



More on Productivity

Dr Mehmet Yildiz
3 years ago
How I train my brain daily for clarity and productivity.
I use a conceptual and practical system I developed decades ago as an example.

Since childhood, I've been interested in the brain-mind connection, so I developed a system using scientific breakthroughs, experiments, and the experiences of successful people in my circles.
This story provides a high-level overview of a custom system to inform and inspire readers. Creating a mind gym was one of my best personal and professional investments.
Such a complex system may not be possible for everyone or appear luxurious at first. However, the process and approach may help you find more accessible and viable solutions.
Visualizing the brain as a muscle, I learned to stimulate it with physical and mental exercises, applying a new mindset and behavioral changes.
My methods and practices may not work for others because we're all different. I focus on the approach's principles and highlights so you can create your own program.
Some create a conceptual and practical system intuitively, and others intellectually. Both worked. I see intellect and intuition as higher selves.
The mental tools I introduce are based on lifestyle changes and can be personalized by anyone, barring physical constraints or underlying health conditions.
Some people can't meditate despite wanting to due to mental constraints. This story lacks exceptions.
People's systems may vary. Many have used my tools successfully. All have scientific backing because their benefits attracted scientists. None are unethical or controversial.
My focus is cognition, which is the neocortex's ability. These practices and tools can affect the limbic and reptilian brain regions.
A previous article discussed brain health's biological aspects. This article focuses on psychology.
Thinking, learning, and remembering are cognitive abilities. Cognitive abilities determine our health and performance.
Cognitive health is the ability to think, concentrate, learn, and remember. Cognitive performance boosting involves various tools and processes. My system and protocols address cognitive health and performance.
As a biological organ, the brain's abilities decline with age, especially if not used regularly. Older people have more neurodegenerative disorders like dementia.
As aging is inevitable, I focus on creating cognitive reserves to remain mentally functional as we age and face mental decline or cognitive impairment.
My protocols focus on neurogenesis, or brain growth and maintenance. Neurons and connections can grow at any age.
Metacognition refers to knowing our cognitive abilities, like thinking about thinking and learning how to learn.
In the following sections, I provide an overview of my system, mental tools, and protocols.
This system summarizes my 50-year career. Some may find it too abstract, so I give examples.
First, explain the system. Section 2 introduces activities. Third, how to measure and maintain mental growth.
1 — Developed a practical mental gym.
The mental gym is a metaphor for the physical fitness gym to improve our mental muscles.
This concept covers brain and mind functionality. Integrated biological and psychological components.
I'll describe my mental gym so my other points make sense. My mental gym has physical and mental tools.
Mindfulness, meditation, visualization, self-conversations, breathing exercises, expressive writing, working in a flow state, reading, music, dance, isometric training, barefoot walking, cold/heat exposure, CBT, and social engagements are regular tools.
Dancing, walking, and thermogenesis are body-related tools. As the brain is part of the body and houses the mind, these tools can affect mental abilities such as attention, focus, memory, task switching, and problem-solving.
Different people may like different tools. I chose these tools based on my needs, goals, and lifestyle. They're just examples. You can choose tools that fit your goals and personality.
2 — Performed tasks regularly.
These tools gave me clarity. They became daily hobbies. Some I did alone, others with others.
Some examples: I meditate daily. Even though my overactive mind made daily meditation difficult at first, I now enjoy it. Meditation three times a day sharpens my mind.
Self-talk is used for self-therapy and creativity. Self-talk was initially difficult, but neurogenesis rewired my brain to make it a habit.
Cold showers, warm baths with Epsom salts, fasting, barefoot walks on the beach or grass, dancing, calisthenics, trampoline hopping, and breathing exercises increase my mental clarity, creativity, and productivity.
These exercises can increase BDNF, which promotes nervous system growth. They improve mental capacity and performance by increasing blood flow and brain oxygenation.
I use weekly and occasional activities like dry saunas, talking with others, and community activities.
These activities stimulate the brain and mind, improving performance and cognitive capacity.
3 — Measured progress, set growth goals.
Measuring progress helps us stay on track. Without data, it's hard to stay motivated. When we face inevitable setbacks, we may abandon our dreams.
I created a daily checklist for a spreadsheet with macros. I tracked how often and long I did each activity.
I measured my progress objectively and subjectively. In the progress spreadsheet, I noted my meditation hours and subjective feelings.
