


More on Productivity

Taher Batterywala
3 years ago
Do You Have Focus Issues? Use These 5 Simple Habits

Many can't concentrate. The first 20% of the day isn't optimized.
Elon Musk, Tony Robbins, and Bill Gates share something:
Morning Routines.
A repeatable morning ritual saves time.
The result?
Time for hobbies.
I'll discuss 5 easy morning routines you can use.
1. Stop pressing snooze
Waking up starts the day. You disrupt your routine by hitting snooze.
One sleep becomes three. Your morning routine gets derailed.
Fix it:
Hide your phone. This disables snooze and wakes you up.
Once awake, staying awake is 10x easier. Simple trick, big results.
2. Drink water
Chronic dehydration is common. Mostly urban, air-conditioned workers/residents.
2% cerebral dehydration causes short-term memory loss.
Dehydration shrinks brain cells.
Drink 3-4 liters of water daily to avoid this.
3. Improve your focus
How to focus better?
Meditation.
Improve your mood
Enhance your memory
increase mental clarity
Reduce blood pressure and stress
Headspace helps with the habit.
Here's a meditation guide.
Sit comfortably
Shut your eyes.
Concentrate on your breathing
Breathe in through your nose
Breathe out your mouth.
5 in, 5 out.
Repeat for 1 to 20 minutes.
Here's a beginner's video:
4. Workout
Exercise raises:
Mental Health
Effort levels
focus and memory
15-60 minutes of fun:
Exercise Lifting
Running
Walking
Stretching and yoga
This helps you now and later.
5. Keep a journal
You have countless thoughts daily. Many quietly steal your focus.
Here’s how to clear these:
Write for 5-10 minutes.
You'll gain 2x more mental clarity.
Recap
5 morning practices for 5x more productivity:
Say no to snoozing
Hydrate
Improve your focus
Exercise
Journaling
Conclusion
One step starts a thousand-mile journey. Try these easy yet effective behaviors if you have trouble concentrating or have too many thoughts.
Start with one of these behaviors, then add the others. Its astonishing results are instant.

Jari Roomer
3 years ago
5 ways to never run out of article ideas
“Perfectionism is the enemy of the idea muscle. " — James Altucher

Writer's block is a typical explanation for low output. Success requires productivity.
In four years of writing, I've never had writer's block. And you shouldn't care.
You'll never run out of content ideas if you follow a few tactics. No, I'm not overpromising.
Take Note of Ideas
Brains are strange machines. Blank when it's time to write. Idiot. Nothing. We get the best article ideas when we're away from our workstation.
In the shower
Driving
In our dreams
Walking
During dull chats
Meditating
In the gym
No accident. The best ideas come in the shower, in nature, or while exercising.
(Your workstation is the worst place for creativity.)
The brain has time and space to link 'dots' of information during rest. It's eureka! New idea.
If you're serious about writing, capture thoughts as they come.
Immediately write down a new thought. Capture it. Don't miss it. Your future self will thank you.
As a writer, entrepreneur, or creative, letting ideas slide is bad.
I recommend using Evernote, Notion, or your device's basic note-taking tool to capture article ideas.
It doesn't matter whatever app you use as long as you collect article ideas.
When you practice 'idea-capturing' enough, you'll have an unending list of article ideas when writer's block hits.
High-Quality Content
More books, films, Medium pieces, and Youtube videos I consume, the more I'm inspired to write.
What you eat shapes who you are.
Celebrity gossip and fear-mongering news won't help your writing. It won't help you write regularly.
Instead, read expert-written books. Watch documentaries to improve your worldview. Follow amazing people online.
Develop your 'idea muscle' Daily creativity takes practice. The more you exercise your 'idea muscles,' the easier it is to generate article ideas.
I've trained my 'concept muscle' using James Altucher's exercise.
Write 10 ideas daily.
Write ten book ideas every day if you're an author. Write down 10 business ideas per day if you're an entrepreneur. Write down 10 investing ideas per day.
Write 10 article ideas per day. You become a content machine.
It doesn't state you need ten amazing ideas. You don't need 10 ideas. Ten ideas, regardless of quality.
Like at the gym, reps are what matter. With each article idea, you gain creativity. Writer's block is no match for this workout.
Quit Perfectionism
Perfectionism is bad for writers. You'll have bad articles. You'll have bad ideas. OK. It's creative.
Writing success requires prolificacy. You can't have 'perfect' articles.
“Perfectionism is the enemy of the idea muscle. Perfectionism is your brain trying to protect you from harm.” — James Altucher
Vincent van Gogh painted 900 pieces. The Starry Night is the most famous.
Thomas Edison invented 1093 things, but not all were as important as the lightbulb or the first movie camera.
Mozart composed nearly 600 compositions, but only Serenade No13 became popular.
Always do your best. Perfectionism shouldn't stop you from working. Write! Publicize. Make. Even if imperfect.
Write Your Story
Living an interesting life gives you plenty to write about. If you travel a lot, share your stories or lessons learned.
Describe your business's successes and shortcomings.
Share your experiences with difficulties or addictions.
More experiences equal more writing material.
If you stay indoors, perusing social media, you won't be inspired to write.
Have fun. Travel. Strive. Build a business. Be bold. Live a life worth writing about, and you won't run out of material.

