n^x) where all logarithmic bases are < n.
O(1): Customer service workers' hours have no impact on firm profitability or customer pleasure.
CXOs Most of their time is spent on travel, strategic meetings, parties, and/or meetings with minimal floor-level influence. They're good at launching new products but bad at pivoting without disaster. Their directions are being followed.
Devops, UX designers, testers Agile projects revolve around deployment. DevOps controls the levers. Their automation secures results in subsequent cycles.
UX/UI Designers must still prototype UI elements despite improved design tools.
All test cases are proportional to use cases/functional units, hence testers' work is O(N).
Architects Their effort improves code quality. Their right/wrong interference affects product quality and rollout decisions even after the design is set.
Core Developers Only core developers can write code and own requirements. When people understand and own their labor, the output improves dramatically. A single character error can spread undetected throughout the SDLC and cost millions.
Core devs introduce/eliminate 1000x bugs, refactoring attempts, and regression. Following our earlier hypothesis.
The fastest way to do something is to do it right, no matter how long it takes.
Conclusion:
Google is at the liberal extreme of the employee-handling spectrum
Microsoft faced an existential crisis after 2000. It didn't choose Amazon's data-driven people management to revitalize itself.
Instead, it entrusted developers. It welcomed emerging technologies and opened up to open source, something it previously opposed.
Google is too lax in its employee-handling practices. With that foundation, it can only follow Amazon, no matter how carefully.
Any attempt to redefine people's measurements will affect the organization emotionally.
The more Google compares apples to apples, the higher its chances for future rebirth.
You might also like

Isaiah McCall
3 years ago
There is a new global currency emerging, but it is not bitcoin.
America should avoid BRICS

Vladimir Putin has watched videos of Muammar Gaddafi's CIA-backed demise.
Gaddafi...
Thief.
Did you know Gaddafi wanted a gold-backed dinar for Africa? Because he considered our global financial system was a Ponzi scheme, he wanted to discontinue trading oil in US dollars.
Or, Gaddafi's Libya enjoyed Africa's highest quality of living before becoming freed. Pictured:

Vladimir Putin is a nasty guy, but he had his reasons for not mentioning NATO assisting Ukraine in resisting US imperialism. Nobody tells you. Sure.
The US dollar's corruption post-2008, debasement by quantitative easing, and lack of value are key factors. BRICS will replace the dollar.
BRICS aren't bricks.
Economy-related.
Brazil, Russia, India, China, and South Africa have cooperated for 14 years to fight U.S. hegemony with a new international currency: BRICS.
BRICS is mostly comical. Now. Saudi Arabia, the second-largest oil hegemon, wants to join.
So what?
The New World Currency is BRICS
Russia was kicked out of G8 for its aggressiveness in Crimea in 2014.
It's now G7.
No biggie, said Putin, he said, and I quote, “Bon appetite.”
He was prepared. China, India, and Brazil lead the New World Order.
Together, they constitute 40% of the world's population and, according to the IMF, 50% of the world's GDP by 2030.
Here’s what the BRICS president Marcos Prado Troyjo had to say earlier this year about no longer needing the US dollar: “We have implemented the mechanism of mutual settlements in rubles and rupees, and there is no need for our countries to use the dollar in mutual settlements. And today a similar mechanism of mutual settlements in rubles and yuan is being developed by China.”
Ick. That's D.C. and NYC warmongers licking their chops for WW3 nasty.
Here's a lovely picture of BRICS to relax you:

If Saudi Arabia joins BRICS, as President Mohammed Bin Salman has expressed interest, a majority of the Middle East will have joined forces to construct a new world order not based on the US currency.
I'm not sure of the new acronym.
SBRICSS? CIRBSS? CRIBSS?
The Reason America Is Harvesting What It Sowed
BRICS began 14 years ago.
14 years ago, what occurred? Concentrate. It involved CDOs, bad subprime mortgages, and Wall Street quants crunching numbers.
2008 recession
When two nations trade, they do so in US dollars, not Euros or gold.
What happened when 2008, an avoidable crisis caused by US banks' cupidity and ignorance, what happened?
Everyone WORLDWIDE felt the pain.
Mostly due to corporate America's avarice.
This should have been a warning that China and Russia had enough of our bs. Like when France sent a battleship to America after Nixon scrapped the gold standard. The US was warned to shape up or be dethroned (or at least try).

Nixon improved in 1971. Kinda. Invented PetroDollar.
Another BS system that unfairly favors America and possibly pushed Russia, China, and Saudi Arabia into BRICS.