In another column, I used good, moderate, and excellent to get qualitative data. It took time and effort. Later, I started benefiting from this automated structure.
Creating a page for each activity, such as meditation, self-talk, cold showers, walking, expressive writing, personal interactions, etc., gave me empirical data I could analyze, modify, and graph to show progress.
Colored charts showed each area's strengths and weaknesses.
Strengths motivate me to continue them. Identifying weaknesses helped me improve them.
As the system matured, data recording became a habit and took less time. I saw the result immediately because I automated the charts when I entered daily data. Early time investment paid off later.
Mind Gym Benefits, Effective Use, and Progress Measuring
This concept helped me move from comfort to risk. I accept things as they are.
Turnarounds were made. I stopped feeling "Fight-Flight-Freeze" and maintained self-control.
I tamed my overactive amygdala by strengthening my brain. Stress and anxiety decreased. With these shifts, I accepted criticism and turned envy into admiration. Clarity improved.
When the cognitive part of the brain became stronger and the primitive part was tamed, managing thoughts and emotions became easier. My AQ increased. I learned to tolerate people, physical, mental, and emotional obstacles.
Accessing vast information sources in my subconscious mind through an improved RAS allowed me to easily tap into my higher self and recognize flaws in my lower self.
Summary
The brain loves patterns and routines, so habits help. Observing, developing, and monitoring habits mindfully can be beneficial. Mindfulness helps us achieve this goal systematically.
As body and mind are connected, we must consider both when building habits. Consistent and joyful practices can strengthen neurons and neural connections.
Habits help us accomplish more with less effort. Regularly using mental tools and processes can improve our cognitive health and performance as we age.
Creating daily habits to improve cognitive abilities can sharpen our minds and boost our well-being.
Some apps monitor our activities and behavior to help build habits. If you can't replicate my system, try these apps. Some smartwatches and fitness devices include them.
Set aside time each day for mental activities you enjoy. Regular scheduling and practice can strengthen brain regions and form habits. Once you form habits, tasks become easy.
Improving our minds is a lifelong journey. It's easier and more sustainable to increase our efforts daily, weekly, monthly, or annually.
Despite life's ups and downs, many want to remain calm and cheerful.
This valuable skill is unrelated to wealth or fame. It's about our mindset, fueled by our biological and psychological needs.
Here are some lessons I've learned about staying calm and composed despite challenges and setbacks.
1 — Tranquillity starts with observing thoughts and feelings.
2 — Clear the mental clutter and emotional entanglements with conscious breathing and gentle movements.
3 — Accept situations and events as they are with no resistance.
4 — Self-love can lead to loving others and increasing compassion.
5 — Count your blessings and cultivate gratitude.
Clear thinking can bring joy and satisfaction. It's a privilege to wake up with a healthy body and clear mind, ready to connect with others and serve them.
Thank you for reading my perspectives. I wish you a healthy and happy life.

Darshak Rana
3 years ago
17 Google Secrets 99 Percent of People Don't Know
What can't Google do?
Seriously, nothing! Google rocks.
Google is a major player in online tools and services. We use it for everything, from research to entertainment.
Did I say entertain yourself?
Yes, with so many features and options, it can be difficult to fully utilize Google.
#1. Drive Google Mad
You can make Google's homepage dance if you want to be silly.
Just type “Google Gravity” into Google.com. Then select I'm lucky.
See the page unstick before your eyes!
#2 Play With Google Image
Google isn't just for work.
Then have fun with it!
You can play games right in your search results. When you need a break, google “Solitaire” or “Tic Tac Toe”.
#3. Do a Barrel Roll
Need a little more excitement in your life? Want to see Google dance?
Type “Do a barrel roll” into the Google search bar.
Then relax and watch your screen do a 360.
#4 No Internet? No issue!
This is a fun trick to use when you have no internet.
If your browser shows a “No Internet” page, simply press Space.
Boom!
We have dinosaurs! Now use arrow keys to save your pixelated T-Rex from extinction.
#5 Google Can Help
Play this Google coin flip game to see if you're lucky.
Enter “Flip a coin” into the search engine.
You'll see a coin flipping animation. If you get heads or tails, click it.
#6. Think with Google
My favorite Google find so far is the “Think with Google” website.
Think with Google is a website that offers marketing insights, research, and case studies.
I highly recommend it to entrepreneurs, small business owners, and anyone interested in online marketing.
#7. Google Can Read Images!
This is a cool Google trick that few know about.