Deon Ashleigh
3 years ago
You can dominate your daily productivity with these 9 little-known Google Calendar tips.
Calendars are great unpaid employees.
After using Notion to organize my next three months' goals, my days were a mess.
I grew very chaotic afterward. I was overwhelmed, unsure of what to do, and wasting time attempting to plan the day after it had started.
Imagine if our skeletons were on the outside. Doesn’t work.
The goals were too big; I needed to break them into smaller chunks. But how?
Enters Google Calendar
RescueTime’s recommendations took me seven hours to make a daily planner. This epic narrative begins with a sheet of paper and concludes with a daily calendar that helps me focus and achieve more goals. Ain’t nobody got time for “what’s next?” all day.
Onward!
Return to the Paleolithic Era
Plan in writing.
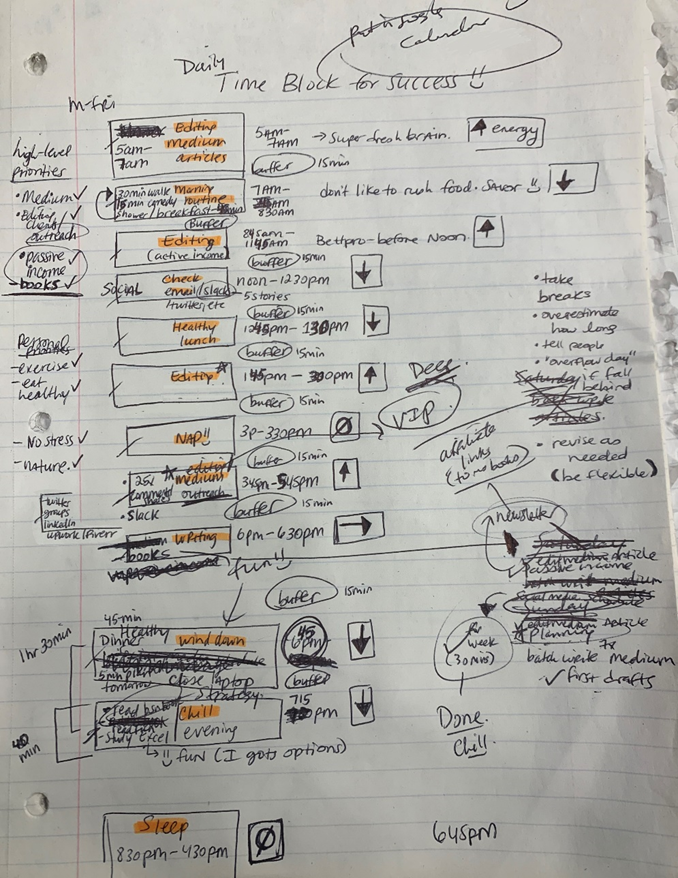
Not on the list, but it helped me plan my day. Physical writing boosts creativity and recall.
Find My Heart
i.e. prioritize
RescueTime suggested I prioritize before planning. Personal and business goals were proposed.
My top priorities are to exercise, eat healthily, spend time in nature, and avoid stress.
Priorities include writing and publishing Medium articles, conducting more freelance editing and Medium outreach, and writing/editing sci-fi books.
These eight things will help me feel accomplished every day.
Make a baby calendar.
Create daily calendar templates.
Make family, pleasure, etc. calendars.
Google Calendar instructions:
Other calendars
Press the “+” button
Create a new calendar
Create recurring events for each day
My calendar, without the template:
Empty, so I can fill it with vital tasks.
With the template:
My daily skeleton corresponds with my priorities. I've been overwhelmed for years because I lack daily, weekly, monthly, and yearly structure.
Google Calendars helps me reach my goals and focus my energy.
Get your colored pencils ready
Time-block color-coding.
Color labeling lets me quickly see what's happening. Maybe you are too.
Google Calendar instructions:
Determine which colors correspond to each time block.
When establishing new events, select a color.
Save
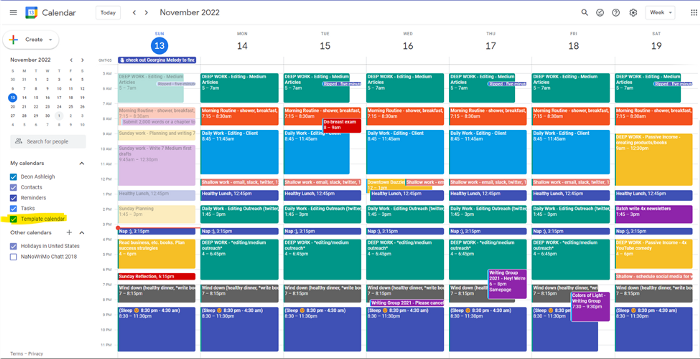
My calendar is color-coded as follows:
Yellow — passive income or other future-related activities
Red — important activities, like my monthly breast exam
Flamingo — shallow work, like emails, Twitter, etc.
Blue — all my favorite activities, like walking, watching comedy, napping, and sleeping. Oh, and eating.
Green — money-related events required for this adulting thing
Purple — writing-related stuff
Associating a time block with a color helps me stay focused. Less distractions mean faster work.
Open My Email
aka receive a daily email from Google Calendar.
Google Calendar sends a daily email feed of your calendars. I sent myself the template calendar in this email.
Google Calendar instructions:
Access settings
Select the calendar that you want to send (left side)
Go down the page to see more alerts
Under the daily agenda area, click Email.