The PetroDollar forces oil-exporting nations to trade in US dollars and invest in US Treasury bonds. Brilliant. Genius evil.
Our misdeeds are:
In conflicts that are not its concern, the USA uses the global reserve currency as a weapon.
Targeted nations abandon the dollar, and rightfully so, as do nations that depend on them for trade in vital resources.
The dollar's position as the world's reserve currency is in jeopardy, which could have disastrous economic effects.
Although we have actually sown our own doom, we appear astonished. According to the Bible, whomever sows to appease his sinful nature will reap destruction from that nature whereas whoever sows to appease the Spirit will reap eternal life from the Spirit.
Americans, even our leaders, lack caution and delayed pleasure. When our unsustainable systems fail, we double down. Bailouts of the banks in 2008 were myopic, puerile, and another nail in America's hegemony.
America has screwed everyone.
We're unpopular.
The BRICS's future
It's happened before.
Saddam Hussein sold oil in Euros in 2000, and the US invaded Iraq a month later. The media has devalued the word conspiracy. The Iraq conspiracy.
There were no WMDs, but NYT journalists like Judy Miller drove Americans into a warmongering frenzy because Saddam would ruin the PetroDollar. Does anyone recall that this war spawned ISIS?
I think America has done good for the world. You can make a convincing case that we're many people's villain.
Learn more in Confessions of an Economic Hitman, The Devil's Chessboard, or Tyranny of the Federal Reserve. Or ignore it. That's easier.
We, America, should extend an olive branch, ask for forgiveness, and learn from our faults, as the Tao Te Ching advises. Unlikely. Our population is apathetic and stupid, and our government is corrupt.
Argentina, Iran, Egypt, and Turkey have also indicated interest in joining BRICS. They're also considering making it gold-backed, making it a new world reserve currency.
You should pay attention.
Thanks for reading!

Tim Denning
3 years ago
Read These Books on Personal Finance to Boost Your Net Worth
And retire sooner.

Books can make you filthy rich.
If you apply what you learn. In 2011, I was broke and had broken dreams.
Someone suggested I read finance books. One Up On Wall Street was his first recommendation.
Finance books were my crack.
I've read every money book since then. Some are good, but most stink.
These books will make you rich.
The Almanack of Naval Ravikant by Eric Jorgenson
This isn't a cliche book.
This book was inspired by a How to Get Rich tweet thread.
It’s one of the best tweets I’ve ever read.
Naval thinks differently. He nukes ordinary ideas. I've never heard better money advice.
Eric Jorgenson wrote a book about this tweet thread with Navals permission. A must-read, easy-to-digest book.
Best quote
Seek wealth, not money or status. Wealth is having assets that earn while you sleep. Money is how we transfer time and wealth. Status is your place in the social hierarchy — Naval
Morgan Housel's The Psychology of Money
Many finance books advise investing like a dunce.
They almost all peddle the buy an index fund BS. Different book.
It's about money-making psychology. Because any fool can get rich and drunk on their ego. Few can consistently make money.
Each chapter is short. A single-page chapter breaks all book publishing rules.
Best quote
Spending money to show people how much money you have is the fastest way to have less money — Morgan Housel
J.L. Collins' The Simple Path to Wealth
Most of the best money books were written by bloggers.
JL Collins blogs. This easy-to-read book was written for his daughter.
This book popularized the phrase F You Money. With enough money in your bank account and investment portfolio, you can say F You more.
A bad boss is an example. You can leave instead of enduring his wrath.
You can then sit at home and look for another job while financially secure. JL says its mind-freedom is powerful.
Best phrasing
You own the things you own and they in turn own you — J.L. Collins
Tony Robbins' Unshakeable
I like Tony. This book makes me sweaty.
Tony interviews the world's top financiers. He interviews people who rarely do so.
This book taught me all-weather portfolio. It's a way to invest in different asset classes in good, bad, recession, or depression times.