You can search for images by keyword or upload your own by clicking the camera icon on Google Images.
Google will then show you all of its similar images.
Caution: You should be fine with your uploaded images being public.
#8. Modify the Google Logo!
Clicking on the “I'm Feeling Lucky” button on Google.com takes you to a random Google Doodle.
Each year, Google creates a Doodle to commemorate holidays, anniversaries, and other occasions.
#9. What is my IP?
Simply type “What is my IP” into Google to find out.
Your IP address will appear on the results page.
#10. Send a Self-Destructing Email With Gmail,
Create a new message in Gmail. Find an icon that resembles a lock and a clock near the SEND button. That's where the Confidential Mode is.
By clicking it, you can set an expiration date for your email. Expiring emails are automatically deleted from both your and the recipient's inbox.
#11. Blink, Google Blink!
This is a unique Google trick.
Type “blink HTML” into Google. The words “blink HTML” will appear and then disappear.
The text is displayed for a split second before being deleted.
To make this work, Google reads the HTML code and executes the “blink” command.
#12. The Answer To Everything
This is for all Douglas Adams fans.
The answer to life, the universe, and everything is 42, according to Google.
An allusion to Douglas Adams' Hitchhiker's Guide to the Galaxy, in which Ford Prefect seeks to understand life, the universe, and everything.
#13. Google in 1998
It's a blast!
Type “Google in 1998” into Google. "I'm feeling lucky"
You'll be taken to an old-school Google homepage.
It's a nostalgic trip for long-time Google users.
#14. Scholarships and Internships
Google can help you find college funding!
Type “scholarships” or “internships” into Google.
The number of results will surprise you.
#15. OK, Google. Dice!
To roll a die, simply type “Roll a die” into Google.
On the results page is a virtual dice that you can click to roll.
#16. Google has secret codes!
Hit the nine squares on the right side of your Google homepage to go to My Account. Then Personal Info.
You can add your favorite language to the “General preferences for the web” tab.
#17. Google Terminal
You can feel like a true hacker.
Just type “Google Terminal” into Google.com. "I'm feeling lucky"
Voila~!
You'll be taken to an old-school computer terminal-style page.
You can then type commands to see what happens.
Have you tried any of these activities? Tell me in the comments.
Read full article here

Jumanne Rajabu Mtambalike
3 years ago
10 Years of Trying to Manage Time and Improve My Productivity.
I've spent the last 10 years of my career mastering time management. I've tried different approaches and followed multiple people and sources. My knowledge is summarized.
Great people, including entrepreneurs, master time management. I learned time management in college. I was studying Computer Science and Finance and leading Tanzanian students in Bangalore, India. I had 24 hours per day to do this and enjoy campus. I graduated and received several awards. I've learned to maximize my time. These tips and tools help me finish quickly.
Eisenhower-Box
I don't remember when I read the article. James Clear, one of my favorite bloggers, introduced me to the Eisenhower Box, which I've used for years. Eliminate waste to master time management. By grouping your activities by importance and urgency, the tool helps you prioritize what matters and drop what doesn't. If it's urgent, do it. Delegate if it's urgent but not necessary. If it's important but not urgent, reschedule it; otherwise, drop it. I integrated the tool with Trello to manage my daily tasks. Since 2007, I've done this.

James Clear's article mentions Eisenhower Box.
Essentialism rules
Greg McKeown's book Essentialism introduced me to disciplined pursuit of less. I once wrote about this. I wasn't sure what my career's real opportunities and distractions were. A non-essentialist thinks everything is essential; you want to be everything to everyone, and your life lacks satisfaction. Poor time management starts it all. Reading and applying this book will change your life.

Essential vs non-essential
Life Calendar
Most of us make corporate calendars. Peter Njonjo, founder of Twiga Foods, said he manages time by putting life activities in his core calendars. It includes family retreats, weddings, and other events. He joked that his wife always complained to him to avoid becoming a calendar item. It's key. "Time Masters" manages life's four burners, not just work and corporate life. There's no "work-life balance"; it's life.

Health, Family, Work, and Friends.
The Brutal No
In a culture where people want to look good, saying "NO" to a favor request seems rude. In reality, the crime is breaking a promise. "Time Masters" have mastered "NO". More "YES" means less time, and more "NO" means more time for tasks and priorities. Brutal No doesn't mean being mean to your coworkers; it means explaining kindly and professionally that you have other priorities.