Get in Touch With Your Red Bull Wings — Naturally
aka audit your energy levels.
My daily planner has arrows. These indicate how much energy each activity requires or how much I have.
Rightward arrow denotes medium energy.
I do my Medium and professional editing in the morning because it's energy-intensive.
Niharikaa Sodhi recommends morning Medium editing.
I’m a morning person. As long as I go to bed at a reasonable time, 5 a.m. is super wild GO-TIME. It’s like the world was just born, and I marvel at its wonderfulness.
Freelance editing lets me do what I want. An afternoon snooze will help me finish on time.
Ditch Schedule View
aka focus on the weekly view.
RescueTime advocated utilizing the weekly view of Google Calendar, so I switched.
When you launch the phone app or desktop calendar, a red line shows where you are in the day.
I'll follow the red line's instructions. My digital supervisor is easy to follow.
In the image above, it's almost 3 p.m., therefore the red line implies it's time to snooze.
I won't forget this block ;).
Reduce the Lighting
aka dim previous days.
This is another Google Calendar feature I didn't know about. Once the allotted time passes, the time block dims. This keeps me present.
Google Calendar instructions:
Access settings
remaining general
To view choices, click.
Check Diminish the glare of the past.
Bonus
Two additional RescueTimes hacks:
Maintain a space between tasks
I left 15 minutes between each time block to transition smoothly. This relates to my goal of less stress. If I set strict start and end times, I'll be stressed.
With a buffer, I can breathe, stroll around, and start the following time block fresh.
Find a time is related to the buffer.
This option allows you conclude small meetings five minutes early and longer ones ten. Before the next meeting, relax or go wild.
Decide on a backup day.
This productivity technique is amazing.
Spend this excess day catching up on work. It helps reduce tension and clutter.
That's all I can say about Google Calendar's functionality.
You might also like

Scott Hickmann
4 years ago
Welcome
Welcome to Integrity's Web3 community!