Look at it:
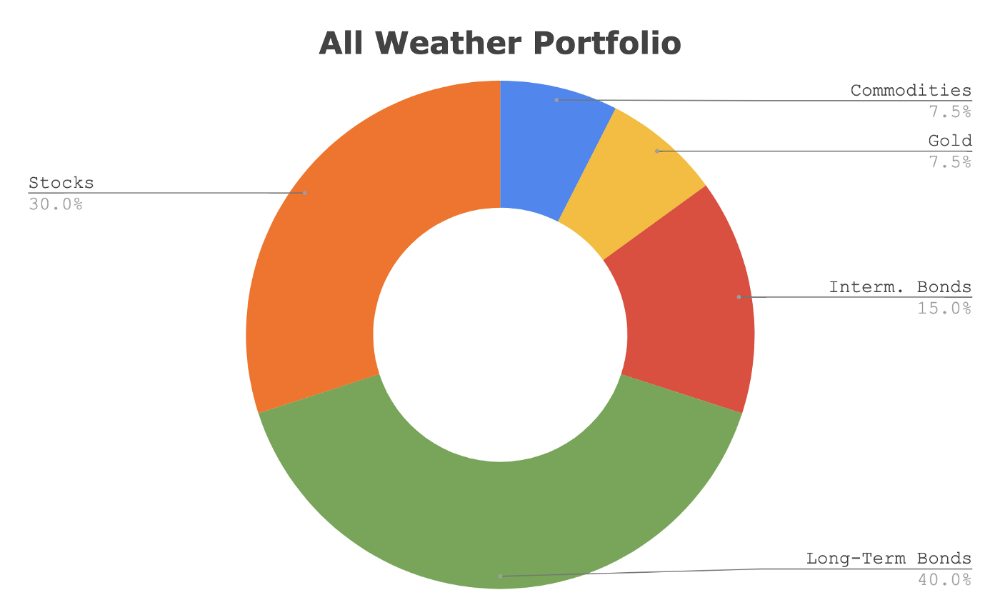
Investing isn’t about buying one big winner — that’s gambling. It’s about investing in a diversified portfolio of assets.
Best phrasing
The best opportunities come in times of maximum pessimism — Tony Robbins
Ben Graham's The Intelligent Investor
This book helped me distinguish between a spectator and an investor.
Spectators are those who shout that crypto, NFTs, or XYZ platform will die.
Tourists. They want attention and to say "I told you so." They make short-term and long-term predictions like fortunetellers. LOL. Idiots.
Benjamin Graham teaches smart investing. You'll buy a long-term asset. To be confident in recessions, use dollar-cost averaging.
Best phrasing
Those who do not remember the past are condemned to repeat it. — Benjamin Graham
The Napoleon Hill book Think and Grow Rich
This classic book introduced positive thinking to modern self-help.
Lazy pessimists can't become rich. No way.
Napoleon said, "Thoughts create reality."
No surprise that he discusses obsession and focus in this book. They are the fastest ways to make more money to invest in time and wealth-protecting assets.
Best phrasing
The starting point of all achievement is DESIRE. Keep this constantly in mind. Weak desire brings weak results, just as a small fire makes a small amount of heat — Napoleon Hill
Ramit Sethi's book I Will Teach You To Be Rich
This book is mostly good. The part about credit cards is trash.
Avoid credit card temptations. I don't care about their airline points.
This book teaches you to master money basics (that many people mess up) then automate it so your monkey brain doesn't ruin your financial future.
The book includes great negotiation tactics to help you make more money in less time.
Best quote
The 85 Percent Solution: Getting started is more important than becoming an expert — Ramit Sethi
David Bach's The Automatic Millionaire
You've probably met a six- or seven-figure earner who's broke. All their money goes to useless things like cars.
Money isn't as essential as what you do with it. David teaches how to automate your earnings for more money.
Compounding works once investing is automated. So you get rich.
His strategy eliminates luck and (almost) guarantees millionaire status.
Best phrasing
Every time you earn one dollar, make sure to pay yourself first — David Bach
Thomas J. Stanley's The Millionaire Next Door
Thomas defies the definition of rich.
He spends much of the book highlighting millionaire traits he's studied.
Rich people are quiet, so you wouldn't know they're wealthy. They don't earn much money or drive a BMW.
Thomas will give you the math to get started.
Best phrasing
I am not impressed with what people own. But I’m impressed with what they achieve. I’m proud to be a physician. Always strive to be the best in your field…. Don’t chase money. If you are the best in your field, money will find you. — Thomas J. Stanley
by Bill Perkins "Die With Zero"
Let’s end with one last book.
Bill's book angered many people. He says we spend too much time saving for retirement and die rich. That bank money is lost time.
Your grandkids could use the money. When children inherit money, they become lazy, entitled a-holes.
Bill wants us to spend our money on life-enhancing experiences. Stop saving money like monopoly monkeys.
Best phrasing
You should be focusing on maximizing your life enjoyment rather than on maximizing your wealth. Those are two very different goals. Money is just a means to an end: Having money helps you to achieve the more important goal of enjoying your life. But trying to maximize money actually gets in the way of achieving the more important goal — Bill Perkins
David Z. Morris
3 years ago
FTX's crash was no accident, it was a crime

Sam Bankman Fried (SDBF) is a legendary con man. But the NYT might not tell you that...