To-Do vs. MITs
Most people are productive with a routine to-do list. You can't be effective by just checking boxes on a To-do list. When was the last time you completed all of your daily tasks? Never. You must replace the to-do list with Most Important Tasks (MITs). MITs allow you to focus on the most important tasks on your list. You feel progress and accomplishment when you finish these tasks. MITs don't include ad-hoc emails, meetings, etc.
Journal Mapped
Most people don't journal or plan their day in the developing South. I've learned to plan my day in my journal over time. I have multiple sections on one page: MITs (things I want to accomplish that day), Other Activities (stuff I can postpone), Life (health, faith, and family issues), and Pop-Ups (things that just pop up). I leave the next page blank for notes. I reflected on the blocks to identify areas to improve the next day. You will have bad days, but at least you'll realize it was due to poor time management.
Buy time/delegate
Time or money? When you make enough money, you lose time to make more. The smart buy "Time." I resisted buying other people's time for years. I regret not hiring an assistant sooner. Learn to buy time from others and pay for time-consuming tasks. Sometimes you think you're saving money by doing things yourself, but you're actually losing money.
This post is a summary. See the full post here.
You might also like
Muhammad Rahmatullah
3 years ago
The Pyramid of Coding Principles
A completely operating application requires many processes and technical challenges. Implementing coding standards can make apps right, work, and faster.
With years of experience working in software houses. Many client apps are scarcely maintained.
Why are these programs "barely maintainable"? If we're used to coding concepts, we can probably tell if an app is awful or good from its codebase.
This is how I coded much of my app.
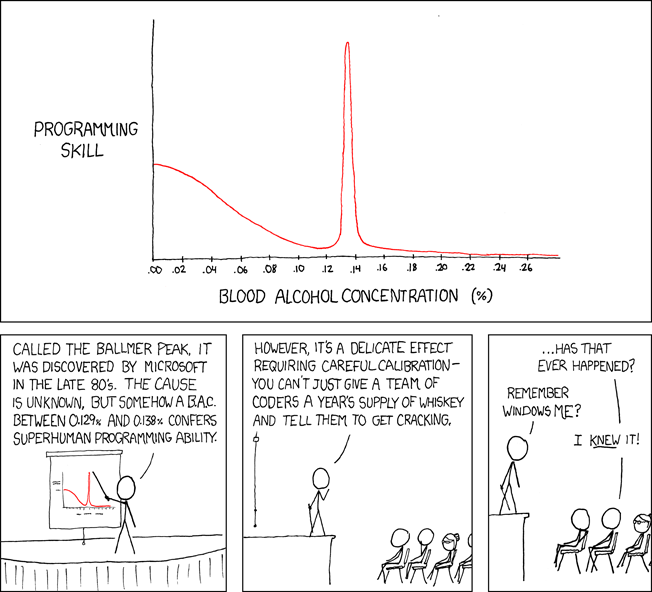
Make It Work
Before adopting any concept, make sure the apps are completely functional. Why have a fully maintained codebase if the app can't be used?
The user doesn't care if the app is created on a super server or uses the greatest coding practices. The user just cares if the program helps them.
After the application is working, we may implement coding principles.
You Aren’t Gonna Need It
As a junior software engineer, I kept unneeded code, components, comments, etc., thinking I'd need them later.
In reality, I never use that code for weeks or months.
First, we must remove useless code from our primary codebase. If you insist on keeping it because "you'll need it later," employ version control.
If we remove code from our codebase, we can quickly roll back or copy-paste the previous code without preserving it permanently.
The larger the codebase, the more maintenance required.