Frederick M. Hess
2 years ago
The Lessons of the Last Two Decades for Education Reform
My colleague Ilana Ovental and I examined pandemic media coverage of education at the end of last year. That analysis examined coverage changes. We tracked K-12 topic attention over the previous two decades using Lexis Nexis. See the results here.
I was struck by how cleanly the past two decades can be divided up into three (or three and a half) eras of school reform—a framing that can help us comprehend where we are and how we got here. In a time when epidemic, political unrest, frenetic news cycles, and culture war can make six months seem like a lifetime, it's worth pausing for context.
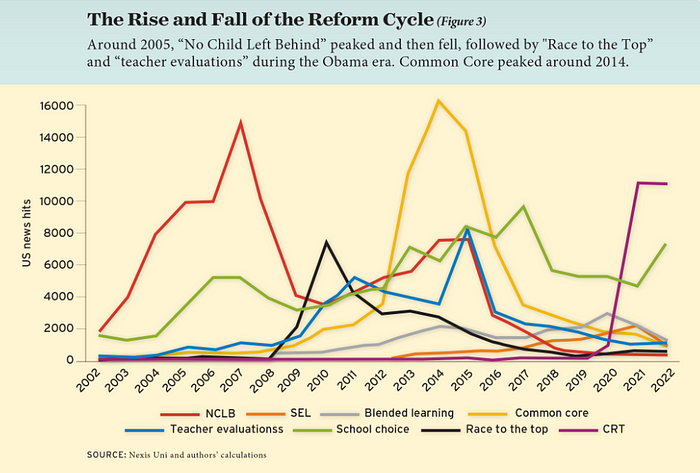
If you look at the peaks in the above graph, the 21st century looks to be divided into periods. The decade-long rise and fall of No Child Left Behind began during the Bush administration. In a few years, NCLB became the dominant K-12 framework. Advocates and financiers discussed achievement gaps and measured success with AYP.
NCLB collapsed under the weight of rigorous testing, high-stakes accountability, and a race to the bottom by the Obama years. Obama's Race to the Top garnered attention, but its most controversial component, the Common Core State Standards, rose quickly.
Academic standards replaced assessment and accountability. New math, fiction, and standards were hotly debated. Reformers and funders chanted worldwide benchmarking and systems interoperability.
We went from federally driven testing and accountability to government encouraged/subsidized/mandated (pick your verb) reading and math standardization. Last year, Checker Finn and I wrote The End of School Reform? The 2010s populist wave thwarted these objectives. The Tea Party, Occupy Wall Street, Black Lives Matter, and Trump/MAGA all attacked established institutions.
Consequently, once the Common Core fell, no alternative program emerged. Instead, school choice—the policy most aligned with populist suspicion of institutional power—reached a half-peak. This was less a case of choice erupting to prominence than of continuous growth in a vacuum. Even with Betsy DeVos' determined, controversial efforts, school choice received only half the media attention that NCLB and Common Core did at their heights.
Recently, culture clash-fueled attention to race-based curriculum and pedagogy has exploded (all playing out under the banner of critical race theory). This third, culture war-driven wave may not last as long as the other waves.
Even though I don't understand it, the move from slow-building policy debate to fast cultural confrontation over two decades is notable. I don't know if it's cyclical or permanent, or if it's about schooling, media, public discourse, or all three.
One final thought: After doing this work for decades, I've noticed how smoothly advocacy groups, associations, and other activists adapt to the zeitgeist. In 2007, mission statements focused on accomplishment disparities. Five years later, they promoted standardization. Language has changed again.
Part of this is unavoidable and healthy. Chasing currents can also make companies look unprincipled, promote scepticism, and keep them spinning the wheel. Bearing in mind that these tides ebb and flow may give educators, leaders, and activists more confidence to hold onto their values and pause when they feel compelled to follow the crowd.