Since SBF's empire was revealed to be a lie, mainstream news organizations and commentators have failed to give readers a straightforward assessment. The New York Times and Wall Street Journal have uncovered many key facts about the scandal, but they have also soft-peddled Bankman-Fried's intent and culpability.
It's clear that the FTX crypto exchange and Alameda Research committed fraud to steal money from users and investors. That’s why a recent New York Times interview was widely derided for seeming to frame FTX’s collapse as the result of mismanagement rather than malfeasance. A Wall Street Journal article lamented FTX's loss of charitable donations, bolstering Bankman's philanthropic pose. Matthew Yglesias, court chronicler of the neoliberal status quo, seemed to whitewash his own entanglements by crediting SBF's money with helping Democrats in 2020 – sidestepping the likelihood that the money was embezzled.
Many outlets have called what happened to FTX a "bank run" or a "run on deposits," but Bankman-Fried insists the company was overleveraged and disorganized. Both attempts to frame the fallout obscure the core issue: customer funds misused.
Because banks lend customer funds to generate returns, they can experience "bank runs." If everyone withdraws at once, they can experience a short-term cash crunch but there won't be a long-term problem.
Crypto exchanges like FTX aren't banks. They don't do bank-style lending, so a withdrawal surge shouldn't strain liquidity. FTX promised customers it wouldn't lend or use their crypto.
Alameda's balance sheet blurs SBF's crypto empire.
The funds were sent to Alameda Research, where they were apparently gambled away. This is massive theft. According to a bankruptcy document, up to 1 million customers could be affected.
In less than a month, reporting and the bankruptcy process have uncovered a laundry list of decisions and practices that would constitute financial fraud if FTX had been a U.S.-regulated entity, even without crypto-specific rules. These ploys may be litigated in U.S. courts if they enabled the theft of American property.
The list is very, very long.
The many crimes of Sam Bankman-Fried and FTX
At the heart of SBF's fraud are the deep and (literally) intimate ties between FTX and Alameda Research, a hedge fund he co-founded. An exchange makes money from transaction fees on user assets, but Alameda trades and invests its own funds.
Bankman-Fried called FTX and Alameda "wholly separate" and resigned as Alameda's CEO in 2019. The two operations were closely linked. Bankman-Fried and Alameda CEO Caroline Ellison were romantically linked.
These circumstances enabled SBF's sin. Within days of FTX's first signs of weakness, it was clear the exchange was funneling customer assets to Alameda for trading, lending, and investing. Reuters reported on Nov. 12 that FTX sent $10 billion to Alameda. As much as $2 billion was believed to have disappeared after being sent to Alameda. Now the losses look worse.
It's unclear why those funds were sent to Alameda or when Bankman-Fried betrayed his depositors. On-chain analysis shows most FTX to Alameda transfers occurred in late 2021, and bankruptcy filings show both lost $3.7 billion in 2021.
SBF's companies lost millions before the 2022 crypto bear market. They may have stolen funds before Terra and Three Arrows Capital, which killed many leveraged crypto players.
FTT loans and prints
CoinDesk's report on Alameda's FTT holdings ignited FTX and Alameda Research. FTX created this instrument, but only a small portion was traded publicly; FTX and Alameda held the rest. These holdings were illiquid, meaning they couldn't be sold at market price. Bankman-Fried valued its stock at the fictitious price.
FTT tokens were reportedly used as collateral for loans, including FTX loans to Alameda. Close ties between FTX and Alameda made the FTT token harder or more expensive to use as collateral, reducing the risk to customer funds.
This use of an internal asset as collateral for loans between clandestinely related entities is similar to Enron's 1990s accounting fraud. These executives served 12 years in prison.
Alameda's margin liquidation exemption
Alameda Research had a "secret exemption" from FTX's liquidation and margin trading rules, according to legal filings by FTX's new CEO.
FTX, like other crypto platforms and some equity or commodity services, offered "margin" or loans for trades. These loans are usually collateralized, meaning borrowers put up other funds or assets. If a margin trade loses enough money, the exchange will sell the user's collateral to pay off the initial loan.
Keeping asset markets solvent requires liquidating bad margin positions. Exempting Alameda would give it huge advantages while exposing other FTX users to hidden risks. Alameda could have kept losing positions open while closing out competitors. Alameda could lose more on FTX than it could pay back, leaving a hole in customer funds.
The exemption is criminal in multiple ways. FTX was fraudulently marketed overall. Instead of a level playing field, there were many customers.