Keep It Simple Stupid
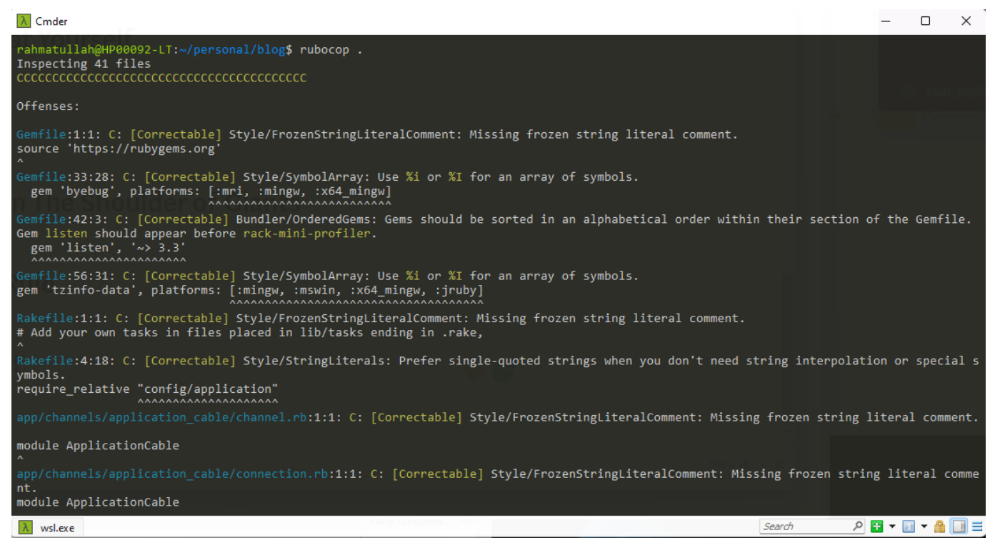
Indeed. Keep things simple.
Why complicate something if we can make it simpler?
Our code improvements should lessen the server load and be manageable by others.
If our code didn't pass those benchmarks, it's too convoluted and needs restructuring. Using an open-source code critic or code smell library, we can quickly rewrite the code.
Simpler codebases and processes utilize fewer server resources.
Don't Repeat Yourself
Have you ever needed an action or process before every action, such as ensuring the user is logged in before accessing user pages?
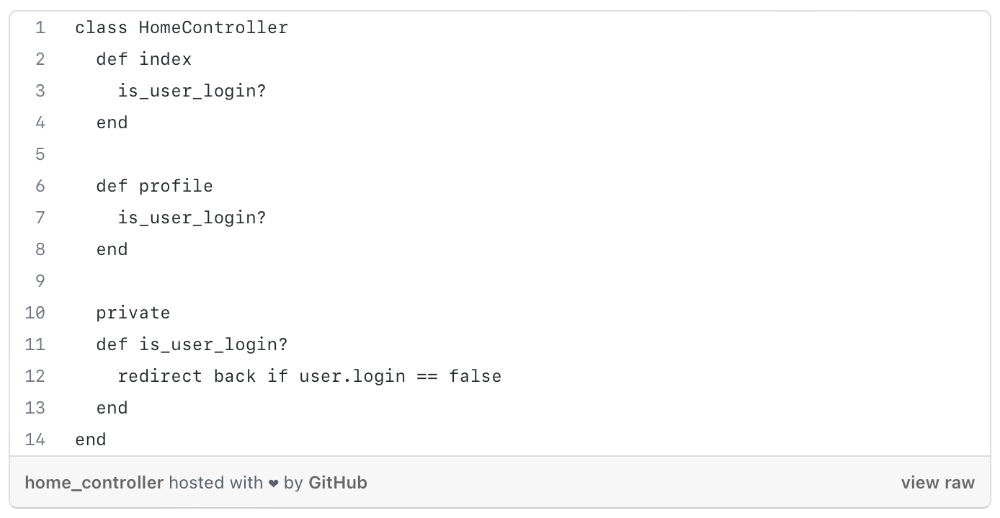
As you can see from the above code, I try to call is user login? in every controller action, and it should be optimized, because if we need to rename the method or change the logic, etc. We can improve this method's efficiency.
We can write a constructor/middleware/before action that calls is_user_login?
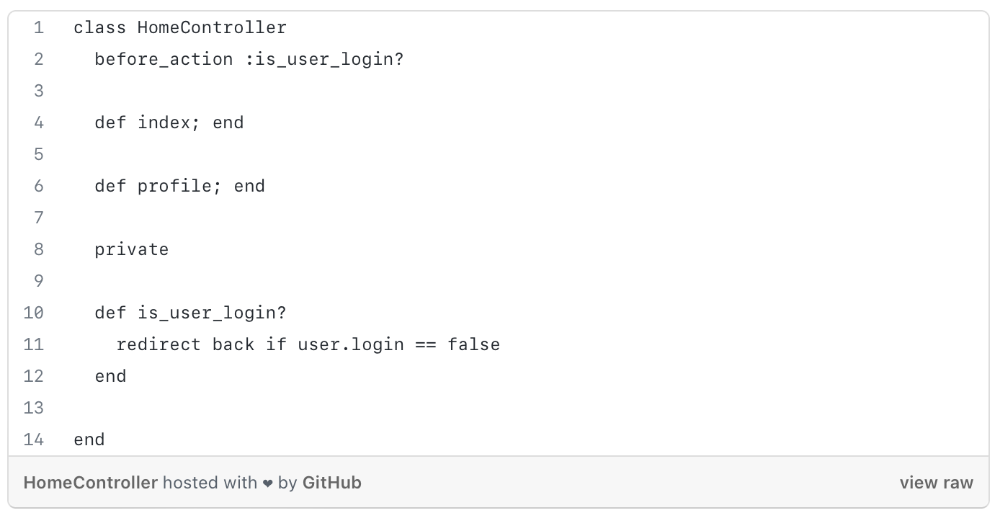
The code is more maintainable and readable after refactoring.