Jared Heyman
3 years ago
The survival and demise of Y Combinator startups
I've written a lot about Y Combinator's success, but as any startup founder or investor knows, many startups fail.
Rebel Fund invests in the top 5-10% of new Y Combinator startups each year, so we focus on identifying and supporting the most promising technology startups in our ecosystem. Given the power law dynamic and asymmetric risk/return profile of venture capital, we worry more about our successes than our failures. Since the latter still counts, this essay will focus on the proportion of YC startups that fail.
Since YC's launch in 2005, the figure below shows the percentage of active, inactive, and public/acquired YC startups by batch.
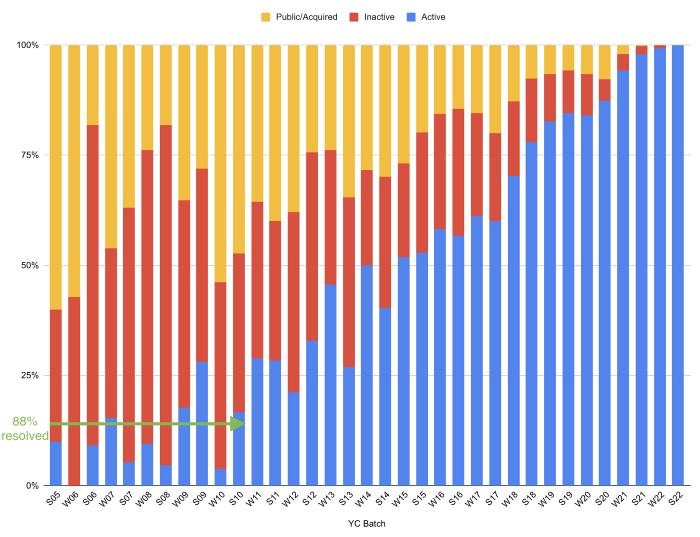
As more startups finish, the blue bars (active) decrease significantly. By 12 years, 88% of startups have closed or exited. Only 7% of startups reach resolution each year.
YC startups by status after 12 years:
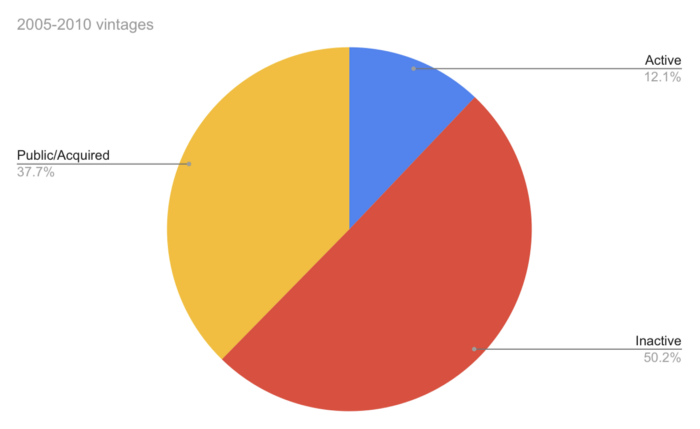
Half the startups have failed, over one-third have exited, and the rest are still operating.
In venture investing, it's said that failed investments show up before successful ones. This is true for YC startups, but only in their early years.
Below, we only present resolved companies from the first chart. Some companies fail soon after establishment, but after a few years, the inactive vs. public/acquired ratio stabilizes around 55:45. After a few years, a YC firm is roughly as likely to quit as fail, which is better than I imagined.
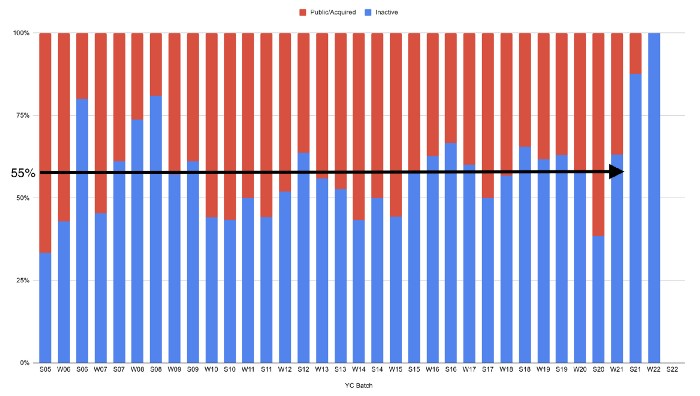
I prepared this post because Rebel investors regularly question me about YC startup failure rates and how long it takes for them to exit or shut down.
Early-stage venture investors can overlook it because 100x investments matter more than 0x investments.
YC founders can ignore it because it shouldn't matter if many of their peers succeed or fail ;)