Above them all, with shotgun poised, was Alameda Research.
Alameda front-running FTX listings
Argus says there's circumstantial evidence that Alameda Research had insider knowledge of FTX's token listing plans. Alameda was able to buy large amounts of tokens before the listing and sell them after the price bump.
If true, these claims would be the most brazenly illegal of Alameda and FTX's alleged shenanigans. Even if the tokens aren't formally classified as securities, insider trading laws may apply.
In a similar case this year, an OpenSea employee was charged with wire fraud for allegedly insider trading. This employee faces 20 years in prison for front-running monkey JPEGs.
Huge loans to executives
Alameda Research reportedly lent FTX executives $4.1 billion, including massive personal loans. Bankman-Fried received $1 billion in personal loans and $2.3 billion for an entity he controlled, Paper Bird. Nishad Singh, director of engineering, was given $543 million, and FTX Digital Markets co-CEO Ryan Salame received $55 million.
FTX has more smoking guns than a Texas shooting range, but this one is the smoking bazooka – a sign of criminal intent. It's unclear how most of the personal loans were used, but liquidators will have to recoup the money.
The loans to Paper Bird were even more worrisome because they created another related third party to shuffle assets. Forbes speculates that some Paper Bird funds went to buy Binance's FTX stake, and Paper Bird committed hundreds of millions to outside investments.
FTX Inner Circle: Who's Who
That included many FTX-backed VC funds. Time will tell if this financial incest was criminal fraud. It fits Bankman-pattern Fried's of using secret flows, leverage, and funny money to inflate asset prices.
FTT or loan 'bailouts'
Also. As the crypto bear market continued in 2022, Bankman-Fried proposed bailouts for bankrupt crypto lenders BlockFi and Voyager Digital. CoinDesk was among those deceived, welcoming SBF as a J.P. Morgan-style sector backstop.
In a now-infamous interview with CNBC's "Squawk Box," Bankman-Fried referred to these decisions as bets that may or may not pay off.
But maybe not. Bloomberg's Matt Levine speculated that FTX backed BlockFi with FTT money. This Monopoly bailout may have been intended to hide FTX and Alameda liabilities that would have been exposed if BlockFi went bankrupt sooner. This ploy has no name, but it echoes other corporate frauds.
Secret bank purchase
Alameda Research invested $11.5 million in the tiny Farmington State Bank, doubling its net worth. As a non-U.S. entity and an investment firm, Alameda should have cleared regulatory hurdles before acquiring a U.S. bank.
In the context of FTX, the bank's stake becomes "ominous." Alameda and FTX could have done more shenanigans with bank control. Compare this to the Bank for Credit and Commerce International's failed attempts to buy U.S. banks. BCCI was even nefarious than FTX and wanted to buy U.S. banks to expand its money-laundering empire.
The mainstream's mistakes
These are complex and nuanced forms of fraud that echo traditional finance models. This obscurity helped Bankman-Fried masquerade as an honest player and likely kept coverage soft after the collapse.
Bankman-Fried had a scruffy, nerdy image, like Mark Zuckerberg and Adam Neumann. In interviews, he spoke nonsense about an industry full of jargon and complicated tech. Strategic donations and insincere ideological statements helped him gain political and social influence.
SBF' s'Effective' Altruism Blew Up FTX
Bankman-Fried has continued to muddy the waters with disingenuous letters, statements, interviews, and tweets since his con collapsed. He's tried to portray himself as a well-intentioned but naive kid who made some mistakes. This is a softer, more pernicious version of what Trump learned from mob lawyer Roy Cohn. Bankman-Fried doesn't "deny, deny, deny" but "confuse, evade, distort."
It's mostly worked. Kevin O'Leary, who plays an investor on "Shark Tank," repeats Bankman-SBF's counterfactuals. O'Leary called Bankman-Fried a "savant" and "probably one of the most accomplished crypto traders in the world" in a Nov. 27 interview with Business Insider, despite recent data indicating immense trading losses even when times were good.
O'Leary's status as an FTX investor and former paid spokesperson explains his continued affection for Bankman-Fried despite contradictory evidence. He's not the only one promoting Bankman-Fried. The disgraced son of two Stanford law professors will defend himself at Wednesday's DealBook Summit.
SBF's fraud and theft rival those of Bernie Madoff and Jho Low. Whether intentionally or through malign ineptitude, the fraud echoes Worldcom and Enron.
The Perverse Impacts of Anti-Money-Laundering
The principals in all of those scandals wound up either sentenced to prison or on the run from the law. Sam Bankman-Fried clearly deserves to share their fate.
Read the full article here.