Each programming language or framework handles this issue differently, so be adaptable.
Clean Code
Clean code is a broad notion that you've probably heard of before.
When creating a function, method, module, or variable name, the first rule of clean code is to be precise and simple.
The name should express its value or logic as a whole, and follow code rules because every programming language is distinct.
If you want to learn more about this topic, I recommend reading https://www.amazon.com/Clean-Code-Handbook-Software-Craftsmanship/dp/0132350882.
Standing On The Shoulder of Giants
Use industry standards and mature technologies, not your own(s).
There are several resources that explain how to build boilerplate code with tools, how to code with best practices, etc.
I propose following current conventions, best practices, and standardization since we shouldn't innovate on top of them until it gives us a competitive edge.
Boy Scout Rule
What reduces programmers' productivity?
When we have to maintain or build a project with messy code, our productivity decreases.
Having to cope with sloppy code will slow us down (shame of us).
How to cope? Uncle Bob's book says, "Always leave the campground cleaner than you found it."
When developing new features or maintaining current ones, we must improve our codebase. We can fix minor issues too. Renaming variables, deleting whitespace, standardizing indentation, etc.
Make It Fast
After making our code more maintainable, efficient, and understandable, we can speed up our app.
Whether it's database indexing, architecture, caching, etc.
A smart craftsman understands that refactoring takes time and it's preferable to balance all the principles simultaneously. Don't YAGNI phase 1.
Using these ideas in each iteration/milestone, while giving the bottom items less time/care.
You can check one of my articles for further information. https://medium.com/life-at-mekari/why-does-my-website-run-very-slowly-and-how-do-i-optimize-it-for-free-b21f8a2f0162

The Verge
4 years ago
Bored Ape Yacht Club creator raises $450 million at a $4 billion valuation.
Yuga Labs, owner of three of the biggest NFT brands on the market, announced today a $450 million funding round. The money will be used to create a media empire based on NFTs, starting with games and a metaverse project.
The team's Otherside metaverse project is an MMORPG meant to connect the larger NFT universe. They want to create “an interoperable world” that is “gamified” and “completely decentralized,” says Wylie Aronow, aka Gordon Goner, co-founder of Bored Ape Yacht Club. “We think the real Ready Player One experience will be player run.”
Just a few weeks ago, Yuga Labs announced the acquisition of CryptoPunks and Meebits from Larva Labs. The deal brought together three of the most valuable NFT collections, giving Yuga Labs more IP to work with when developing games and metaverses. Last week, ApeCoin was launched as a cryptocurrency that will be governed independently and used in Yuga Labs properties.
Otherside will be developed by “a few different game studios,” says Yuga Labs CEO Nicole Muniz. The company plans to create development tools that allow NFTs from other projects to work inside their world. “We're welcoming everyone into a walled garden.”
However, Yuga Labs believes that other companies are approaching metaverse projects incorrectly, allowing the startup to stand out. People won't bond spending time in a virtual space with nothing going on, says Yuga Labs co-founder Greg Solano, aka Gargamel. Instead, he says, people bond when forced to work together.
In order to avoid getting smacked, Solano advises making friends. “We don't think a Zoom chat and walking around saying ‘hi' creates a deep social experience.” Yuga Labs refused to provide a release date for Otherside. Later this year, a play-to-win game is planned.
The funding round was led by Andreessen Horowitz, a major investor in the Web3 space. It previously backed OpenSea and Coinbase. Animoca Brands, Coinbase, and MoonPay are among those who have invested. Andreessen Horowitz general partner Chris Lyons will join Yuga Labs' board. The Financial Times broke the story last month.
"META IS A DOMINANT DIGITAL EXPERIENCE PROVIDER IN A DYSTOPIAN FUTURE."
This emerging [Web3] ecosystem is important to me, as it is to companies like Meta,” Chris Dixon, head of Andreessen Horowitz's crypto arm, tells The Verge. “In a dystopian future, Meta is the dominant digital experience provider, and it controls all the money and power.” (Andreessen Horowitz co-founder Marc Andreessen sits on Meta's board and invested early in Facebook.)
Yuga Labs has been profitable so far. According to a leaked pitch deck, the company made $137 million last year, primarily from its NFT brands, with a 95% profit margin. (Yuga Labs declined to comment on deck figures.)
But the company has built little so far. According to OpenSea data, it has only released one game for a limited time. That means Yuga Labs gets hundreds of millions of dollars to build a gaming company from scratch, based on a hugely lucrative art project.
Investors fund Yuga Labs based on its success. That's what they did, says Dixon, “they created a culture phenomenon”. But ultimately, the company is betting on the same thing that so many others are: that a metaverse project will be the next big thing. Now they must construct it.

Darius Foroux
3 years ago
My financial life was changed by a single, straightforward mental model.
Prioritize big-ticket purchases
I've made several spending blunders. I get sick thinking about how much money I spent.
My financial mental model was poor back then.
Stoicism and mindfulness keep me from attaching to those feelings. It still hurts.
Until four or five years ago, I bought a new winter jacket every year.
Ten years ago, I spent twice as much. Now that I have a fantastic, warm winter parka, I don't even consider acquiring another one. No more spending. I'm not looking for jackets either.
Saving time and money by spending well is my thinking paradigm.
The philosophy is expressed in most languages. Cheap is expensive in the Netherlands. This applies beyond shopping.
In this essay, I will offer three examples of how this mental paradigm transformed my financial life.
Publishing books
In 2015, I presented and positioned my first book poorly.
I called the book Huge Life Success and made a funny Canva cover in 30 minutes. This:

That looks nothing like my present books. No logo or style. The book felt amateurish.
The book started bothering me a few weeks after publication. The advice was good, but it didn't appear professional. I studied the book business extensively.
I created a style for all my designs. Branding. Win Your Inner Wars was reissued a year later.
Title, cover, and description changed. Rearranging the chapters improved readability.
Seven years later, the book sells hundreds of copies a month. That taught me a lot.
Rushing to finish a project is enticing. Send it and move forward.
Avoid rushing everything. Relax. Develop your projects. Perform well. Perform the job well.
My first novel was underfunded and underworked. A bad book arrived. I then invested time and money in writing the greatest book I could.
That book still sells.
Traveling
I hate travel. Airports, flights, trains, and lines irritate me.
But, I enjoy traveling to beautiful areas.
I do it strangely. I make up travel rules. I never go to airports in summer. I hate being near airports on holidays. Unworthy.
No vacation packages for me. Those airline packages with a flight, shuttle, and hotel. I've had enough.
I try to avoid crowds and popular spots. July Paris? Nuts and bolts, please. Christmas in NYC? No, please keep me sane.
I fly business class behind. I accept upgrades upon check-in. I prefer driving. I drove from the Netherlands to southern Spain.
Thankfully, no lines. What if travel costs more? Thus? I enjoy it from the start. I start traveling then.
I rarely travel since I'm so difficult. One great excursion beats several average ones.
Personal effectiveness
New apps, tools, and strategies intrigue most productivity professionals.
No.
I researched years ago. I spent years investigating productivity in university.
I bought books, courses, applications, and tools. It was expensive and time-consuming.
Im finished. Productivity no longer costs me time or money. OK. I worked on it once and now follow my strategy.
I avoid new programs and systems. My stuff works. Why change winners?
Spending wisely saves time and money.
Spending wisely means spending once. Many people ignore productivity. It's understudied. No classes.
Some assume reading a few articles or a book is enough. Productivity is personal. You need a personal system.
Time invested is one-time. You can trust your system for life once you find it.
Concentrate on the expensive choices.
Life's short. Saving money quickly is enticing.
Spend less on groceries today. True. That won't fix your finances.
Adopt a lifestyle that makes you affluent over time. Consider major choices.
Are they causing long-term poverty? Are you richer?
Leasing cars comes to mind. The automobile costs a fortune today. The premium could accomplish a million nice things.
Focusing on important decisions makes life easier. Consider your future. You want to improve next year.